








Object serialization provides a program the ability to read and write a whole object to/from a raw byte stream. Serialization differs subtly from persistence in that it does not handle unique object naming and location, nor does it handle concurrent access to persistent objects.
This article describes a C++ framework for object serialization. It assumes a reasonable level of proficiency with C++ streams and STL. If you are looking for a serialization method you might also read Richard Blundell's article in Overload 35 [ Blundell ] which provoked me to write this. His approach is somewhat different from mine.
The requirements
Good software systems start with a good requirements specification. The requirements for this serialization framework were reasonably clear and have shaped the solution greatly.
The following list shows the design criteria I was working to:
- The file format has to be easily extensible:
-
When new objects are added to the class hierarchy they must be easily integrated into the serialization system. As classes evolve and new states are added, they should be easily added to the file format.
- The system must be forwards and backwards compatible:
-
Earlier versions of the file format should be loadable by a later system. Obviously, all non specified elements should be set to some 'harmless' default
In the same way, later versions of the file format should be loadable by an earlier system. Serialized information for classes that do not exist in an older system, or for extended states of classes, should be ignored - perhaps with a suitable warning raised.
- The file format should be human readable, and preferably human editable:
-
There are disadvantages to this approach, most notably that files will be larger than an equivalent non-human readable (binary) format. Human editing may also introduce errors in the file (so the file parsing code must be robust). The advantages include it being useful for debugging and error recovery.
The design I describe here can also be applied to non-human readable files with appropriate tweaks. However, the file format is (at least initially) ASCII based. This is discussed in a little more depth in the Extensions section at the end.
- The system must be easy to use:
-
The method used to add serialization to a class should not be prohibitive to implement or difficult to use.
- Communication is via the C++ iostream:
-
This will ordinarily be to a file, but could just as equally be a network or serial connection, for example. By using streams the serialization mechanism will be independent of where it gets input from and puts output to.
- The output stream must be written sequentially:
-
Moving the stream position pointer is not permitted. If the stream accessed a serial connection, this kind of behaviour would simply not be possible.
Similarly, the file must be readable with a single parsing pass.
- The mechanism is to be placed in a library:
-
Therefore, it should not rely on any specific hard coded information, like the application name, version number, etc.
- The code should be portable:
-
It should work on more than one platform, because the library is going to.
- The framework should be generic:
-
It should not just be tailored to a single class hierarchy - after all that would be a waste of design effort. Resuse is good. Reuse is our friend.
I am not fashionable enough to use XML, and so concocted the following system.
File format
I started the design work by defining the file format [ 1 ] . In order to serialize a class hierarchy some kind of hierarchical file format would be needed. Something easy to parse is always helpful, too. The following is a simple example of the file format.
FILE_TYPE_IDENTIFIER
Header
{
Version-Major:100
Version-Minor:0
Originator:MyProg 3.00
OtherData:Blah
}
A
{
DataTag1:Data1
DataTag2:Data2
B
{
DataTag1:Data1
DataTag2:Data2
}
C
{
DataTag1:Data1
}
}
That looks human readable enough, but what are the rules?
- Reading the file:
-
The file is parsed a line at a time. The indentation is optional but very useful. Leading whitespace on any line is ignored.
- The first line is special:
-
The first line is a string that identifies the file type. This makes it easy to identify if a file is of the appropriate format before continuing.
The first line is the only 'special' line in the whole file. After that, the file conforms to a strict chunked format.
- Each line contains either:
-
-
A chunk identifier (string containing no spaces or colons),
-
An opening brace,
-
A closing brace,
-
A data line, "Tag:Data" (with no whitespace around the colon).
-
- Each object's data is enclosed in a 'chunk':
-
A chunk begins with an identifier line describing the chunk contents. The identifier name is only unique within the scope of its parent chunk - different chunks may have sub-chunks with the same identifiers. Following this is a line containing an opening brace. The chunk's data contents appear on each subsequent line, prior to a line containing a closing brace.
- Chunk contents:
-
The chunk's contents could be other chunks (in the same format as described above, i.e. identifier-brace-data-brace) or data presented in the format 'Tag:data'. These data lines comprise tags (which contain no spaces) whose name is local to their chunk and a data string which can be in any format, but should be human readable.
