








In this article I attempt to document some problems encountered when evolving objects are serialised to and from persistent storage. I also describe a class that allows backward and some degree of forward compatibility of file formats to be attained automatically.
Object evolution and file formats
Systems and objects evolve. Most projects will have to face the problems arising when object persistence (or serialisation) and object evolution meet. Whether you are writing and reading a system to a file, or streaming objects across process boundaries, you need to know how to write out your objects in a binary representation, and you then need to know how to read them in again. When writing, this is usually an easy call: just write out all you know about the object's state - its attributes. When reading, you need to be able to determine the schema used when the object was saved, and take appropriate action if this differs from the current schema. In this article I shall discuss serialising objects to files, but similar arguments can be applied to other forms of object packaging/unpackaging, such as preparing objects to be squirted across a network.
Objects are typically composed of attributes that are either built-in types or other objects (or references to these) [ 1 ] . As objects evolve, they may gain new attributes, or existing attributes may become obsolete (changes of use of attributes can be considered as making the old one obsolete and adding the new).
In some evolving systems there may be no requirement to be able to read files written with a different version of the software. In other cases, one-off batch upgrade processes might be invoked to upgrade all data from the previous format to the new format. In many systems, however, it if often necessary, or at least desirable, to provide some form of backward and possibly forward compatibility in each version of the system. This provides users with the greatest flexibility, at the expense of often considerable work for the developers.
In this article, by backward compatibility I mean that the current version of the software will be able to read old files stored by some or all earlier versions of the same software using previous object schemas. By forward compatibility I mean that in a heterogeneous environment where different versions of the software are being used concurrently, files saved by a later version can be read by earlier versions, as long as it makes sense to do so. If files are resaved using the earlier version then future additions will be lost and the file will be saved in the earlier file format. Note that I am not considering the ability to save a file in an earlier format. In fact, this becomes unnecessary if forward compatibility is supported.
The traditional solution
A common technique used to address schema evolution is to have a "reserved block" at the end of an object, typically of the form:
class person {
shoe_size ss;
char reserved[20];
};
To allow for some future expansion, a predetermined amount of unused space is added at the end of each object. If we decide that our person class could do with some extension, new attributes can be added. The reserved space shrinks to keep the size of the object the same, which in turn simplifies object serialisation.
There are a number of problems with this technique.
A lot of space can be wasted, depending on how much room you allow for future growth.
If you want to add more attributes than you left space for, you're stuck.
If you inadvertently forgot to initialise your reserved space, then you might not be able to use it anyway if you can't tell between a new attribute and garbage in the reserved block.
Even if you remembered to initialise it, you may need to encode future attributes if the values you initialised the block to are valid non-default attribute values. (E.g., if you want to store a new integer attribute, with -1 denoting the default or missing value, and your block was initialised to zero, you'll have to add one to the attribute values when storing).
Other solutions
Other possibilities include adding version numbers to the file. Earlier software versions can then simply refuse to open the file, and later software versions can determine which parts of each object should be present in the file based on the stored version number. For finer grained control, some or all objects can additionally use their own version stamp.
The main drawback with this approach is that large amounts of conditional code can build up in the serialisation methods to take each generation of file format into account. This leads to spaghetti code and major problems with system maintainability and extensibility. Errors can often be introduced into such complex legacy code quite easily, and testing is complicated because normal use of the software with current file formats does not exercise much of this compatibility code.
Furthermore, if attributes must be removed from objects, dummy attribute values are often left in the file in perpetuity because of the extra burden of further checks, etc., in the already complicated serialisation code, leading to more wasted space and more potential errors.
Self-describing file formats
One solution to these problems of schema evolution is to store the schema in the file alongside the data. If the system metadata is stored in the file in addition to its data, then the file can be read in exactly as intended. This is because you can always tell what data values are present in the file.
XML allows this to be taken one step further. XML defines a standard file format for data and metadata (ASCII, tags, etc.). It also defines a format for the meta-metadata (data describing the metadata) in the Document Type Definition. An XML parser can therefore read any XML file, even if it has no comprehension of the business domain and objects that the file describes. Even though XML is becoming more widespread and easier to use through public-domain parsers, standard binary files or homegrown file formats are ubiquitous [ 2 ] . A simple method for tackling schema evolution problems in these files is required.
