








Kafka serves as the heart of many companies’ architecture. Stanislav Kozlovski takes a deep dive into the system.
Kafka is a word that gets heard a lot nowadays. A lot of leading digital companies seem to use it. But what is it actually?
Kafka was originally developed at LinkedIn in 2011 and has improved a lot since then. Nowadays, it’s a whole platform, allowing you to redundantly store absurd amounts of data, have a message bus with huge throughput (millions/sec), and use real-time stream processing on the data that goes through it all at once.
This is all well and great, but stripped down to its core, Kafka is a distributed, horizontally scalable, fault-tolerant commit log.
Those were some fancy words – let’s go at them one by one and see what they mean. Afterwards, we’ll dive deep into how it works.
Distributed
A distributed system is one which is split into multiple running machines, all of which work together in a cluster to appear as one single node to the end user. Kafka is distributed in the sense that it stores, receives, and sends messages on different nodes (called brokers).
The benefits to this approach are high scalability and fault tolerance.
Horizontally scalable
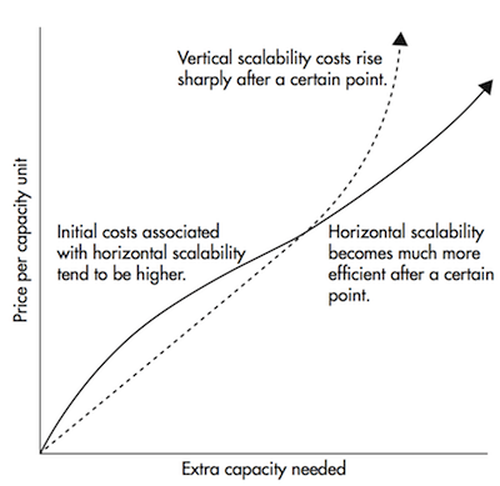
Let’s define the term vertical scalability first. Say, for instance, you have a traditional database server that’s starting to get overloaded. The way to get this solved is to simply increase the resources (CPU, RAM, SSD) on the server. This is called vertical scaling – where you add more resources to the machine. There are two big disadvantages to scaling upwards:
- There are limits defined by the hardware. You cannot scale upwards indefinitely.
- It usually requires downtime, something which big corporations can’t afford.
Horizontal scalability is solving the same problem by throwing more machines at it. Adding a new machine doesn’t require downtime, nor are there any limits to the amount of machines you can have in your cluster. The catch is not all systems support horizontal scalability, as they’re not designed to work in a cluster, and those that are are usually more complex to work with.
Figure 1 shows that horizontal scaling becomes much cheaper after a certain threshold.
 |
| Figure 1 |
Fault-tolerant
Something that emerges in nondistributed systems is they have a single point of failure (SPoF). If your single database server fails (as machines do) for whatever reason, you’re screwed.
Distributed systems are designed in such a way to accommodate failures in a configurable way. In a 5-node Kafka cluster, you can have it continue working even if two of the nodes are down. It’s worth noting that fault tolerance is at a direct trade-off with performance, as in the more fault-tolerant your system is, the less performant it is.
Commit log
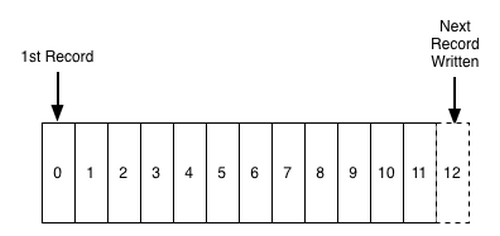
A commit log (also referred to as write-ahead log or a transaction log) is a persistent-ordered data structure that only supports appends. You can’t modify or delete records from it. It’s read from left to right and guarantees item ordering. Figure 2 is an illustration of a commit log [Kreps13].
 |
| Figure 2 |
“Are you telling me that Kafka is such a simple data structure?”
In many ways, yes. This structure is at the heart of Kafka and is invaluable, as it provides ordering, which in turn provides deterministic processing. Both of which are nontrivial problems in distributed systems.