- Chunk identifiers:
-
The single string chunk identifier that precedes each chunk describes either the object or class of the chunk, depending on context.
In the example file above, the chunks B and C could be describing two distinct objects of the same class. In this kind of situation the chunk identifier describes which object's data is contained in the chunk.
The identifier may instead refer to the class of object. Consider a class which acts as a 'list' of other objects. There could be any number of these objects in the list. The example below shows how this would work
List { SomeListData:data Item { } Item { } ... } ...The 'List' chunk is parsed, and for every chunk identifier 'Item' encountered, a new object of an item class is inserted into the list.
- There is a predefined chunk, Header:
-
This should appear at the top of the file, just underneath the file type identifier. However, if it is absent then the file is not necessarily in error - how the data is interpreted will be up to the system.
The Header chunk contains a number of data lines:
- Version-Major:
-
The major version number of the file format.
- Version-Minor:
-
The minor version of the file format.
- Originator:
-
This field describes the program that created the file. It is possible to completely ignore this when reading data, but it is interesting and sometimes useful for debugging purposes. (why can't I parse this file? because program X wrote it, and got the format wrong)
- Other data:
-
Other data that may be pertinent to the whole file goes here. For example, the data I was serializing contained timestamped information. In the Header chunk I included a field that specifies the format of the timestamps. This means that if the system is later given better time resolution the older files will still be useable.
The minor and major version numbers are used together to identify the exact file format version. The minor number refers to changes that do not compromise file compatibility. Major number changes describe format changes that may break a future parser's ability to interpret the file correctly. If the major number is greater than the parser recognises, it should refuse to parse the file.
In the future it may be necessary for parsers to use this information to interpret the data in the rest of the file. This should be avoided if at all possible - it will introduce maintenance problems and decrease code clarity.
Unrecognised data
If the parser encounters a chunk identifier that it doesn't recognise, then it simply skips the chunk, perhaps raising a suitable warning along the way. Similarly, if it encounters a data tag in a chunk that is not recognised, it is ignored.
This simple rule makes the file format open, and forwards and backwards compatible.
It also allows us to make some data lines optional in their chunks. They will not necessarily always be saved, perhaps their value will assume a default or they will simply not be applicable in all situations.
These eight rules define a very simple file format. However, they are sufficient to serialise an entire class hierarchy's state and recover it easily.
The format's extensibility and openness also leads to other interesting possibilities for an application. For example, it is possible to save application choices along with data by defining a new 'Choices' chunk containing the relevant information.
How to implement the serialization system
Now we have defined the file format it is easy to write code to implement serialization using it ;-) The framework consists of an interface mixin class for objects that can be serialized and a set of classes that help read/write data.
If a class contains data that needs to be serialized, then the class inherits from the Serializable base class. The class is shown below.
class Serializable {
public:
Serializable() {}
virtual ~Serializable() {}
virtual void save(std::ostream &out,
int indentLevel) const;
virtual void load(std::istream &in,
SerializableLoadInfo &info);
protected:
static std::ostream &indent
(std::ostream &s, int level){
for(int n=0; n<level; n++) s << " ";
return s;
}
static std::omanip<int> indent(
int level) {
return std::omanip<int>
(Serializable::indent, level);
}
private:
Serializable &operator=(const
Serializable &);
Serializable(const Serializable &);
};
What is all that about? We willl take it a step at a time. First we will see how the save method is used, and then load . We will meet indent along the way.
After defining a Serializable class interface, we need to define the top-level API to the save/load mechanism. This bit will differ depending on the class hierarchy you are saving. Let us say we are trying to save a Widget which has the class hierarchy in figure 1.
We will call the serialization API class WidgetSerializer . It has a simple public API, but there is some more devious stuff going on in the private part of the class.
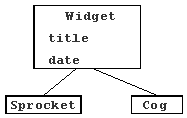
Figure 1.
class WidgetSerializer {
public:
WidgetSerializer(const std::string
&appname);
virtual ~WidgetSerializer();
void save(std::ostream &out,
Widget *) const;
Widget *load(std::istream &in);
private:
class Header : public Serializable {
public:
Header(const std::string &originator);
virtual ~Header();
virtual void save(std::ostream &out,
int indentLevel) const;
virtual void load(std::istream &in,
SerializableLoadInfo &info);
private:
std::string originator;
} header;
WidgetSerializer &operator=(const
WidgetSerializer &);
WidgetSerializer(const WidgetSerializer &);
};
This is the second class definition I've presented without a full explanation. By the end of the article we will have covered all aspects of both.
