








Kafka’s configuration can be confusing. Slanislav Kozlovski helps us visualise this most misunderstood configuration setting.
Having worked with Kafka for almost two years now, there are two approaches to whose interaction I’ve seen to be ubiquitously confused. Those two configs are acks and min.insync.replicas – and how they interplay with each other.
This article aims to be a handy reference which clears the confusion through the help of some illustrations.
| Apache Kafka | |
|
Replication
To best understand these configs, it’s useful to remind ourselves of Kafka’s replication protocol.
I’m assuming you’re already familiar with Kafka – if you aren’t, feel free to check out my ‘A Thorough Introduction to Apache Kafka’ article [Kozlovski20].
For each partition, there exists one leader broker and n follower brokers. The config which controls how many such brokers (1 + N) exist is replication.factor. That’s the total amount of times the data inside a single partition is replicated across the cluster. The default and typical recommendation is 3 (see Figure 1).
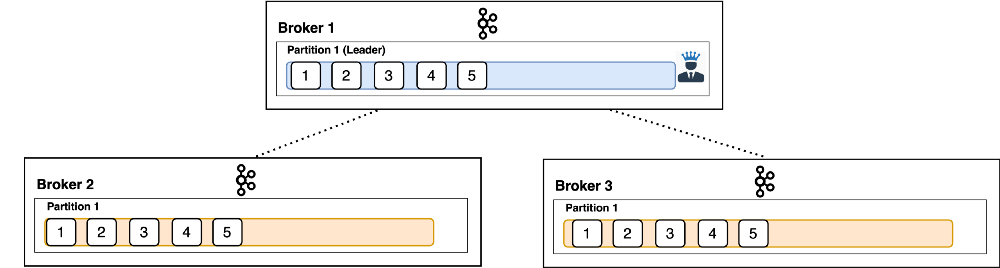 |
| Figure 1 |
Producer clients only write to the leader broker – the followers asynchronously replicate the data. Now, because of the messy world of distributed systems, we need a way to tell whether these followers are managing to keep up with the leader – do they have the latest data written to the leader?
In-sync replicas
An in-sync replica (ISR) is a broker that has the latest data for a given partition. A leader is always an in-sync replica. A follower is an in-sync replica only if it has fully caught up to the partition it’s following. In other words, it can’t be behind on the latest records for a given partition.
If a follower broker falls behind the latest data for a partition, we no longer count it as an in-sync replica. See Figure 2, which shows that Broker 3 is behind (out of sync).
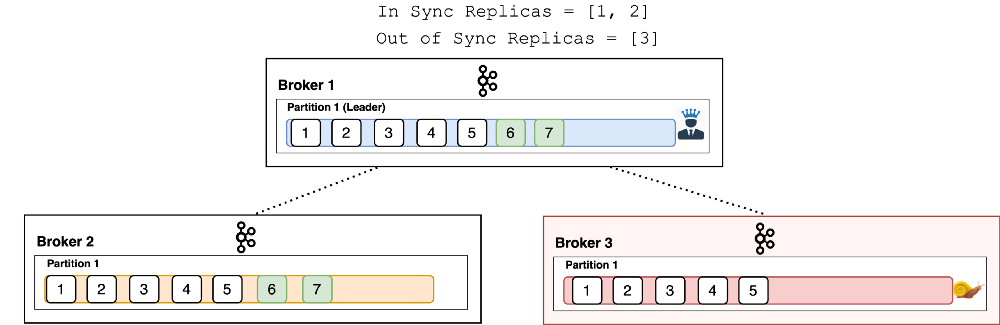 |
| Figure 2 |
Note that the way we determine whether a replica is in-sync or not is a bit more nuanced – it’s not as simple as ‘Does the broker have the latest record?’ Discussing that is outside the scope of this article. For now, trust me that red brokers with snails on them are out of sync.