Kafka actually stores all of its messages to disk (more on that later), and having them ordered in the structure lets it take advantage of sequential disk reads.
- Reads and writes are a constant time O(1) (knowing the record ID), which compared to other structure’s O(log N) operations on disk is a huge advantage, as each disk seek is expensive
- Reads and writes don’t affect each other. Writing wouldn’t lock reading and vice versa (as opposed to balanced trees).
These two points have huge performance benefits, since the data size is completely decoupled from performance. Kafka has the same performance whether you have 100 KB or 100 TB of data on your server.
How does it work?
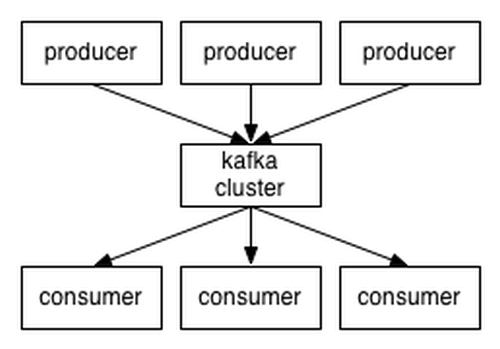
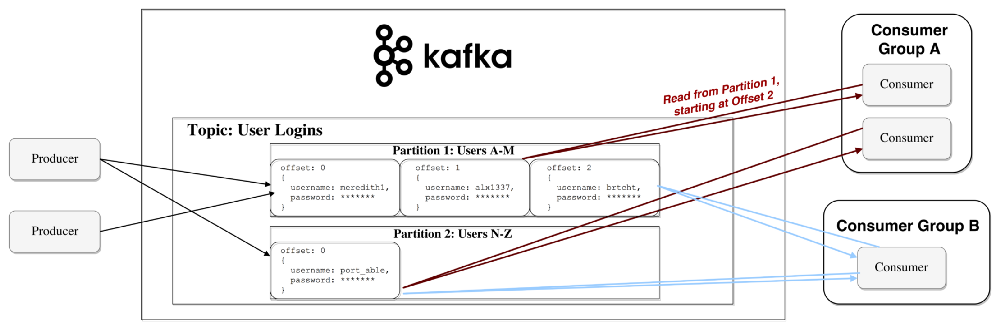
Applications (producers) send messages (records) to a Kafka node (broker), and said messages are processed by other applications called consumers. Said messages get stored in a topic and consumers subscribe to the topic to receive new messages (see Figure 3).
 |
| Figure 3 |
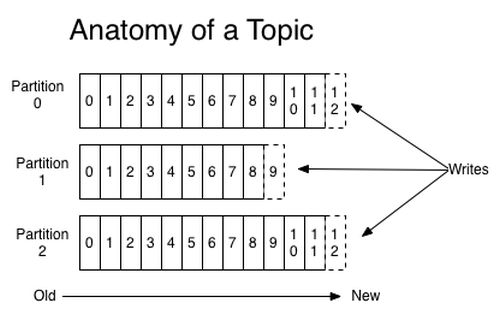
As topics can get quite big, they get split into partitions of a smaller size for better performance and scalability. (For example, say you were storing user login requests. You could split them by the first character of the user’s username.)
Kafka guarantees that all messages inside a partition are ordered in the sequence they came in. The way you distinguish a specific message is through its offset, which you could look at as a normal array index, a sequence number which is incremented for each new message in a partition (see Figure 4).
 |
| Figure 4 |
Kafka follows the principle of a dumb broker and smart consumer. This means that Kafka doesn’t keep track of what records are read by the consumer, then deleting them. Rather, it stores them for a set amount of time (e.g., one day) or until some size threshold is met. Consumers, themselves, poll Kafka for new messages and say what records they want to read. This allows them to increment/decrement the offset they’re at as they wish, thus being able to replay and reprocess events.