Saving
The first thing we will consider is how to save the Widget class hierarchy. After all, we cannot load anything without having first saved it.
The framework implementation will be easier to understand if we first see how to use it. The user, say an application called WidgetEditor , will create a WidgetSerializer , and use it to save a Widget to file in some function saveWidget thus:
static const std::string MY_NAME
= "WidgetEditor";
void saveWidget(const std::string &filename, Widget *widget){
WidgetSerializer serializer(MY_NAME);
std::ofstream out(filename.c_str());
if (!out) ... // error
serializer.save(out, widget);
}
In this function, and until the very end of the document I am going to conveniently ignore error handling. At this point you are free to imagine how the system will go bang.
WidgetSerializer is pretty easy to implement. Its responsibility is to save the file prologue and epilogue, and serialize the appropriate object in between. What exactly that means is best shown by implementation:
static const std::string FILE_IDENTIFIER_STRING = "WidgetFile";
WidgetSerializer::WidgetSerialiser(
const std::string &appname)
: header(appname){ }
WidgetSerializer::save(std::ostream &out,
Widget *widget){
out<< FILE_INDENTITIFIER_STRING << endl
<< "Header\n"; // (*) see below
header.save(out, 0);
// the 0 is explained below
out << "Widget\n"; // (*) see below
widget->save(out, 0);
// the 0 is explained below
// Perhaps save some application choices
// in an epilogue here
}
So all the WidgetSerializer 's save method does is ensure that the file identifier line and the header are saved, and then pass responsibility to the Widget class to serialize itself.
The key to using Serializable::save is shown at (*) above. The Serializable::save method causes an object to serialize itself as a file chunk on the given ostream . The information that it saves will consist of the opening brace line, data and the closing brace line. Specifically, the chunk identifier will not be saved. Why not?
It is the caller's responsibility to place an identifying tag line on the ostream before calling this method so that it can uniquely identify the file chunk when it has to read it back. For example, if we are saving two objects of the same class and want then to have different chunk names, then we have to write the identifier ourselves.
The save methodof the base Serializable class is defined to save an empty chunk. This is a useful default if you have not yet decided what information to save, or if that particular object has no saveable state at this point, but may have in the future.
void Serializable::save(std::ostream &out,
int indentLevel) const {
out << indent(indentLevel) << "{\n"
<< indent(indentLevel) << "}\n";
}
This simple method illustrates two more details. First, Serializable::save 's second parameter, indentLevel defines what level of indentation the chunk is being saved at. Remember, at the top level we passed 0. Second, the curious pair of protected indent methods in the Serializable class are used to perform the indentation. They are a simple means of inserting a whitespace indent when we save data into a chunk using C++ stream manipulation. It is outside the bounds of this article to describe fully how it works, however. Bjarne Stroustrup decribes the mechanism in [ Stroustrup ]
The WidgetSerializer private Header class' save mechanism is implemented as follows:
// These are defined in some suitable
// way, somewhere
static const int VERSION_MAJOR = 100;
static const int VERSION_MINOR = 0;
WidgetSerializer::Header::Header(
const std::string &originator):
originator(originator) { }
WidgetSerializer::Header::~Header() { }
void WidgetSerializer::Header::save(
std::ostream &out, int i) const {
out << indent(i) << "{\n"
<< indent(i+1) << "Version-Major:"
<< VERSION_MAJOR << \n"
<< indent(i+1) << "Version-Minor:"
<< VERSION_MINOR << \n"
<< indent(i+1) << "Originator:"
<< originator << \n"
<< indent(i) << "}\n";
}
This explains how we get the Header chunk into the file.
The final part of saving is to make the Widget save itself, and all the objects it contains. It overrides the Serializable::save method with its own version, just as Header has done above, and puts the relevant saving magic in it. To save sub-chunks for contained objects you simply write a chunk identifier line, and then call save(out_stream, i+1) on the sub-object.
