








The research Val programming language uses value-oriented programming. Lucian Radu Teodorescu explores this paradigm.
Robert C. Martin argues that we’ve probably invented all possible programming languages [Martin11]. There are two dimensions we need to analyse programming languages by: syntax and semantic class. In terms of syntax, we’ve experimented with just about everything; we’ve probably seen all types of syntax we can have.1 If we look at the semantic class of a programming language – i.e., the paradigm that the language emphasizes – we don’t have too many choices.
The approach that Robert C. Martin has on semantic classes is particularly interesting. He argues that a programming paradigm is best characterised by what it removes, not by what it adds; for example, structured programming is the paradigm that removes gotos from the language, constraining the direct transfer of control, which leads to programs that are easier to reason about. Imposing constraints on the possible set of programs that can be expressed in a language adds discipline to the language and can improve the language.
In this article, we will build on this idea and show that we haven’t yet reached the end of the stack with the things we can remove from languages. We look at value-oriented programming, a programming paradigm that the Val programming language [Val] proposes, and how this paradigm can improve safety, local reasoning, and the act of programming.
Programming paradigms and their constraints
Let’s start by looking at how Robert C. Martin describes mainstream paradigms in terms of their restrictions.2
Before doing that, let us issue a warning to the reader and soften some claims we will make. Whenever we say that a language restricts the use of a feature, we don’t actually mean that the language completely forbids it; it’s just that there is an overall tendency not to use that feature, even if the language allows it (directly or indirectly). In practice, languages don’t strictly follow a single paradigm. Moreover, the idea of a programming paradigm is an abstraction that omits plenty of details; we can’t have a clear-cut distinction between languages just by looking at their programming paradigms.
Modular programming is a paradigm that imposes constraints on the source code file size. The idea is to disallow/discourage putting all the source code of a program into one single file. One can have the same reasoning applied to the size of functions. Doing this will enable us, the readers of the programs, to understand the code more easily; we don’t have to fit the entire codebase in our head, we can focus on smaller parts.
Structured programming can be seen as a discipline imposed on direct transfer of control. We don’t use goto instructions, but rather construct all our programs of sequence, selection, or iterations. This allows us to easily follow the flow of the program, and manually prove the correctness of the code (when applicable).3 Structured programming also allows (to some degree) local reasoning about the code; this is something of great interest for the purpose of this article.
Object-oriented programming is a paradigm that adds restrictions on the use of pointers to functions and indirect transfer of control. In languages like C, to achieve polymorphic behaviour, one would typically use function pointers. In OOP, one would hide the use of function pointers inside virtual tables, which would be implementation details for class inheritance. This will make polymorphism easier to use, safer (fewer needs for casts) and it also allows us to easily implement dependency inversion. In turn, dependency inversion allows us to have loose coupling between our modules, making the code easier to reason about.
Functional programming can be thought of as a paradigm that imposes discipline on assignment of variables. If the assignment is not allowed, all values are immutable, which leads to function purity. Function purity allows easier reasoning about the functions (i.e., function results depend solely on their input arguments), improves safety, allows a set of optimisations that are not typically available with impure functions (removing unneeded function calls, adding memoisation, reordering of function calls, etc.) and allows code to be automatically parallelised.
We can see a pattern here: we restrict the ability to write certain types of programs, we get some guarantees back from the language, and these guarantees can help us write better programs. Removal of features can be beneficial. To make a parallel, this is similar to governments that make laws to prevent certain (unethical) things to happen, but the removal of something that was previously allowed will make the society a better place.
In general, switching from one programming paradigm to another is hard, as we have to change our mental model for reasoning about code; things that are common practice in one paradigm may be restricted in another. Both the strategies and the patterns that we use must change. That is why I prefer the syntagm programming paradigm rather than semantic class when discussing these categories of programming languages.
Before looking at what restrictions the value-oriented programming paradigm instills, let’s first look at the main benefits of its restrictions: safety and local reasoning.
Safety in programming languages
There is a lot of confusion around the word safety in the context of programming languages, so I will spend some time to define it for this article. I will follow the line of thought from Sean Parent [Parent22].
All programs consist of operations/commands; we will represent such an operation as C. Following Hoare formalism [Hoare69], we can associate preconditions (noted as P) and postconditions (noted as Q) to these operations. Thus, the programs can be represented as sets of triplets of the form {P}C{Q}. For a correct program, in the absence of any errors, for all operations in the program, if the preconditions P hold, then, after executing C, the postconditions Q will also hold.