Object sizes as a discriminator of object content
In many cases (although not all), the size of an object gives a good idea of its version, and hence its contents. As bits get added to an object, the increase in size can be used to determine whether we have an earlier or later version of the object on file. If we reach the end of the data on file before we have finished initialising our object, we can stop reading, assign default values for any attributes that have not yet been read, and continue with the next object. Similarly, if we have read all the attributes we know about, and there is still more data on file, we know we must be reading a later version of the file, and we can skip over this additional data. For simple fixed size objects, this is quite a common technique - simple structs are sometimes written to storage preceded by their binary size. This size is used as a primitive version stamp.
One problem with this technique is that it is often difficult to calculate the size of complex objects in advance. Complex objects often contain sub-objects, so any size computation needs to iterate around all attributes and sub-objects. An additional size() method can be added to all objects, to enable the filing subsystem to make records of object sizes in the file. This is somewhat intrusive, however. It can also be error-prone. If the size calculation in any one class has errors, or if the size methods are not updated when persistence methods are modified, then the resultant mismatch can produce filing errors that may not surface for some time.
A class to automatically calculate object sizes
What we would like is a class that can automatically calculate object sizes without any knowledge of the object itself. Such a class would make object versioning really easy to implement. There would be no need for intrusive size() methods in every object, and calculations cannot get out of step when object schemas change.
The technique I used to do this was to utilise the file stream itself to calculate any given object's size. This way, the size is guaranteed to be right - as long as you can measure how much data you have written to the stream. It does not matter if strings are stored preceded by their length, or are null-terminated, or whether an integer is stored as binary data or as ASCII text. By measuring our progress reading through the file we can determine automatically whether there is more to read or if we have hit the end of the object's data.
Strategy
Details of the actual algorithms used are given with the implementation in the next section. Basically I precede each object's data in the file with its size as in figure 1.
I call this grouping of size and state on file an object block. For compound objects, each nested object has its own object block, complete with its size, so that it can be independently extended as it evolves, and the parent object block has a size that takes into account the sizes of all the nested blocks.

Figure 1. How an object's attributes are stored, preceded by their size, in an object block in a file.

Figure 2. How a compound object block is stored in a file. The first size is that for the entire compound object; the second is that for just the sub-object.
Abstracting the file system
Not everyone uses CArchive / CFile , or any other single file type, for persistence. Furthermore, developers are often reluctant to change the classes that they currently use for filing. To provide some degree of portability, I abstracted the filing system away behind a primitive file interface. This interface requires only basic filing facilities - reading and writing an object size, determining the current file position, and seeking to a given file position. An adapter class can thus be written for any filing classes that support these basic facilities. An example of such an adapter class is given later.
I have used typedefs for the basic concepts of a file position ( file_ptr ) and an object size ( file_diff - the difference between two file positions). This allows you to change these to suit your current system if necessary. In the example below I have used size_t for both of these.
Note that the interface requires seeking to calculated positions (and not just positions that have previously been queried). This may prove problematic if your system does not allow true byte-level random access.
typedef size_t file_ptr;
typedef size_t file_diff;
class file_T
{
public:
virtual bool is_writing() = 0;
virtual void seek(file_ptr pos) = 0;
virtual file_ptr position() = 0;
virtual void read(file_diff &size) = 0;
virtual void write(file_diff size) = 0;
};
The is_writing() method returns true if the file is being written to, or false if it is being read. I tend to use a single method for object persistence. This aids conciseness, gives me a single function to maintain, keeps related code together, avoids code duplication, copy-and-paste errors, etc. I wanted a single interface to be able to handle both writing and reading, even if you decide to use save/load pairs of persistence methods. The beauty of using an interface and adapter classes is that the adapter classes can take care of and hide these details.
Implementation
To avoid too much line wrapping, I have stripped comments from the code and provided commentary in the text. Methods have also been made inline to save column inches. All the usual disclaimers apply!
The class interface is shown first. My class is called object_size_handler - a bit of a mouthful, but descriptive. The three important methods are as follows. First, the ctor allows an object to be created and attached to a given file_T file interface. Second, the more() method is used to determine if there is more data when reading an object from file. Finally, the dtor calculates object sizes, and repositions the file pointer as necessary.
class object_size_handler
{
typedef object_size_handler my_T;
public:
explicit object_size_handler(file_T &f);
~object_size_handler();
bool more() const;
// is there more to read?
file_T &file() const {return m_file;}
private: // Not implemented - no copying!
object_size_handler(const my_T ©);
object_size_handler
&operator=(const my_T &rhs);
private:
file_T &m_file;
file_ptr m_offset;
};
To help describe the implementation of these methods, let's consider separately the cases of writing to, and reading from, the file.
