








By Sebastian Theophil
We like to write code but—despite our best efforts—we make mistakes. Our program will contain bugs. Sometimes, we don’t write what we mean to write, sometimes we don’t understand an aspect of our programming language and at other times we lack—or fail to consider—some critical information about our program’s system environment. As a result, our program will not behave correctly. What do we do now?
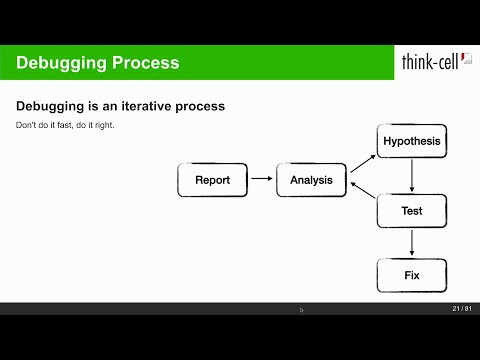
In this talk, I would like to take you through the entire debugging process, starting with a program that crashes. What do we do next? Which questions do we have to ask? What information do we need? What can we do to find the cause of the crash? Which tools can help us in this quest, and, last but not least, what can we do to make sure this bug never happens again?
Thanks to real-world examples that we have encountered—and debugged—at think-cell over the years, you will learn how to reproduce, locate, understand and fix even the most difficult bugs.
Talks on debugging techniques are relatively rare at big C++ conferences. Most debugging talks focus on specific tools, such as gdb or the time-travel debugging in WinDbg. In my talk, I want to cover the important tools as well but most importantly, I want to proceed like a developer would, starting with a program that does not perform according to its specification. I will use different examples from my almost 20 years at think-cell to illustrate my talk and make it more interactive.
1) A program crashes or experiences some kind of bug. What can we learn from a single occurrence? What information can be gathered here (e.g. stack traces, full memory dumps)?
Sometimes this may be enough to diagnose and fix a bug! It should be a best practice to look at bugs immediately when they occur on your or a colleague’s computer. It might be your lucky day and you find a bug that is easy to fix yet very hard to reproduce!
2) Typically, you need a reproduction, for example, because the observable crash is only a delayed consequence of a problem that happened much earlier in your program. There are different degrees of reproducibility from “100% reproducible in debug builds in every environment” to “sometimes reproducible but only in release builds on some machines”.
The former is of course easier to handle than the latter. But the latter probably tells us something about the bug as well and that should inform our hypotheses! And maybe there are things we can do to make the bug more reproducible. Running sanitisers might also help us here
3) With a reproduction, we can start analysing the behaviour to locate the bug. Typically, we repeatedly make hypotheses about the cause of the bug and try to test them.
This step gets easier with knowledge and experience. Depending on the kind of bug, we may need to dig very deep into the internals of our computers to find the cause of a bug. - We need to understand our programming language or learn about it (for bugs caused by uninitialised memory, out-of-scope temporaries, use-after-free bugs etc.) - We have to understand our system environment (Do we call our system APIs correctly?) - We have to understand our operating system (We interact with other programs on this level. What can they do that affects us?) - We have to understand some assembly (Compiler code generation bugs are rare but they exist. You may also interact with our libraries for which you do not have the source but which may have bugs.)
Useful tools: Disassembler, the documentation, reverse debugger
4) Fix the bug First, think of the perfect solution to the problem if time and release schedules were of no concern. This is the solution you need to strive for in long-lasting software products and—in the long term—you should implement it in your development branch. For shipping releases, the trade-off is different. A minimal fix has less chance to introduce new bugs.
5) Ensure this does not happen again, by - writing tests - changing your best practices - i.e., replace all occurrences of similar programming practices - write better library code that makes it easier for future programmers to write correct code - add more runtime asserts to catch violated invariants early - add reporting infrastructure
Advertisement