For example, Widget::save may look like this:
Widget::save(std::ostream &out, int i) const {
out << indent(i) << "{\n"
<< indent(i+1)<< "Title:"<<title << "\n"
<< indent(i+1)<< "Date:" <<date << "\n";
for (int n = 0; n < no_sprockets; n++) {
out << "Sprocket\n";
sproket[n]->save(out, i+1);
}
for (int n = 0; n < no_cogs; n++) {
out << "Cog\n";
cog[n]->save(out, i+1);
}
out << indent(i) << "}\n";
}
The data you place after a 'Tag:' can be as adventurous as you want, not just int s and string s. Of course, you have to be willing to write some code to parse it back in. Which brings us neatly on to...
Loading
To make you feel better, saving was the easy bit.
We have created a file containing the serialized version of our Widget . WidgetEditor has been shut down, at some future point it is fired back up and we want to be able to edit our widget again. We now need to write a parser to read the data and reconstruct the Widget class hierarchy. That is what all those (as yet) unexplained load methods are for, naturally.
First, we will investigate the SerializableLoadInfo structure that is passed into the load methods. It looks like this:
struct SerializableLoadInfo {
int major;
int minor;
Widget *widget;
// Any other data that may be read from
// the header
};
This structure will collect information from the input file's header and allow it to be passed to each Serializable object as it parses a data chunk. The information in this structure may alter how some data in the file is interpereted.
The WidgetEditor uses the loading API in some loadFile function like this:
Widget *loadFile(std::string &filename) {
std::ifstream in(filename.c_str());
if (!in) ... // error
WidgetSerializer serializer(MY_NAME);
Widget *w = serializer.load(in);
return w;
}
The way WidgetSerializer::load is designed means that it hands back a newly allocated Widget object based upon the contents of the given file. It is WidgetEditor 's responsibility to delete the Widget when it is finished.
Again, the top-level API is nice and easy to use. So how do we implement it?
WidgetSerializer::load(std::istream, *in) {
Widget *widget = new Widget();
SerializableLoadInfo info;
info.widget = widget;
// Check first line matches file identifier
std::string id;
std::getline(in, id);
if (id != FILE_IDENTIFIER_STRING) ...
// error
// Now scan each chunk left in the file
std::tring line;
while (std::getline(in, line)) {
if (line == "Header") {
header.load(in, info);
}
else if (line == "Widget") {
widget->load(in, info);
}
else if (line != "") {
FileBlockParser parser;
parser.parse(in, info);
}
}
return widget;
}
What's that FileBlockParser thing doing there? For the moment you can happily accept that it skips an unrecognised chunk. Just how it does that and why we will see in a bit.
The parsing code ensures that the file type is correct, then reads the first chunk identifier, "Header", and directs the rest of the chunk to the parser in header's load method. So what does that look like?
void WidgetSerializer::Header::load(
std::istream &in,
SerializableLoadInfo &info){
std::string open;
std::getline(std::ws(in), open);
if (open != "{") ... // error
std::string line;
bool more = true;
while (more &&
std::getline(std::ws(in), line)){
std::getline(std::ws(in), line);
if (line.substr(0,14).compare(
"Version-Major:") == 0){
std::istrstream si(line.c_str()+14);
si >> info.major;
}
else if (line.substr(0,14).compare(
"Version-Minor:") == 0){
std::istrstream si(line.c_str()+14);
si >> info.minor;
}
else if (line == "}") more = false;
}
}
There are a couple of useful C++ standard library facilities being used here. First, std::ws(in) : it is a stream manipulator that strips leading whitespace from an input stream. Secondly, istrstream is an 'input string stream', which allows you to treat strings as streams to be read/written to. It is a type-safe way of doing sscanf .
This is the only load method in the whole Serializable framework that ever writes to the SerializableLoadInfo structure, it gets the data from the file's Header chunk.
So far we have hand written two stream parsing loops. The chunk parsing code for each Serializable object could look very similar to this. It works fine. In each Serializable class, the load method loops around, pulling out chunk identifiers and data lines and acts on them accordingly.