It’s worth noting consumers are actually consumer groups that have one or more consumer processes inside. In order to avoid two processes reading the same message twice, each partition is tied to only one consumer process per group. See Figure 5 for a representation of the data flow.
 |
| Figure 5 |
Persistence to disk
As I mentioned earlier, Kafka actually stores all of its records to disk and doesn’t keep anything in RAM. You might be wondering how this is in the slightest way a sane choice. There are numerous optimizations behind this that make it feasible:
- Kafka has a protocol that groups messages together. This allows network requests to group messages together and reduce network overhead; the server, in turn, persists chunk of messages in one go, and consumers fetch large linear chunks at once.
- Linear reads/writes on a disk are fast. The concept that modern disks are slow is because of numerous disk seeks, something that’s not an issue in big linear operations.
- Said linear operations are heavily optimized by the OS, via read-ahead (prefetch large block multiples) and write-behind (group small logical writes into big physical writes) techniques.
- Modern OSes cache the disk in free RAM. This is called pagecache.
- Since Kafka stores messages in a standardized binary format unmodified throughout the whole flow (producer → broker → consumer), it can make use of the zero-copy optimization. That’s when the OS copies data from the pagecache directly to a socket, effectively bypassing the Kafka broker application entirely.
All of these optimizations allow Kafka to deliver messages at near network speed.
Data distribution and replication
Let’s talk about how Kafka achieves fault tolerance and how it distributes data between nodes.
Data replication
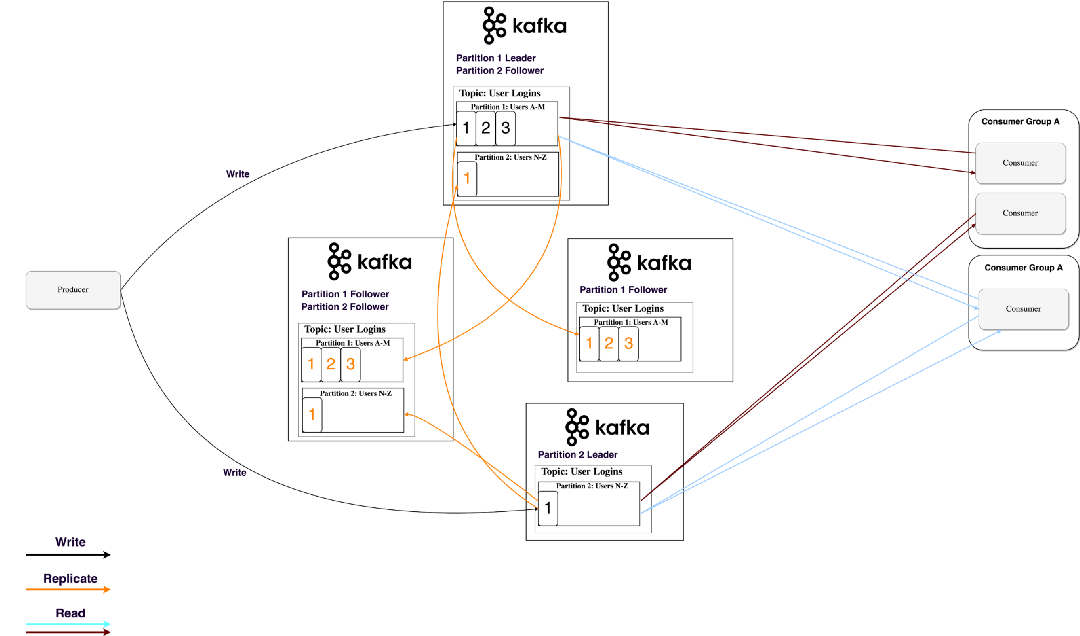
Partition data is replicated across multiple brokers in order to preserve the data in case one broker dies.
At all times, one broker owns a partition and is the node through which applications write/read from the partition. This is called a partition leader. It replicates the data it receives to n other brokers, called followers. They store the data as well and are ready to be elected as leader in case the leader node dies.
This helps you configure the guarantee that any successfully published message won’t be lost. Having the option to change the replication factor lets you trade performance for stronger durability guarantees, depending on the criticality of the data. Figure 6 shows 4 Kafka brokers with a replication factor of 3.
 |
| Figure 6 |
In this way, if one leader ever fails, a follower can take his place.