For example, in C++, if i is a variable of type int, then for the operation i++ we can say that the precondition is that i is not the maximum integer value and that the postcondition is that the new value of i is one greater than its initial value.
Let us look at all the possible cases there can be when we execute the operation in {P}C{Q} (see Table 1).
|
Possible scenarios when executing operations
|
||||||||
| Table 1 |
If all the operations in a program are in the first scenario (i.e., both preconditions and postcondition hold) then we say the program is well-formed and correct. Typically, it is impossible for programming languages to guarantee that all the code expressible in the language falls under this scenario.
The second scenario lays the emphasis on correctness in the presence of errors.4 The program accepts the fact that there might be errors that can lead to failure to satisfy postconditions for all operations, but it’s important for these errors to be handled correctly. For example, it may be impossible for a program to make a network call to a server if the network cable is unplugged; if that is correctly treated as an error, the program is correct (assuming that everything else is also treated appropriately). It is outside the scope of this article to delve into what it means to have correct error reporting, but this is not something hard to do (see [Parent22] for details). The bottom line is that error handling is the key to program correctness.
The last case is the one in which we are trying to execute an operation, but the preconditions don’t hold. This case is about the safety of the language. The only way in which preconditions may fail is when the program is invalid (i.e. there is a bug); so safety in a programming language concerns its response to invalid programs.
We call an operation safe if it cannot lead to undefined behaviour, directly or indirectly. If we have an operation that may corrupt memory, it can lead to crashes while executing the operation, or the program may crash at any later point, or the program may execute the code of any other arbitrary program, or the program may continue to function normally — the behaviour is undefined, so that operation is unsafe.
We call an operation strongly safe if the program terminates when executing it if the preconditions of the operation don’t hold. That is, programs consisting of strongly safe operations will catch programming failures and report them as fast as they can.
Operations that are safe but not strongly safe may result in unspecified behaviour. The operation can result in invalid values or can execute infinite loops. For example, the implementation of a square root function that is just safe can produce invalid values for negative numbers or can loop forever. Unlike undefined behaviour, though, unspecified behaviour is bounded by the normal rules of the language: no matter what else happens, the same program is still executing when that behaviour completes.
Ideally, we want all our programs to be strongly safe; but, unfortunately, strong safety is much harder to achieve than simple safety, because safety is a transitive property, while strong safety is not. An operation cannot contain undefined behaviour if it consists of a series of operations that cannot have undefined behaviour, which makes safety transitive. On the other hand, we can violate the preconditions of an operation without violating any of the preconditions of the operations it consists of.
The non-transitivity of strong safety is illustrated by the C++ code in Listing 1. In this example, all the operations are safe, thus calling floorSqrt cannot lead to undefined behaviour. We have a precondition that the given argument must be positive. But passing a negative number to this function will not invalidate the preconditions of any operation in the function.5 All the operations inside the function have their preconditions hold, but overall, the precondition doesn’t hold. In this case, passing a negative value as an argument can led to an infinite loop.
// Precondition: x >= 0
unsigned int floorSqrt(int x) {
if (x == 0 || x == 1)
return x;
unsigned int i = 1;
unsigned int result = 1;
while (result <= x) {
i++;
result = i*i;
}
return i-1;
}
|
| Listing 1 |
To conclude, strong safety is hard to achieve systematically, but we can achieve safety systematically. A programming language should aim at allowing only safe programs (unless explicitly overridden by the programmer).
To become safe, a language must add restrictions on the operations that can lead to undefined behaviour. Operations that lead to undefined behaviour in C++ are the ones that contain: memory safety violations (spatial and temporal), strict aliasing violations, integer overflows, alignment violations, data races, etc.
Locally and globally detectable undefined behaviour
Undefined behaviour can be of two types, depending on the amount of code we need to inspect in order to detect it:6
- Locally detectable, if we can detect it by analysing the operation in question, or surrounding code. Examples: integer overflow, alignment violations, null-pointer dereference, etc.
- Globally detectable, if we need to analyse the whole program to detect safety issues. Examples: most memory safety violations, data races, etc.