It is not exactly elegant, for every Serializable class we have to write another parsing loop. That is a lot of duplicated effort, which tells us that there is something wrong with the design. Add to this the problem of manual string length counting in the compares above - it is a pretty error prone way of writing code: if you get a comparison wrong the compiler will not tell you.
The solution to this is the FileBlockParser class that we breezed past earlier. The intention of FileBlockParser is to do that loop for us, to save writing it thousands of times, and to safely recognise the tags and chunk identifiers for us.
This is what it looks like:
class FileItemParser;
// a class that interprets data lines
class FileBlockParser {
public:
FileBlockParser();
void add(const std::string &name,
Serializable *block);
void add(const std::string &name,
FileItemParser *item);
void add(FileItemParser *item);
void parse(std::istream &in,
SerializableLoadInfo &info);
private:
void skipChunk(std::istream &i);
std::map<std::string,
FileItemParser*> items;
std::map<std::string,
Serializable*> blocks;
FileItemParser *catchAll;
};
The FileBlockParser 's parse method sends it scampering across the input stream a line at a time. It will expect to find an opening brace line first (just as our hand written load methods would do).
Then if it finds a chunk identifier line it looks in an internal map associating chunk names to Serializable objects. This is set up before calling parse using the appropriate FileBlockParser::add method. If the chunk identifier is not recognised, the FileBlockParser will skip the chunk (using its private skipChunk method).
If the FileBlockParser finds a data line then it will call the appropriate FileItemParser to interpret that line. If it does not recognise the tag name in its map then it will call a catch-all FileItemParser if you have added one. This may be useful in some chunks. If there is no catch-all object then the data line will be ignored.
Finally, when the FileBlockParser finds the closing brace it will stop parsing and return to its caller.
This class has taken responsibility for writing that ubiquitous loop for us. It saves us time and effort, and minimises the risk of bugs in our file parsing.
FileItemParser is a base class for objects that handle data lines. The base class looks like this:
class FileItemParser {
public:
FileItemParser() {}
virtual ~FileItemParser() = 0;
virtual void parse(
const std::string &data) = 0;
private:
FileItemParser &operator=(
const FileItemParser &);
FileItemParser(const FileItemParser &);
}
With this in mind we can implement the FileBlockParser as follows:
FileBlockParser::FileBlockParser()
: catchAll(0) { }
void FileBlockParser::add(
const std::string &name,
Serializable *block) {
blocks[name] = block;
}
void FileBlockParser::add(
const std::string &name,
FileItemParser *item){
items[name] = item;
}
void FileBlockParser::add(
FileItemParser *item){
catchAll = item;
}
void FileBlockParser::parse(
std::istream &in,
SerializableLoadInfo &info){
std::string line;
std::getline(std::ws(in), line);
if (line != "{") ... // error
bool more = true;
while (more &&
std::getline(std::ws(in), line)) {
if (line == "}") { more = false; }
else if (line.find(":")
== std::string::npos) {
// 'line' is a chunk identifier
std::map<string,
Serializable *>::iterator I
= blocks.begin();
bool done = false;
while (!done && i !=blocks.end()){
if (i->first == line){
i->second->load(in, info);
done = true;
}
i++;
}
if (!done) skipChunk(n);
}
else {
// 'line' is a 'tag:data' pair
const std::string name =
line.substr(0, line.find(":"));
const std::string data =
line.substr(line.find(":")+1);
std::map<string,
FileItemParser *>::iterator I
= items.begin();
bool done = false;
while (!done && i != items.end()){
if (i->first == name) {
i->second->parse(data);
done = true;
}
i++;
}
if (!done && catchAll) [
catchAll->parse(line);
}
}
}
}
void FileBlockParser::skipChunk(
std::istream &in){
std::string open;
std::getline(std::ws(in), open);
if (open != "{") ... // bad format
int depth = 1;
std::string line;
do {
std::getline(std::ws(in), line);
if (line == "{") depth++;
else if (line == "}") depth--;
} while (!in.eof() && depth);
}
We can easily now define the base Serializable::load method. It will ignore everything in a chunk by simply creating a FileBlockParser with no FileItemParser s. This will scan the chunk, ignore every data line and sub-chunk in it, and stop parsing after the appropriate closing brace.
This is the logical behaviour for Serializable::load since we defined Serializable::save to save an empty block. Perfectly complimentary.