You may be asking, though:
“How does a producer/consumer know who the leader of a partition is?”
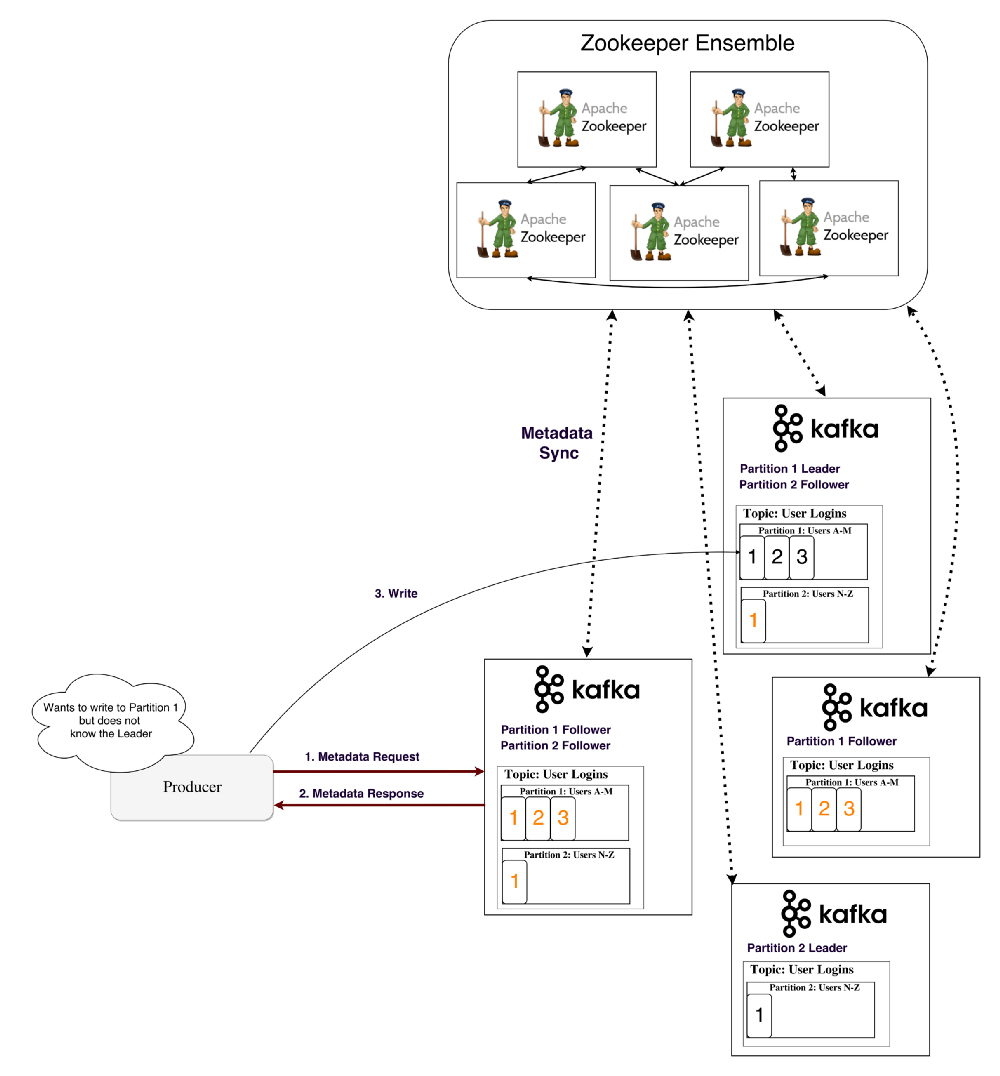
For a producer/consumer to write/read from a partition, they need to know its leader, right? This information needs to be available from somewhere.
Kafka stores such metadata in a service called ZooKeeper.
What’s ZooKeeper?