Acknowledgements
The acks setting is a client (producer) configuration. It denotes the number of brokers that must receive the record before we consider the write as successful. It support three values – 0, 1, and all.
‘acks=0’
With a value of 0, the producer won’t even wait for a response from the broker. It immediately considers the write successful the moment the record is sent out. (See Figure 3: The producer doesn’t even wait for a response. The message is acknowledged!)
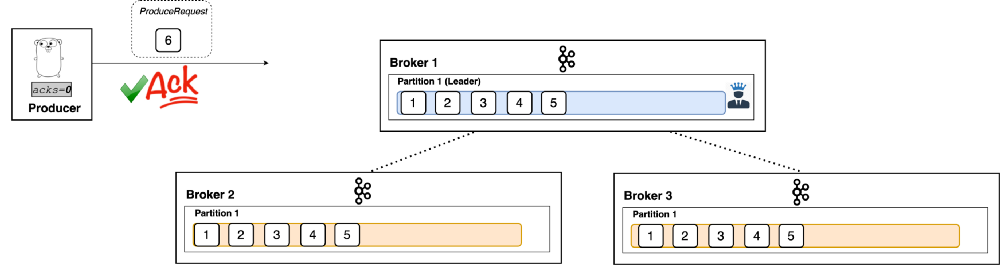 |
| Figure 3 |
‘acks=1’
With a setting of 1, the producer will consider the write successful when the leader receives the record. The leader broker will know to immediately respond the moment it receives the record and not wait any longer. (See Figure 4: The producer waits for a response. Once it receives it, the message is acknowledged. The broker immediately responds once it receives the record. The followers asynchronously replicate the new record.)
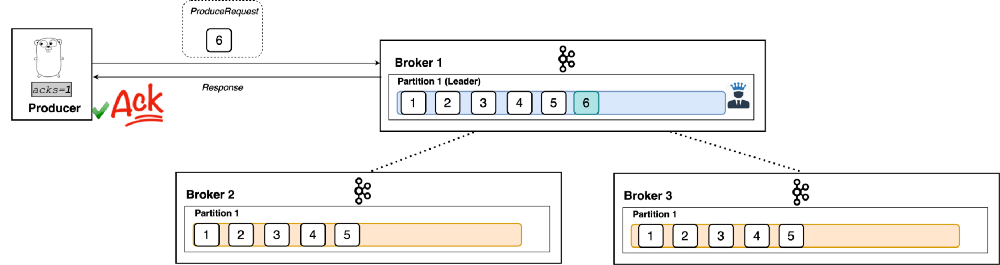 |
| Figure 4 |
‘acks=all’
When set to all, the producer will consider the write successful when all of the in-sync replicas receive the record. This is achieved by the leader broker being smart as to when it responds to the request – it’ll send back a response once all the in-sync replicas receive the record themselves. (See Figure 5: Not so fast! Broker 3 still hasn’t received the record.)
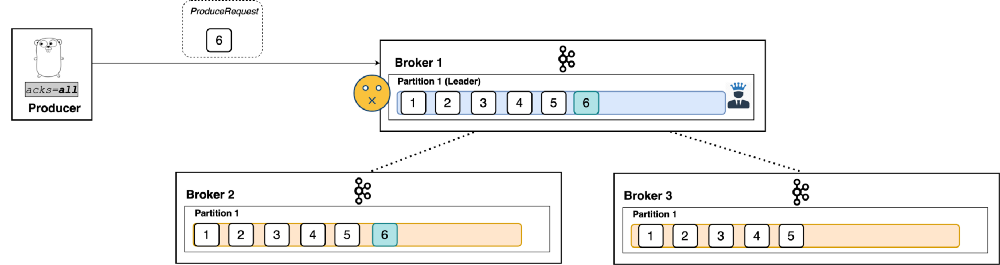 |
| Figure 5 |
Like I said, the leader broker knows when to respond to a producer that uses acks=all. (See Figure 6: Ah, there we go!)