Locally detectable undefined behaviour can be easily fixed in a programming language. The language can insert special code to detect violations and deal with them. Globally detectable undefined behaviour is trickier to deal with because it cannot be easily detected. In an unsafe language, one needs a certain discipline to ensure that this kind of undefined behaviour cannot occur.
Listing 2 shows a C++ function that, at first glance, seems perfectly fine. But, on the caller side, we use the function in a way that will cause undefined behaviour. The push_back call might need to reallocate memory, move all the objects contained in the vector and might invalidate all the pointers to the original objects; if the given object is part of the original vector memory, then we would be accessing an invalid object.
void my_push_back(vector<MyObj>& dest,
const MyObj& obj) {
dest.push_back(MyObj{});
dest.back().copy_name(obj);
}
// caller:
vector<MyObj> vec = generate_my_vector();
my_push_back(vec, vec[0]);
|
| Listing 2 |
This is clearly a bug and it cannot be detected only by looking at the function that has the undefined behaviour. We need to also look at all the possible ways this function is called.
Listing 3 shows another case in which we access invalid memory. Here, in a similar way, we take a string_view object from an object that is part of our vector. The ownership of the actual string data belongs to the Person object, which belongs to the vector. But, while utilising the string_view object we are changing the vector, possibly deleting the underlying object. Invalid memory access is expected.
void remove_by_name(vector<Person>& persons,
string_view name) {
std::erase(persons.begin(), persons.end(),
name); // C++20
}
// caller
const Person& to_fire =
worst_performer(employees);
remove_by_name(employees, to_fire.name());
|
| Listing 3 |
Listing 4 shows slightly strange code: we indirectly change the content of a container while traversing the container. While this example may be somehow contrived, one can find it in large code-bases under different forms. We are trying to access an object with some predicate, and because of the complexity of the code we are unaware of the fact that the predicate may actually change the original object.
vector<MyObj> objects;
bool my_pred(const MyObj& obj) {
if (obj.is_invalid() && !objects.empty()
&& objects.front() == obj) {
objects.erase(objects.begin())
}
return obj.can_be_selected();
}
auto it = find_if(objects.begin(), objects.end(),
my_pred);
|
| Listing 4 |
All these examples have a common problem: looking locally at the code, we are assuming that objects we are operating with have certain properties, without realising that the codebase will indirectly change those properties. We might assume that a reference will point to a valid object, that the object referenced by a constant reference will not change or that the object, if it’s in a valid state, will remain in that state. All these assumptions cannot be guaranteed by the compiler, just by looking at the surrounding context. We need to perform analysis on the whole program to spot potential safety issues.
The language is not strong enough to provide us guarantees that would enable us to reason locally. It’s similar to how the use of void* casts and gotos is discouraged, even though we can write good programs with them – these features require extra discipline to ensure the code is correct.
Local reasoning
The previous examples suggested that maintaining local reasoning is hard, even within the bounds of structured programming, if we have mutation on top of reference semantics. In the presence of references, two objects might be connected in ways that cannot be properly deduced by reasoning locally.
Local reasoning lowers our cognitive burden when writing and analysing code. And, as we know that our mind is the main bottleneck while programming, it probably makes sense to conclude that local reasoning is one of the most important goals in software engineering. Therefore, programming languages should aim at ensuring local reasoning.
We call it spooky action at a distance when local reasoning is broken because shared state has been unexpectedly mutated.
Value-oriented programming
In this article, what we call value-oriented programming is a programming paradigm in which first-class references are not allowed. The language might use references under the covers for efficiency reasons, but these are not exposed as first-class entities to the programmer. In contrast to pure functional programming where first-class references are also not present, value-oriented programming allows mutation.
Forbidding first-class references has the following consequences:
- spooky action at a distance cannot happen anymore;
- the law of exclusivity is imposed [McCall17], which guarantees exclusivity of access when performing mutation;
- aggregation is eliminated; to be replaced by composition.
In this paradigm, emphasis is on the use of value semantics across the language. All types in such a language should behave like int; one should see all objects as values, like int values.
A first formalisation of this paradigm can be seen in [Racordon22a].
Law of exclusivity and spooky action at a distance
Surprisingly, we can eliminate all undefined behaviour detectable only globally (probably the worst class of safety issues) if we impose just one restriction on the programming language: whenever an object is mutated, the code that does the mutation needs to have exclusive access to the object. This is called the law of exclusivity [McCall17]. This law is a fundamental part of value-oriented programming.