ZooKeeper is a distributed key-value store. It’s highly optimized for reads, but writes are slower. It’s most commonly used to store metadata and handle the mechanics of clustering (heartbeats, distributing updates/configurations, etc).
It allows clients of the service (the Kafka brokers) to subscribe and have changes sent to them once they happen. This is how brokers know when to switch partition leaders. ZooKeeper is also extremely fault tolerant, and it ought to be, as Kafka heavily depends on it.
It’s used for storing all sort of metadata, to mention some:
- Consumer groups offset per partition (although modern clients store offsets in a separate Kafka topic)
- Access control lists (ACLs) – used for limiting access/authorization
- Producer and consumer quotas –maximum message/sec boundaries
- Partition leaders and their health
How does a producer/consumer know who the leader of a partition is?
Producers and consumers used to directly connect and talk to ZooKeeper to get this (and other) information. Kafka has been moving away from this coupling, and since versions 0.8 and 0.9 (released 5 years ago) clients have been fetching metadata information from Kafka brokers directly, who themselves talk to ZooKeeper.
Kafka needs no keeper
Recently, the Kafka community has started moving away from ZooKeeper with a concrete proposal to use a self-managed metadata quorum based on the Raft algorithm [Apache-2]. Figure 7 shows the metadata flow.
 |
| Figure 7 |
Streaming
In Kafka, a stream processor is anything that takes continual streams of data from input topics, performs some processing on this input, and produces a stream of data to output topics (or external services, databases, the trash bin – wherever really).
It’s possible to do simple processing directly with the producer/consumer APIs; however, for more complex transformations like joining streams together, Kafka provides a integrated Streams API library [KafkaAPI].
This API is intended to be used within your own codebase – it’s not running on a broker. It works similar to the consumer API and helps you scale out the stream processing work over multiple applications (similar to consumer groups).
Stateless processing
A stateless processing of a stream is deterministic processing that doesn’t depend on anything external. You know that for any given data, you’ll always produce the same output independent of anything else. An example for that would be simple data transformation – appending something to a string "Hello" → "Hello, World!" (see Figure 8).
 |
| Figure 8 |
Stream-table duality
It’s important to recognize that streams and tables are essentially the same. A stream can be interpreted as a table, and a table can be interpreted as a stream.
Stream as a table
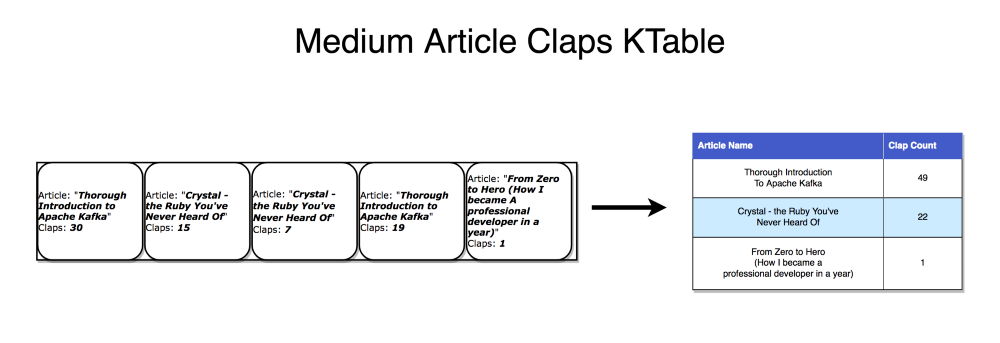
A stream can be interpreted as a series of updates for data, in which the aggregate is the final result of the table. This technique is called event sourcing [Fowler05].
If you look at how synchronous database replication is achieved, you’ll see it’s through the so-called streaming replication, where each change in a table is sent to a replica server. Another example of event sourcing are blockchain ledgers – a ledger is a series of changes as well.
A Kafka stream can be interpreted in the same way – events which, when accumulated, form the final state. Such stream aggregations get saved in a local RocksDB [GitHub] (by default) and are called a KTable. Figure 9 illustrates that each record increments the aggregated count.
 |
| Figure 9 |
Table as a stream
A table can be looked at as a snapshot of the latest value for each key in a stream. In the same way that stream records can produce a table, table updates can produce a changelog stream (see Figure 10).