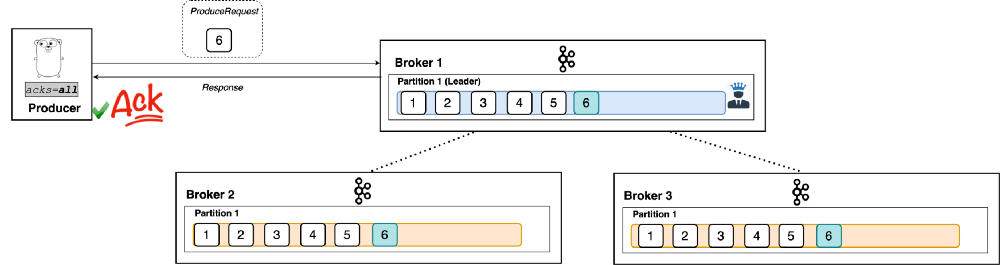 |
| Figure 6 |
Acks’s utility
As you can tell, the acks setting is a good way to configure your preferred trade-off between durability guarantees and performance.
If you’d like to be sure your records are nice and safe – configure your acks to all.
If you value latency and throughput over sleeping well at night, set a low threshold of 0. You may have a greater chance of losing messages, but you inherently have better latency and throughput.
Minimum in-sync replica
There’s one thing missing with the acks=all configuration in isolation.
If the leader responds when all the in-sync replicas have received the write, what happens when the leader is the only in-sync replica? Wouldn’t that be equivalent to setting acks=1?
This is where min.insync.replicas starts to shine!
min.insync.replicas is a config on the broker that denotes the minimum number of in-sync replicas required to exist for a broker to allow acks=all requests. That is, all requests with acks=all won’t be processed and receive an error response if the number of in-sync replicas is below the configured minimum amount. It acts as a sort of gatekeeper to ensure scenarios like the one described above can’t happen. (See Figure 7: Broker 3 is out of sync).
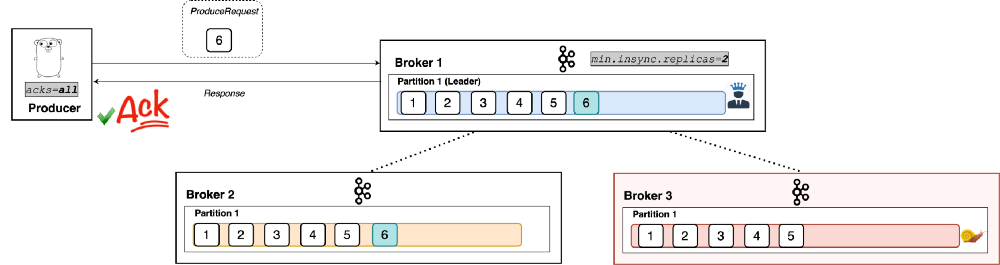 |
| Figure 7 |
As shown, min.insync.replicas=X allows acks=all requests to continue to work when at least x replicas of the partition are in sync. Here, we saw an example with two replicas.
But if we go below that value of in-sync replicas, the producer will start receiving exceptions. (See Figure 8: Brokers 2 and 3 are out of sync.)
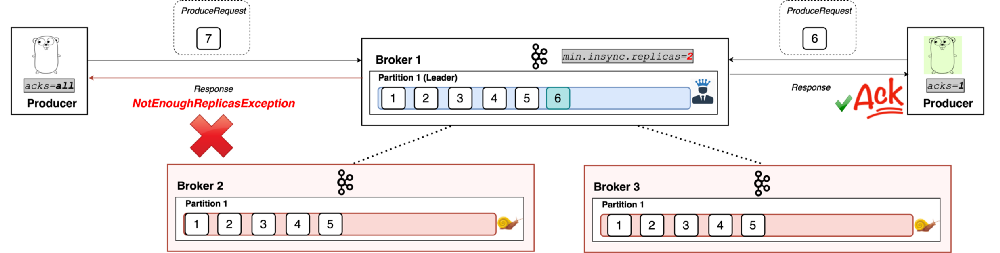 |
| Figure 8 |
As you can see, producers with acks=all can’t write to the partition successfully during such a situation. Note, however, that producers with acks=0 or acks=1 continue to work just fine.
