








I'd like to thank the participants on the accu-general mailing list for the discussion that led to this paper being written, and especially Tom Hughes and Jim Hyslop for their review comments on the initial draft.
Scope
This documents provides a general overview of the use of source code version control within a software development project. It outlines the facilities required to support the development process and introduces the specific features of CVS that provide this support together with the working practices that leverage this support to best effect.
This is not a reference manual for CVS - that is at http://cvshome.org/docs/manual/cvs.html , nor is it an adequate guide to implementing CVS on a project that is at http://cvsbook.red-bean.com/ . It does, however, cover the concepts and operations most needed by a user or in short-listing version control systems prior to a detailed evaluation.
Aims and strategy
What is version control?
Fundamentally version control is about being able to manage versions of the source code. This management includes the ability to reproduce identified versions of the source code, to query differences between versions and to allow the changes made between two versions to be applied to a third.
There are significant differences between version control systems in the way they implement these facilities - at their most primitive they do no more than record a sequence of changes to individual files, at their most sophisticated they also manage the addition and removal of source file, allow concurrent changes, automate the software build process, ensure regression tests succeed, enforce sign-off processes and create and distribute the resulting software.
While much of the following discussion is generic in nature it uses CVS as a specific example of a source code version control system. CVS is a free [ GPL ] version control system that falls between the primitive and sophisticated extremes identified above: as with much 'free' software it provides a basic set of version control features important to developers and does it well. It does not provide the additional process management features available in some commercial products (but there are separate tools for some of these tasks that integrate with CVS).
What do we want from version control?
As an individual developer I want a version control system to manage the changes that I make without putting obstructions in the way of my making them. Ideally I just want to make changes to my working copy of the system and for any interaction of these with the shared development and/or release versions of the system to be resolved automatically. Within my working copy I'd like to be able to use the version control system to answer queries such as "what did I change this morning?" and to allow facilitate operations like "undo all my changes to this file" or "undo the changes I made last Friday afternoon (without losing any prior or subsequent changes)".
Some version control systems only allow a single developer to a file at a time. In practice, when version control prevents a developer from making a necessary change they bypass the version control system in order to get work done. (By changing local copies of files followed later by manual integration of their changes.) This loses potential benefits of version control, can be error prone, and risks scenarios where neither of two developers can check in their changes without first updating a file "owned" by the other.
Whether working as an individual developer, in quality assurance, or as a release manager I want to be in control of when the changes other people make impact my working copy. Ideally the version control system will allow me to choose when to update my working copy, to select specific updates and to ensure that the all the changes relating to the update are applied.
A problem that occurs with some version control systems is that they may require me to "check out" a specific version of a file - e.g. to add a method I may need to get the latest version, and this version may not be consistent with other files within my working copy.
Reworking these requirements as a checklist:
-
Track changes made by each developer (sometimes a small group of developers) in their own working copy.
-
Allow each developer to undo and/or redo selected changes within their working copy.
-
Allow developers to exchange and share selected changes between their working copies.
-
Allow each developers to change the version of files they are using (and integrate these with any other changes to the file).
-
Report the differences between different times, development versions and releases.
-
Allow QA and/or the release manager to incorporate into release versions specific work supplied by developers.
-
Reproduce the state of the release version and/or a developer's area at specific milestones and/or times.
-
Support multiple concurrent release versions.
TANSTAAFL[ Heinlein ]
I've never encountered a tool that provides the ideals outlined in the previous section without any effort on the part of the users. In particular the version control system usually needs to be informed of some types of changes, and to be asked explicitly to record or apply others. In addition, steps need to be taken to group changes that correspond to a logical update (e.g. a bug fix or new feature).
In particular, although many version control systems allow multiple developers to update a project or file, automatic merging of changes cannot always be relied on. For example it is possible for one developer to remove an unused item (file, variable or method), whilst another adds code that makes use of it. In practice, such problems can be detected automatically, either when doing the merge, by rebuilding the resulting software, or by running a smoke test [ SmokeTest ]. Once such a conflict has been detected manual intervention is invariably required to resolve it.