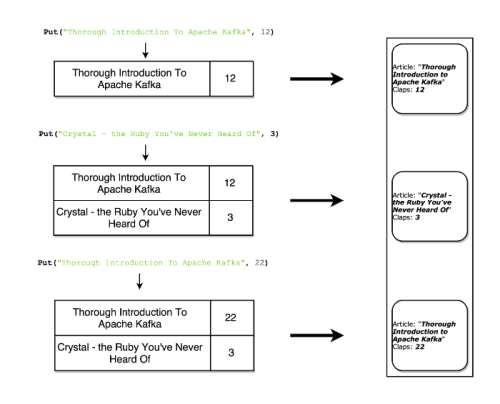 |
| Figure 10 |
Stateful processing
Some simple operations, like map() or filter(), are stateless and don’t require you to keep any data regarding the processing. However, in real life, most operations you’ll do will be stateful (e.g., count()), and as such, will require you to store the currently accumulated state.
The problem with maintaining the state on stream processors is the stream processors can fail! Where would you need to keep this state in order to make it fault-tolerant?
A naive approach is to simply store all states in a remote database and join over the network to that store. The problem with this is there’s no locality of data and lots of network round trips, both of which will significantly slow down your application.
A more subtle but important problem is your stream processing job’s uptime would be tightly coupled to the remote database and the job won’t be self-contained (a change in the database from another team might break your processing).
So what’s a better approach?
Recall the duality of tables and streams. This allows us to convert streams into tables that are colocated with our processing. It also provides us with a mechanism for handling fault tolerance – by storing the streams in a Kafka broker.
A stream processor can keep its state in a local table (e.g., RocksDB), which will be updated from an input stream (after perhaps some arbitrary transformation). When the process fails, it can restore its data by replaying the stream.
You could even have a remote database be the producer of the stream, effectively broadcasting a changelog with which you rebuild the table locally. Figure 11 illustrates stateful processing – joining a KStream with a KTable.
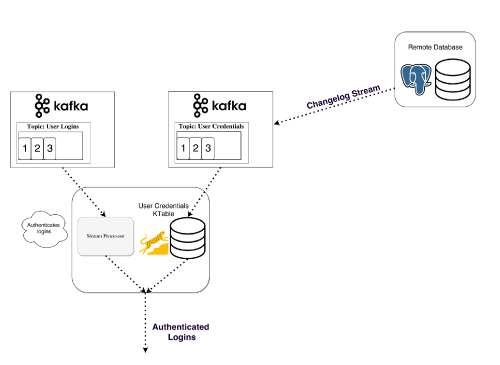 |
| Figure 11 |
ksqlDB
Normally, you’d be forced to write your stream processing in a JVM language, as that’s where the only official Kafka Streams API client is. Figure 12 shows a sample ksqlDB setup.
 |
| Figure 12 |
Released in April 2018 [Confluent-1], ksqlDB [Apache-1] is a feature that allows you to write your simple streaming jobs in a familiar SQL-like language.
You set up a ksqlDB server and interactively query it through a CLI [Wikipedia] to manage the processing. It works with the same abstractions (KStream and KTable), guarantees the same benefits of the Streams API (scalability, fault tolerance), and greatly simplifies work with streams.
This might not sound like a lot, but in practice, it’s way more useful for testing out stuff and even allows people outside of development (e.g., product owners) to play around with stream processing. I encourage you to take a look at the quick-start video and see how simple it is [Confluent-2].
Streaming alternatives
Kafka streams are a perfect mix of power and simplicity. They arguably have the best capabilities for stream jobs on the market, and they integrate with Kafka way easier than other stream-processing alternatives (Storm, Samza, Spark, Wallaroo).