This law has two important consequences:
- while reading an object, nobody can change it;
- while mutating an object, nobody can read or change it.
If we start looking at an object, and we know that the object is valid, there is nobody else that can invalidate the object while we are looking at it. Mutation of the object would require us to stop looking at the object.
While trying to change the object, we don’t affect other code that might look at the same object; there can’t be such code under the law of exclusivity.
In other words, there cannot be any spooky action at a distance [Racordon22a, Abrahams22a, Abrahams22b, Abrahams22c Racordon22b]. Nobody can indirectly change an object while we are looking at it. Eliminating spooky action at a distance greatly improves local reasoning; I see this as a considerable improvement on some core ideas from Structured Programming [Hoare69].
Coming back to safety, if we start with a valid object, the only way to break the validity of that object is in the local code (as all the mutation to the object is done locally). That is, if a set of preconditions for an object were true at some point, there is no distant code that can invalidate these preconditions; local code is the only one responsible for the evolution of the validity of those preconditions. And because local memory safety issues can be handled easily by the language, we can construct a safe language. Formally, there are details that need to be discussed to reach this conclusion, but I hope the reader will understand the intuition behind this. For more information, please see [Racordon22a].
We just argued that global (memory) safety issues cannot be present if the law of exclusivity is applied. Moreover, the language can prevent local safety issues, either by detecting them during compilation or by adding runtime checks for potential unsafe operations. That means all our operations can be safe. And, as safety composes (as we argued above), we get guarantees that the whole program is safe (i.e., without undefined behaviour). Thus, this enables us to build programming languages that are safe by default.
We’ve just covered the memory safety issues, but we haven’t touched threading safety issues. Let’s now complete the picture.
Thread safety
Adding threading to C++ applications is a big source of unsafety and frustration. Actually, in her 2021 C++ Now talk [Kazakova21], Anastasia Kazakova presents data showing that in the C++ community, Concurrency safety accounts for 27% of user frustration; this is the highest source of frustration, and it accounts for almost the double of the next source of frustration. Our question is now whether the model we are discussing implies thread safety or not. In other words, can we have data races in this model or not? 7
In his concurrency talks, Kevlin Henney [Henney17] often presents the diagram reproduced in Figure 1. If we look at whether the data is mutable or not, and if the data is shared or not, we can have 4 possible cases. Out of the 4 quadrants, the one in which the data is both mutable and shared is problematic; if we don’t properly add synchronisation, we get thread safety issues. And, almost by definition, synchronisation is something with global effects; we cannot locally reason about it.
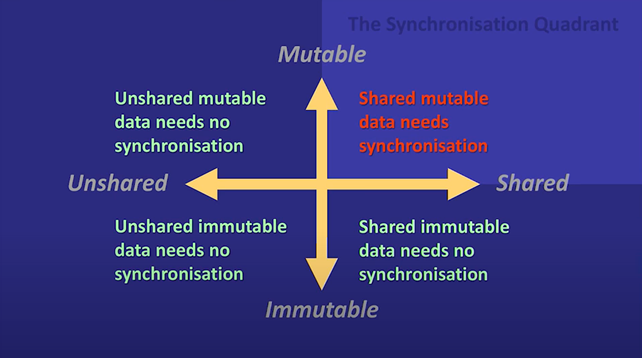 |
| Figure 1 |
In the world of value-oriented programming, where the law of exclusivity applies, we cannot be in the synchronisation quadrant. If we have a mutable object, the law of exclusivity doesn’t allow us to have that object shared – we would be in the top-left quadrant. If we are looking at an object that is shared, then the only possibility is that the object is immutable – the bottom-right quadrant.
Thus, under the law of exclusivity we can be in 3 of the 4 quadrants, but not in the synchronisation quadrant. This means that this model doesn’t require explicit synchronisation and cannot lead to data race issues. Data races occur when one thread is trying to update a value that another thread is reading; this case is completely forbidden in our model.
Value-oriented programming allows us to be concurrently safe by default.
Whole-part relations
Many programming languages use reference semantics as their underlying model. With our model, we move away from reference semantics towards value semantics (more precisely, Mutable Value Semantics [Racordon22a]). We can no longer directly encode arbitrary graphs in data structures, while allowing selective mutation to the nodes of the graphs. To use Sean Parent’s words, we are no longer allowed to have incidental data structures [Parent15].