Serializable::load(std::istream &in,
SerializableLoadInfo &info){
FileBlockParser parser;
parser.parse(in, info);
}
The only thing that remains to be done is define a number of FileItemParser s that implement 'Tag:Data' parsing functionality. I have implemented a number of these, some for simple integer values, some for string values, others for more elaborate data lines with several fields. The following example shows the outline of their structure. It is a FileItemParser that reads a boolean value which has been written to the output as a string (either On/Off or Yes/No).
FileItemParser_OnOff is a template class. The template type you supply is the class with the data item to modify. Making it a template saves us from having to write a version of FileItemParser_OnOff tailored to each specific accessor method of each class that needs it.
As an example class that we will be accessing, here Is the Cog class:
class Cog : public Serializable {
public:
Cog() : data(0) {}
virtual ~Cog() {}
bool data() { return _data; }
void setData(bool d) { _data = d; }
// implement Serializable interface here
private:
bool _data;
};
The member function to set a boolean value must have the signature void setXXX(bool) , like setData in Cog above. FileItemParser_OnOff contains a typedef for this member function signature, fn_t .
template <class T>
class FileItemParser_OnOff
: public FileItemParser {
public:
typedef void (T::*fn_t)(bool);
FileItemParser_OnOff(T *obj, fn_t mfun)
: obj(obj), mfun(mfun) {}
void parse(const std::string &data) {
(obj->*mfun)(data == "On"
|| data == "Yes");
}
private:
T *obj;
fn_t mfun;
};
When you create a FileItemParser_OnOff you specify the object whose value is to be set, and the member function that performs the setting.
Cog cog;
FileItemParser_OnOff<Cog>
cog_parser(&cog, Cog::setData);
We then pass the FileItemParser_OnOff to a FileBlockParser to read the block:
FileBlockParser fbp; fbp.add(&cog_parser); fbp.parse(some_istream);
Now we have a complete mechanism to load the files that have been saved. Objects can be serialised to a byte stream (probably a file) and reconstructed from the same byte stream at a later time.
Extensions
Forwards compatibility
If an earlier version of the parser sees a file saved by a later system there will be some data that it does not recognise and just skips over.
If you wanted to inform the user that this has happened but not halt the file parsing process you can add new boolean flag to the SerializableLoadInfo structure. It is initially false, but can be set to true by the FileBlockParser if it meets unexpected data. When the load is complete the parser can return the flag to the caller to handle appropriately.
Error handling
Up to this point, error handling has been conveniently ignored. You can add the error handling mechanism of your choice to the system. For it to be robust there must be some form of error handling.
I would favour raising exceptions, but have not incorporated that into the framework here for clarity, and to avoid complicating matters with exception safety concerns.
Adaptor classes
The classes to be serialized do not actually have to inherit from Serializable themselves. It is possible to create an adaptor class that acts as a serializable for a particular type of class and save its state - providing the data class' public API allows you to sufficiently capture and restore its state.
I have used both approaches with success.
Binary versions
It is not difficult to see how to convert this system from an ASCII text based approach to a binary file format. In doing so you would remove the need for text searches, comparisons, and whitespace stripping.
The advantages of doing so include reducing the file size, taking less time to write, and more importantly less time to parse. For some applications these may be big issues. Certainly, the complexity of the parsing operations increases greatly as the file size increases. This may be of particular importance when serializing an object over a network connection - the less data that needs to be sent the better.
The binary version is no longer human editable - this may in fact also be an advantage for some applications.
Conclusions
We have seen a framework for object serialization in C++. it has a simple API, and gives you a great deal of flexibility with very little implementation effort.
The files that are produced by this system are forwards and backwards compatible. The file format is human readable, and editable. New Serializable classes can be added easily to the system with very little effort since the framework is already in place for them.
References
[Blundell] Richard Blundell. Automatic Object Versioning for Forward and Backward File Format Compatibility. Overload 35 , Jan. 2000.
[Stroustrup] Bjarne Stroustrup. The C++ Programming Language. 3ed. Addison-Wesley, 1999. pp 631-636 ISBN: 0-201-88954-4.
[ 1 ] Of course, the stream may not go to a file, but more often than not will.