The problem with most other stream-processing frameworks is they’re complex to work with and deploy. A batch-processing framework like Spark needs to:
- Control a large number of jobs over a pool of machines and efficiently distribute them across the cluster
- To achieve this, it has to dynamically package up your code and physically deploy it to the nodes that’ll execute it (along with the configuration, libraries, etc.)
Unfortunately, tackling these problems makes the frameworks pretty invasive. They want to control many aspects of how code is deployed, configured, monitored, and packaged.
Kafka Streams let you roll out your own deployment strategy when you need it, be it Kubernetes, Mesos, Nomad, Docker Swarm, or others.
The underlying motivation of Kafka Streams is to enable all your applications to do stream processing without the operational complexity of running and maintaining yet another cluster. The only potential downside is that it’s tightly coupled with Kafka, but in the modern world, where most if not all real-time processing is powered by Kafka, that may not be a big disadvantage.
When would you use Kafka?
As we already covered, Kafka allows you to have a huge amount of messages go through a centralized medium and to store them without worrying about things like performance or data loss.
This means it’s perfect for use as the heart of your system’s architecture, acting as a centralized medium that connects different applications. Kafka can be the center piece of an event-driven architecture and allows you to truly decouple applications from one another. See Figure 13.
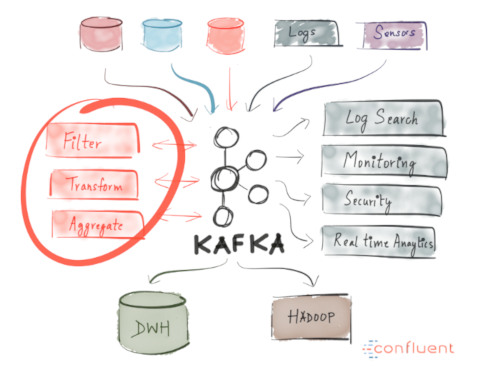 |
| Figure 13 |
Kafka allows you to easily decouple communication between different (micro)services. With the Streams API, it’s now easier than ever to write business logic that enriches Kafka topic data for service consumption. The possibilities are huge, and I urge you to explore how companies are using Kafka.
Why has it seen so much use?
High performance, availability, and scalability alone aren’t strong enough reasons for a company to adopt a new technology. There are other systems that boast similar properties, but none have become so widely used. Why is that?
The reason Kafka has grown in popularity (and continues to do so) is because of one key thing – businesses nowadays benefit greatly from event-driven architecture. This is because the world has changed – an enormous (and ever-growing) amount of data is being produced and consumed by many different services (internet of things, machine learning, mobile, microservices).
A single real-time event-broadcasting platform with durable storage is the cleanest way to achieve such an architecture. Imagine what kind of a mess it’d be if streaming data to/from each service used a different technology specifically catered to it.
This, paired with the fact that Kafka provides the appropriate characteristics for such a generalized system (durable storage, event broadcast, table and stream primitives, abstraction via ksqlDB, open source, actively developed) make it an obvious choice for companies.
Summary
Apache Kafka is a distributed streaming platform capable of handling trillions of events a day. Kafka provides low-latency, high-throughput, fault-tolerant publish and subscribe pipelines and is able to process streams of events.
We went over its basic semantics (producer, broker, consumer, topic), learned about some of its optimizations (pagecache), learned how it’s fault-tolerant by replicating data, and were introduced to its ever-growing powerful streaming abilities.
Kafka has seen large adoption at thousands of companies worldwide, including a third of the Fortune 500. With the active development of Kafka and the recently released first major version 1.0 [Confluent-3], there are predictions that this streaming platform is going to be as big and central of a data platform as relational databases are.
I hope this introduction helped familiarize you with Apache Kafka and its potential.
This article was first published on Stanislav’s blog on 15 December 2017: https://medium.com/better-programming/thorough-introduction-to-apache-kafka-6fbf2989bbc1
It has been lightly edited to incorporate new advancements in this fast-moving technology.