The ctor is shown below. On writing to the file, it stores a dummy object size (since it has not calculated it yet), and remembers the position of the start of the object's data. On reading, it reads the stored object size, and from that and the current file position it determines the file position where the object ends.
object_size_handler::
object_size_handler(file_T &f)
: m_file(f), m_offset(0){
if (m_file.is_writing()) {
m_file.write(file_diff(0));
m_offset = m_file.position();
} else {
file_diff size;
m_file.read(size);
m_offset = m_file.position();
m_offset += size;
}
}
The dtor performs the end-of-object operations. On writing, it determines the current file position (where the object has ended), subtracts the start-of-object position that was stored by the ctor, and so determines the object size automatically. It then seeks back to just before the start of the object and writes the size there. On reading, it simply seeks to the end of the current object, skipping over unread data.
object_size_handler::~object_size_handler()
{
if (m_file.is_writing()) {
file_ptr end = m_file.position();
file_diff size = end - m_offset;
m_file.seek
(m_offset - sizeof(file_diff));
m_file.write(size);
m_file.seek(end);
} else {
// if (more()) set_skipped_flag();
m_file.seek(m_offset);
}
}
The commented out line allows a check to be made for data that has not been read in. This data would be lost if the file were later resaved. This is discussed in more detail in the "A possible extension" section, below.
Finally, the more() method checks to see if we have reached the end of the object's data when reading. It just returns true when writing (to allow symmetrical persistence methods). I have used multiple returns in this short method - use a local variable and a single return if you prefer.
bool object_size_handler::more() const
{
if (m_file.is_writing())
return true;
else {
file_diff remaining =
m_offset - m_file.position();
return remaining > 0;
}
}
Example of usage
If this is all a bit confusing (or confused!), then an example should clarify things. Consider a class, A, that we wish to serialise. Let us assume that A originally had just one sub-object. As the system evolved, however, another attribute was added, and in the current version (V3) of the software it has three components. We would like to be able to read files in any of the three available formats, using any of the three versions of the software.
The code below shows how this is achieved. It uses the Microsoft Foundation Classes' persistence mechanism, in which a single "Serialize" method receives an object of type CArchive . Serialize() methods are symmetrical, and either write or read data depending on a flag internal to the CArchive object.
If all files were written and read in the latest format, the Serialize() method would write or read all three sub-objects like this:
void A::Serialize(CArchive &ar)
{
// Read and write version 3 file format
m_original_data.Serialize(ar); // always have this
m_new_data.Serialize(ar); // added in V2
m_even_newer_data.Serialize(ar); // added in V3
}
To allow full forward and backward file compatibility, all we need to do is make the following changes. First of all we need to create an adapter object (of class archive_adapter ) to wrap up the CArchive object. This wraps CArchive and realises the standard file_T interface. Next we instantiate an object_size_handler object to manage the size and versioning of our A object. Finally, we just serialise out attributes as normal, checking the presence of each one using the more() method.
void A::Serialize(CArchive &ar) {
archive_adapter f(ar);
object_size_handler object_size(f);
// All versions have this
m_original_data.Serialize(ar);
// Only later versions have this
if (object_size.more())
m_new_data.Serialize(ar);
// Only really new versions have this
if (object_size.more())
m_even_newer_data.Serialize(ar);
}
The simplicity of the above code belies a lot that is going on beneath the surface. Let's consider writing first, and then look at reading.
When writing, the object_size_handler ctor writes a dummy (zero) size onto the stream and records the file position where the object starts. All the more() methods return true during writing, so all three sub-objects are serialised to the stream. Finally, the object_size_handler object goes out of scope. The dtor reads the current file position. From this end position and the known start position, the object size can be calculated and written at the start of the object block.
On reading, the object_size_handler ctor reads the size of the stored data. A's sub-objects are restored from file, but this time each call to more() checks the file position against the known end-of-object position. If there is no more data, more() returns false, and no more attributes are read from the file (because they are not there!). When the object_size_handler goes out of scope, the dtor fires, which ensures the file pointer is positioned correctly at the end of the object's data, perhaps after a fourth sub-object written by a future version of the software.