The following section identifies ways of working with CVS that allow the ideals to be approached.
Working with CVS
The key idea to understand when working with CVS is that the version in the repository is the important one. The user issues to update the working copy or to apply changes from the working copy to the repository. This implies that in order to track changes by individual developers separately (as described above) it is necessary for each developer to maintain a separate version of a project within CVS. The mechanism that CVS provides for this is "branching" - each branch is an independent version of the project.
Working on a branch you allows CVS to track your changes for you whilst being isolated from any other work being done at the same time. It also means your changes don't affect anyone else and you are not affected by them (unless or until you intentionally merge the changes).
Figure 1. Basic Branching
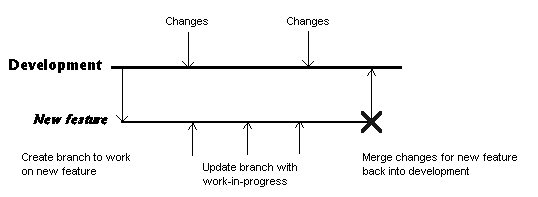
Unless the version within the repository is updated to match the working copy on a regular basis developers won't be able to use the CVS facilities to manage changes, so it is a good habit to check in changes on a regular basis - after each cycle of update, compile and test is about right (i.e. several times a day). Remember, these check-ins only affect the current branch.
The CVS branching mechanism also provides a convenient way to group changes relating to a logical update - by creating a branch for each such update allows the changes to be identified as those that occur on that branch. On completion of a logical update several things need to happen: the change must be made available for QA, the change must be integrated into the principle development version, and into any appropriate release version - this is discussed further below.
The QA and release functions have similar needs to control change (but in these cases source updates should always be applied by the version control system - not by changing the source code). For this reason they too should work on branches - although in this case the branch will, potentially, be 'handed on' from QA to release.
An example project
The project we are going to consider is the development and maintenance of an application that is maintained over a series of releases - the series of releases open ended. (I've used CVS with up to a dozen developers on projects up to a million lines of code, I've heard reports of much larger projects.)
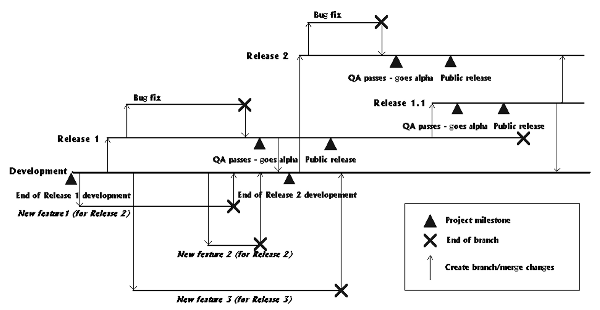
In this project the main branch (known as the trunk) is the development integration branch. Most other branches are split off this and have a limited lifetime. In particular, all development of new features is done on branches that are then merged back into the trunk.
At a given moment there are potentially two other main branches - a "Release" branch undergoing "QA" and a "Release" branch corresponding to released software. The release process is as follows:
Ensure that all bugfixes (e.g. to QA and release branches) have been merged back into the trunk.
Build the trunk and run regression tests.
Create a new Release by branching from the trunk. (Development continues on the trunk.)
Run the full test suite against the new branch. (If problems are found they may be corrected on this branch - or on branches that are merged back into it.)
Once QA "passes" the new release, any bugfixes that were made to achieve this pass are scheduled to be merged back into the trunk.
(Eventually) retire the old Release branch. (If problems are found in the field they may be corrected on this branch - and scheduled for merging back into the trunk.)
Figure 2. Branches during the project lifecycle
References
[GPL] http://www.fsf.org/copyleft/gpl.html
[Heinlein] "There Ain't No Such Thing As A Free Lunch", The Moon is a Harsh Mistress , Robert Heinlein
[SmokeTest] http://c2.com/cgi/wiki?SmokeTest