This description may be too dense, so I’ll attempt to describe this from a different perspective. In a UML class diagram, one can associate two objects A and B by using composition or by using aggregation. In reference-oriented languages, they are usually represented by the same code, although semantically they are different.
We want to keep the composition relationship but restrict the use of aggregations. Composition is also called a whole-part relationship.
Using only whole-part relationships, all the objects in a program form a forest (set of disjoint trees). Changing one object cannot change an entirely different object (that is not a super- or sub-object of the object we are changing). This means that the impact of changing objects is always local, and we can fully reason about object change locally. I cannot stress enough the importance of this.
Looking at the ownership property, we can infer the memory safety of the program, if all the relationship between objects are compositions. If object A needs object B to function properly, then it will contain object B; but B cannot be destructed before A, so, A will always have a valid instance. If we think about it, this will rule out invalid memory access.
Please note that, for efficiency reasons, implementations of objects may share storage, either by making it immutable or by using copy-on-write to make it immutable-when-shared. But the language behaves as if there are no aggregation relationships.
Emphasis on value semantics
Under the law of exclusivity, disallowing spooky action at a distance and with objects using only whole-part relationships, all objects behave as values. They are very similar to values of an Int.
Reference semantics disappears: one cannot have an object that is changed indirectly by mutation in some other object. Object identity becomes less relevant in the face of object equality; we only care about the value of an object.
By this logic, value-oriented programming can give us the same guarantees as functional programming. But, the model is more relaxed than in functional programming. We can mutate variables under the law of exclusivity, and thus value-oriented programming is more expressive than functional programming.
Compared to functional programming, our paradigm has several advantages:
- allows expressing some problems more efficiently
- allows expressing some problems in imperative terms, which can be more natural for programmers (i.e., thinking in terms of postconditions and being more mathematical is often considered harder than just thinking in terms of a sequence of actions); using operation sequence we can avoid the mental gymnastics of functional composition.
The reader may consult [O’Neill09] for an example of a problem that, when written in functional languages, is not necessarily efficient nor easy to understand.
Changing our mental model
Like we mentioned at the beginning of the article, a programming paradigm always comes with a change in the mental model when building programs. One simply cannot write and reason about programs in the same way between two different programming paradigms. The main reason is that the programming paradigm restricts the use of certain constructs. And, each time the programmer would want to use those constructs, it needs to take a step back and devise a new strategy that avoids using them.
In value-oriented programming, we cannot share mutable objects. And, not surprisingly, this is widely used in object-oriented programming (and, in general, in many forms of imperative programming).
Let’s take an example. Let’s imagine that we are compiling a program, and we want to store the program information (syntax tree, type information, and links between nodes) in some kind of a graph. In OOP, many would probably create a Node base class, and create a class hierarchy from it. Then, one would create the possibility of child nodes (most likely by having nodes directly linked in other node classes), and the possibility of nodes to reference other nodes (similar to weak pointers). By doing so, the programmer would create what Sean Parent would call an incidental data structure [Parent15].
Value-oriented programming would prevent the user from directly expressing such a structure. Let us try to illustrate how one can model this. The whole program can be modelled by a Program class. This class can have ownership of all the nodes we need to create (i.e., use whole-part relations); for example, one can store all the nodes in an array inside this class. The children and the reference relationships can be built using indices in the entire collection of nodes. We have a completely equivalent data structure, but built using only whole-part relationships. Accessing related nodes from a given node is an operation outside any given node, so nodes cannot mutate other nodes. Mutating one node requires the mutation ability of the entire Program object, and we cannot mutate two nodes at the same time. The mutating logic, as it needs to be external to the nodes, can be reasoned locally. Because of local reasoning, the value-oriented model is arguably better compared to its object-oriented alternative.
Let us now take a more complicated example. Let’s assume that we want to build a shared cache component. And, to simplify the exposure of the problem, let’s also assume that the cache can be accessed from multiple threads. By definition, a cache can update its state every time one wants to read something from it. That is, we have a potential mutation for every call made to the cache. And, because this is a shared cache, we need to have shared access to a mutable object. This is forbidden by our model.
There is no way of implementing this program in a pure value-oriented programming style. One needs to get outside the paradigm to implement such a cache.
The bottom line is that we can’t simply jump on value-oriented programming and expect our journey to be effortless. We have to adjust our mental model for it.