All these seeks, and rewriting of the object size should not incur too much overhead, because in most filing systems i/o is buffered. This actually means that rewriting the size at the start of the object will most probably not require the physical disk to rewrite the data, unless the object is so large that the buffer has been flushed mid-object.
A peculiarity of the CArchive class requires some special handling in the adapter class. CArchive contains a CFile object, which is responsible for writing data to disk. However, not only is CFile buffered, but also, so it seems, is CArchive - a double layering of buffers. This means that you can check the file pointer of the underlying CFile object, write something to the CArchive object, check the file pointer again and find that it has not changed! When direct access is required to the underlying CFile object (in this case for the Seek() and GetPosition() calls) it is necessary to synchronise the CArchive object and the CFile object. This highlights another advantage of interface programming and the use of an adapter class. All these implementation details (i.e., mess) can be encapsulated within the adapter class, with clients (in this case the object_size_handler ) blissfully unaware of these complications.
Here is the archive_adapter class:
class archive_adapter : public file_T
{
public:
archive_adapter(CArchive &ar)
:m_ar(ar) {}
virtual bool is_writing()
{return m_ar.IsStoring() != FALSE;}
virtual void seek(file_ptr pos)
{
sync();
m_ar.GetFile()->Seek(pos,
CFile::begin);
sync();
}
virtual file_ptr position()
{sync(); return m_ar.GetFile()->GetPosition();}
virtual void read(file_diff &size)
{m_ar.Read(&size, sizeof(file_diff));}
virtual void write(file_diff size)
{m_ar.Write(&size, sizeof(file_diff));}
private:
void sync() {m_ar.Flush();}
private:
CArchive &m_ar;
};
A possible extension
By adding a flag that is reset when a file is initially opened, and which is set whenever the dtor skips over some unread attributes [ 3 ] , a check can be made to see if any attributes, stored in a later version, would be lost if the file were rewritten. This allows the usual warning ("some changes may be lost") to be displayed when appropriate, but avoided when no additional attributes were found (and hence can't be lost!).
Similarly, if more() returns false during a read operation, we may be able to determine that the file was using an earlier schema. If the user attempts to resave the file, we could in principle warn that the file format would be updated in the process. This may well be unnecessary, however, given that we are now forward compatible - the earlier version of the software will be able to read the later file format anyway.
Other benefits
An added benefit of the automatic size checking is that optional attributes can easily be stored at the end of an object. When reading, attributes present will be read, and the absence of additional attributes can be checked for. When writing, attributes that are defined but which have their default values need not be stored in full, because the default values can be assigned when their absence is noted when the file is loaded.
The only overhead for these facilities is the space for an object size (typically four bytes, holding the value 'zero') in place of any missing object or block of attributes (see figure 3).
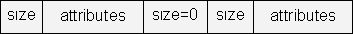
Figure 3. A missing attribute stored as a zero size
An empty block containing an object_size_handler object will skip over an obsolete object in the file (and will generate an empty object block on writing). A helper class can be defined to allow such obsolete attributes to be skipped easily:
class skip_object
{
public:
skip_object(file_T &f)
{object_size_handler osh(f);}
};
The object_size_handler object is created and goes out of scope again in the ctor. Its scope is therefore just the period whilst the skip_object object is being constructed. It can be used as follows:
// ... m_attribute1.Serialize(ar); skip_object skip_this_one(object_size.file()); m_attribute2.Serialize(ar); // ...
Conclusion
If you are serialising a system of objects, if your objects tend to grow over time as new attributes are added, and if it makes sense for later versions of your software to be able to read files saved by earlier versions (by calculating missing attribute values, or using safe defaults, and ignoring obsolete attributes), then the object_size_handler class offers an extremely low-overhead solution to backward compatibility.
If, it makes sense for earlier versions of the software to read files saved by later versions (it is acceptable to simply ignore newer object attributes stored by the later version and assume default values for attributes that have subsequently become obsolete), then this class offers a zero-overhead solution to forward compatibility. The class can also determine if information would be lost when resaving a file.
Finally, the use of an abstracted file interface allows the object_size_handler to be used with virtually any random-access persistence mechanism - C files, C++ streams, file classes in third-party class libraries, etc. (with the proviso about seeking to calculated file locations).
[ 1 ] Less frequently they can contain no attributes (for stateless objects), or can contain function pointers, etc. Here I consider enums to be equivalent to built-in integral types.
[ 2 ] There are also times when a file format that is not easily human-readable is advantageous.
[ 3 ] see the commented-out line in the implementation given.