Further reading, resources, references and things I didn’t mention
The rabbit hole goes deeper than this article was able to cover. Here are some features I didn’t get the chance to mention but are nevertheless important to know:
- Controller broker, in-sync replicas: The way in which Kafka keeps the cluster healthy and ensures adequate consistency and durability [Kozlovski18]
- Connector API: API helping you connect various services to Kafka as a source or sink (PostgreSQL, Redis, Elasticsearch) [Confluent-4]
- Log compaction: An optimization which reduces log size. Extremely useful in changelog streams [Cloudurable].
- Exactly once message semantics: Guarantee that messages are received exactly once. This is a big deal, as it’s difficult to achieve [Confluent-5].
Resources
‘Kafka Acks Explained’: A short article of mine explaining the commonly confused acks and min.isr settings, at https://medium.com/better-programming/kafka-acks-explained-c0515b3b707e
‘Kafka Needs No Keeper’: A great talk by Colin McCabe about how Apache Kafka is implementing its own consensus algorithm for metadata based on Raft at https://www.infoq.com/presentations/kafka-zookeeper/
Confluent blog: A wealth of information regarding Apache Kafka at https://www.confluent.io/blog/
Kafka documentation: Great, extensive, high-quality documentation at https://kafka.apache.org/documentation/
Kafka Summit 2017 videos at https://www.confluent.io/resources/kafka-summit-san-francisco-2017/
References
[Apache-1] ksqlDB: https://ksqldb.io
[Apache-2] ‘KIP-500: Replace ZooKeeper with a Self-Managed Metadata Quorum’: https://cwiki.apache.org/confluence/display/KAFKA/KIP-500%3A+Replace+ZooKeeper+with+a+Self-Managed+Metadata+Quorum
[Cloudurable] ‘Kafka Architecture: Log Compaction’ posted 18 May 2017 at http://cloudurable.com/blog/kafka-architecture-log-compaction/index.html
[Confluent-1] ‘Confluent Platform 4.1 with Production-Ready KSQL Now Available’ posted 17 April 2018 at https://www.confluent.io/blog/confluent-platform-4-1-with-production-ready-ksql-now-available/
[Confluent-2] ‘Developer Preview: KSQL from Confluent’, uploaded 28 August 2017 at https://www.confluent.io/blog/confluent-platform-4-1-with-production-ready-ksql-now-available/
[Confluent-3] ‘Apache Kafka Goes 1.0’, uploaded 1 November 2017 at https://www.confluent.io/blog/apache-kafka-goes-1-0/
[Confluent-4] ‘Announcing Kafka Connect: Building large-scale low-latency data pipelines’ posted 18 February 2016 athttps://www.confluent.io/blog/announcing-kafka-connect-building-large-scale-low-latency-data-pipelines/
[Confluent-5] ‘Exactly-Once Semantics Are Possible: Here’s How Kafka Does It’, posted 30 June 2017 at https://www.confluent.io/blog/exactly-once-semantics-are-possible-heres-how-apache-kafka-does-it/
[Fowler05] Martin Fowler, ‘Event Sourcing’, posted 12 December 2005 at https://martinfowler.com/eaaDev/EventSourcing.html
[GitHub] ‘RocksDB Basics’ at https://github.com/facebook/rocksdb/wiki/rocksdb-basics
[KafkaAPI] ‘Kafka Streams’ at https://kafka.apache.org/documentation/streams/
[Kozlovski18] ‘Apache Kafka’s Distributed Systems Firefighter – the Controller Broker’ (covers how coordination between the brokers works and much more) at https://medium.com/@stanislavkozlovski/apache-kafkas-distributed-system-firefighter-the-controller-broker-1afca1eae302
[Wikipedia] ‘Command-line interface’ at https://en.wikipedia.org/wiki/Command-line_interface
Acknowledgements
Some of the images in this article are from the Kafka blog.
Figure 13 is reproduced courtesy of Confluent.
Stanislav began his programming career racing through some coding academies and bootcamps, where he aced all of his courses and began work at SumUp, a German fintech company aiming to become the first global card acceptance brand. He was later recruited into Confluent, a company offering a hosted solution and enterprise products around Apache Kafka.