Caveat
A common misconception is that min.insync.replicas denotes how many replicas need to receive the record in order for the leader to respond to the producer. That’s not true – the config is the minimum number of in-sync replicas required to exist in order for the request to be processed. That is, if there are three in-sync replicas and min.insync.replicas=2, the leader will respond only when all three replicas have the record. (See Figure 9: Broker 3 is an in-sync replica. The leader can’t respond yet because broker 3 hasn’t received the write.)
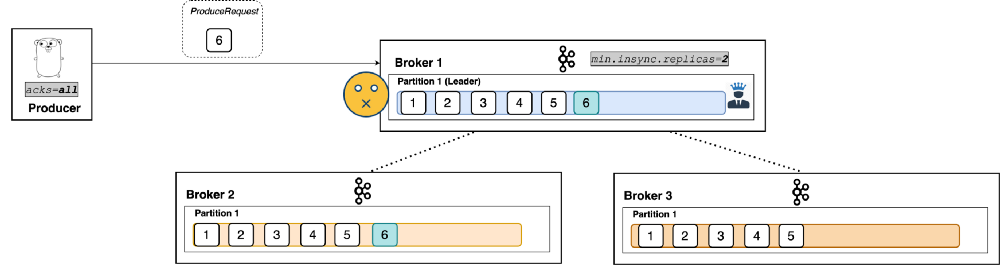 |
| Figure 9 |
Summary
And that’s all there is to it! Simple once visualized – isn’t it?
To recap, the acks and min.insync.replicas settings are what let you configure the preferred durability requirements for writes in your Kafka cluster.
acks=0– the write is considered successful the moment the request is sent out. No need to wait for a response.acks=1– the leader must receive the record and respond before the write is considered successful.acks=all– all online in sync replicas must receive the write. If there are less thanmin.insync.replicasonline, then the write won’t be processed.
Further Reading
Kafka is a complex distributed system, so there’s a lot more to learn about!
Here are some resources I can recommend as a follow-up:
- Kafka consumer data-access semantics (https://www.confluent.io/blog/apache-kafka-data-access-semantics-consumers-and-membership/) – A more in-depth blog of mine that goes over how consumers achieve durability, consistency, and availability.
- Kafka controller (https://medium.com/@stanislavkozlovski/apache-kafkas-distributed-system-firefighter-the-controller-broker-1afca1eae302) – Another in-depth post of mine where we dive into how coordination between brokers works. It explains what makes a replica out of sync (the nuance I alluded to earlier).
- ‘99th Percentile Latency at Scale with Apache Kafka’ (https://www.confluent.io/blog/configure-kafka-to-minimize-latency/) – An amazing post going over Kafka performance – great tips and explanation on how to configure for low latency and high throughput.
- Kafka Summit SF 2019 videos: https://www.confluent.io/resources/kafka-summit-san-francisco-2019/
- Confluent blog (https://www.confluent.io/blog/) – a wealth of information regarding Apache Kafka
- Kafka documentation (https://kafka.apache.org/documentation/) – Great, extensive, high-quality documentation.
Kafka is actively developed – it’s only growing in features and reliability due to its healthy community. To best follow its development, I’d recommend joining the mailing lists (https://kafka.apache.org/contact).
Reference
[Kozlovski20] Stanislav Kozlovski ‘’ in Overload 159, August 2020, available at: https://accu.org/journals/overload/28/158/kozlovski/
Stanislav began his programming career racing through some coding academies and bootcamps, where he aced all of his courses and began work at SumUp, a German fintech company aiming to become the first global card acceptance brand. He was later recruited into Confluent, a company offering a hosted solution and enterprise products around Apache Kafka.