The Val programming language
Val [Val] is a programming language created by Dimi Racordon and Dave Abrahams that is probably the first programming language that is focused, at its core, on call value-oriented programming. Val aims to be fast by definition, safe by default, simple and interoperable with C++.
Val is based on Swift. One can argue that Swift made the first steps towards value-oriented programming; Val takes some core ideas from Swift further and cleans up the semantics to fully resonate with value-oriented programming.
Swift encourages using value semantics [Abrahams15], but it doesn’t go all the way through to remove reference semantics. While structures uphold value semantics, classes in Swift follow reference semantics; closures (with mutable captures) also follow reference semantics.
Val doesn’t have structures and classes as Swift does; in Val there is one way of defining structures and that follows value semantics. From this point of view, one can argue that Val is simpler than Swift.
Swift aims at being a safe language (i.e., remove the presence of undefined behaviour); it does that by adding runtime checks when generating code. Val inherits the safety principle from Swift but does this in a better way. Because of the guarantees of value-oriented programming, Val has more guarantees about the preconditions of the operations, so it can eliminate some of the runtime checks.
For some people, Val somehow appears as a successor language to C++; see also my previous article [Teodorescu22] (although not necessarily positioned this way by the language’s authors). Val’s efficiency aim and the goal to be interoperable with C++ put it in that space. But, looking at the main programming paradigms in the two languages, the two languages seem to operate in different spaces.
There appears to be a big difference between Val and other languages that target to be C++ language successors (i.e., Carbon or Cpp2). Val is the only language that proposes a paradigm shift. The other languages will operate in the same paradigm as C++; i.e., in the words of Robert C. Martin, they only propose syntactic changes. With those changes alone, it’s hard to get additional guarantees from the language, and therefore it’s hard to fully fix the safety of the language and to ensure local reasoning.
Comparing Val to Rust, they both seem to fix the safety issues. That is because Rust’s borrow checker is also compatible with the law of exclusivity. But there is a big difference on how the same results are achieved. In Rust one uses reference semantics and manually annotates objects to express lifetime guarantees.
In Val the programmer cannot use reference semantics. Aggregation is forbidden, and whole-part relationships are used to express connections between objects. To recognize different ways of handling objects, Val has four parameter passing conventions (let, inout, sink and set) [Abrahams22d]. In Val all copies are explicit.
There are cases in which the programmer wants to exit the bounds of value-oriented programming. One trades safety guarantees with expressive power. Going outside of the safety guarantees of the language is not a bad thing, and it doesn’t mean that the code is unsafe; it just means that the programmer takes full ownership of guaranteeing safety. Similar to Rust’s unsafe construct, Val aims to provide a mechanism that allows programmers to exit the bounds of value-oriented programming [Evans20].
Conclusions
This article explored value-oriented programming, a new programming paradigm proposed by Dimi Racordon and Dave Abrahams with the creation of the Val programming language.
In value-oriented programming, first-class references are forbidden; everything operates under the law of exclusivity, which allows exclusive access to an object while mutating it. What is called spooky action at a distance (i.e., indirect mutation) is, consequently, also forbidden. In this model, all the relationships between objects are whole-part. In other words, we ban aggregation in the favour of composition.
We impose restrictions on programming languages to gain some guarantees. In our case, the restrictions imposed by value-oriented programming will allow us to improve on local reasoning, and to avoid a big class on safety issues (the rest of the safety issues being simpler to solve). As cognitive power is the main bottleneck in software engineering, improving on local reasoning may have a big impact on software engineering.
The Val programming language is the first programming language that has value-oriented programming (as we defined it) at its core. It is an experiment that allows us to explore the boundaries of this paradigm.
Will the Val language succeed? Will the value-oriented programming be highly used? We don’t know; and at this point, I don’t think it matters that much. We’ve found a new programming paradigm, and I feel that it’s our moral duty to explore this new programming paradigm. Only after exploring it, we can decide to completely drop it, or to build all future programming languages based on it.
Acknowledgements
The author would like to thank Dave Abrahams and Dimi Racordon for reviewing the article and providing numerous suggestions to improve it.
References
[Abrahams15] Dave Abrahams, Protocol-Oriented Programming in Swift, WWDC15, 2015, https://www.youtube.com/watch?v=p3zo4ptMBiQ
[Abrahams22a] Dave Abrahams, A Future of Value Semantics and Generic Programming (part 1), C++ Now 2022, https://www.youtube.com/watch?v=4Ri8bly-dJs
[Abrahams22b] Dave Abrahams, Dimi Racordon, A Future of Value Semantics and Generic Programming (part 2), C++ Now 2022, https://www.youtube.com/watch?v=GsxYnEAZoNI&list=WL
[Abrahams22c] Dave Abrahams, ‘Value Semantics: Safety, Regularity, Independence, and the Future of Programming’, CppCon 2022, https://www.youtube.com/watch?v=QthAU-t3PQ4
[Abrahams22d] Dave Abrahams, Sean Parent, Dimi Racordon, David Sankel, ‘P2676: The Val Object Model’, https://www.open-std.org/jtc1/sc22/wg21/docs/papers/2022/p2676r0.pdf
[Dahl72] O.-J. Dahl, E. W. Dijkstra, C. A. R. Hoare, Structured Programming, Academic Press Ltd., 1972
[Evans20] Ana Nora Evans, Bradford Campbell, Mary Lou Soffa, Is Rust used safely by software developers?, 2020 IEEE/ACM 42nd International Conference on Software Engineering (ICSE), 2020
[Henney17] Kevlin Henney, Thinking Outside the Synchronisation Quadrant, ACCU 2017 conference, 2017, https://www.youtube.com/watch?v=UJrmee7o68A
[Hoare69] C. A. R. Hoare, An axiomatic basis for computer programming. Communications of the ACM. 12 (10): 576–580, 1969.
[Kazakova21] Anastasia Kazakova, Code Analysis++, CppNow, 2021, https://www.youtube.com/watch?v=qUmG61aQyQE
[Martin11] Robert C. Martin, The Last Programming Language, 2011, https://www.youtube.com/watch?v=P2yr-3F6PQo
[McCall17] John McCall, Swift ownership manifesto, 2017. https://github.com/apple/swift/blob/main/docs/OwnershipManifesto.md
[O’Neill09] Melissa E. O’Neill, The genuine sieve of Eratosthenes, Journal of Functional Programming 19.1, 2009
[Parent15] Sean Parent, Better Code: Data Structures, CppCon 2015, https://www.youtube.com/watch?v=sWgDk-o-6ZE
[Parent22] Sean Parent, Exceptions the Other Way Around, C++Now 2022, https://www.youtube.com/watch?v=mkkaAWNE-Ig
[Racordon22a] Dimi Racordon, Denys Shabalin, Daniel Zheng, Dave Abrahams, Brennan Saeta, Implementation Strategies for Mutable Value Semantics, https://www.jot.fm/issues/issue_2022_02/article2.pdf
[Racordon22b] Dimi Racordon, Val Wants To Be Your Friend: The design of a safe, fast, and simple programming language, CppCon 2022, https://www.youtube.com/watch?v=ws-Z8xKbP4w
[Teodorescu22] Lucian Radu Teodorescu, The Year of C++ Successor Languages, Overload 172, December 2022, https://accu.org/journals/overload/30/172/overload172.pdf#page=10
[Val] The Val Programming Language, https://www.val-lang.dev/
Footnotes
- For any syntax, there is also semantics associated with it; Robert C. Martin seems to conflate the two notions and just talks about syntax.
- Some of the readers might disagree with some of these characterisations; as much as possible, I tried to stick to Martin’s exposition of semantic classes (programming paradigms).
- The ideas of structured programming go beyond this point; structured programming also emphasizes the use of abstractions, decomposition of programs and local reasoning [Dahl72]; but we will ignore these for the purpose of this article.
- Errors are not bugs, just like throwing exceptions is not considered buggy behaviour. A program can be correct, i.e., bug-free, in the presence of errors.
- In C++, overflows of unsigned values are well defined and use modulo arithmetic.
- We use the term ‘detect’ here in a broader context; we don’t mean that the compiler or generated runtime code would be required to perform analysis to identify those scenarios (that might lead to the halting problem). If a person looking at the code can identify the potentiality of safety issues, we say that the undefined behaviour is detectable.
- Deadlocks and livelocks are not safety issues by our definition, so we won’t cover them here.
has a PhD in programming languages and is a Staff Engineer at Garmin. He likes challenges; and understanding the essence of things (if there is one) constitutes the biggest challenge of all.
