








Traditional queues collect every event. Ajay Pandey shows how a coalescing queue can avoid redundant updates while keeping relevant state.
High-frequency event-driven systems often ingest more updates than downstream components can usefully process. A conventional FIFO queue preserves every event, but that can be the wrong abstraction when the consumer ultimately needs a current view of state rather than a complete history of every intermediate transition. This article describes a coalescing event queue: a design pattern that buffers events over short, bounded time windows and applies explicit merge policies to reduce redundant updates while preserving the most relevant state. The design uses a multi-producer, single-consumer concurrency model, key-based coalescing, policy-driven merge rules, and a decoupled dispatch layer. A C++ sketch illustrates how the queue can be implemented with clear ownership, bounded synchronization, and extensible merge semantics.
The problem with treating every event equally
Many systems are built around the assumption that every event should be queued, preserved, and processed in arrival order. That is a reasonable default for audit trails, ledgers, command streams, transactional pipelines, and any workflow where the complete sequence is semantically important.
It is not always the right default.
In a large class of high-frequency systems, producers emit repeated updates for the same logical entity. A device reports its current status. A service reports its current health. A distributed component publishes its latest state. A measurement source emits another reading for the same key. If ten updates for the same key arrive in a short interval, the downstream component may not need all ten. It may only need the latest value, or perhaps a small aggregate derived from the interval.
A FIFO queue cannot express that distinction. It treats an obsolete intermediate update and the current update as equally important. Under burst load, that can create several problems:
- queue growth caused by redundant intermediate state;
- rising end-to-end latency;
- wasted serialization, dispatch, and processing work;
- consumers observing stale values because they are still draining old updates;
- unpredictable tail latency during bursts.
The central observation behind a coalescing queue is simple:
In many high-frequency systems, state convergence matters more than event completeness.
The goal is not to process less because correctness is unimportant. The goal is to encode the correct notion of importance. If a newer update supersedes an older one, the system should be able to say so explicitly.
Coalescing as queue semantics
An event coalescing queue temporarily stores incoming events for a bounded time window. During that period:
- coalescing queue groups related events based on their logical key, and
- a coalescing queue applies a merge policy to combine older updates with newer state transitions, thereby reducing redundant intermediate events.
Design questions to consider are the following:
- Key selection: How is it determined that two events can be coalesced?
- Coalescing strategy: In case there is a common key among events, how should they be coalesced?
- Flush strategy: At which point should buffered events be flushed?
- Concurrent publish strategy: How can several publishers publish messages to a queue to avoid complexity for concurrent coalescing?
- Exceptions: The reasons why messages will not participate in the coalescence process. Basically, events that will bypass coalescing logic.
There are several ways that could be considered here, starting from a simple winner-take-all approach, in which case if there was a message buffered for a key, all incoming messages for this specific key were ignored. Also, other approaches could be considered, such as aggregation, keep last, merge fields, and batching.
This is not just optimization of a regular process; this is a completely new contract for our queue. Whereas a FIFO guarantees only proper message ordering, a coalescing guarantees a certain level of state propagation with limited latency.
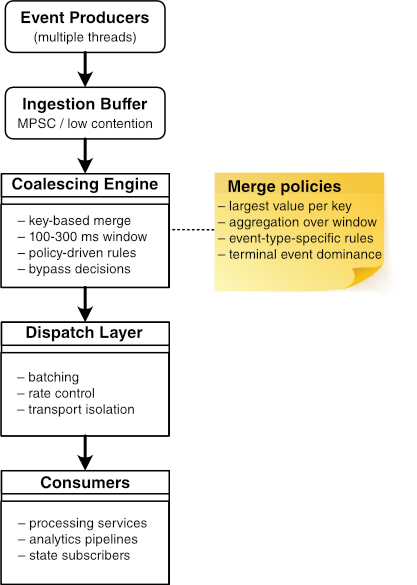
System architecture
A typical coalescing queue has four layers: event producers, an ingestion layer, a coalescing engine, and a dispatch layer. Event producers are listed as part of the overall architecture, but they are usually outside the queue implementation itself.
Event producers produce events concurrently, and an ingestion component receives events. The coalescing engine manages the pending state of the coalesced events according to a defined merge policy for the events having the same logical key. Finally, once events get processed, the dispatch component sends them for processing further downstream.
It is critical to have the separation between ingestion, coalescing, and dispatch components. Producers must not be blocked by expensive processing tasks. The coalescing engine must manage its pending state clearly. Dispatch must be independent of merge logic to prevent transport-specific implementation affecting the coalescing process.
Figure 1 shows the coalescing event queue system architecture.
 |
| Figure 1 |
Choosing the concurrency model
The concurrency model should simplify the most difficult aspect of the design: merge correctness. A practical default approach is a multi-producer, single-consumer model in which multiple producer threads invoke enqueue() while a single worker thread owns the pending state map and executes merge policies. Dispatch operations occur outside the producer path so that downstream processing does not interfere with event ingestion. This approach provides two major advantages. First, producer-side operations remain short and predictable, helping maintain stable ingestion latency under burst traffic. Second, merge state ownership remains centralized, reducing the risk of subtle race conditions during policy evaluation.
There are different ways to realize such an implementation approach. A system can either protect the pending map with a mutex, protect the vector with a mutex but use indexing by keys, utilize an MPSC queue processed by a dedicated consumer thread, or work with the lockfree ring buffer that supplies the events to a single coalescer. The implementation example provided uses standard C++ constructs just to demonstrate the essence of design rather than get involved in optimizations. Later on, in a production use case, the ingress path might be implemented using lock-free constructs.
A C++ implementation sketch
The next implementation is deliberately designed to serve as a high-level conceptual design of the library in question. The main aim is to outline ownership rules, merge logic, and concurrency strategies.
In order to implement three central ideas, three classes are introduced.
Event structure
The Event structure serves as the basic structure that will be processed by the coalescing queue. In practical use cases, the events will have IDs, data, timestamps, statuses, or other information necessary for the coalescing queue to know how the updates need to be coalesced. The simplified version of the event structure utilized within this document was made with the intent of providing just the basic pieces needed to show coalescing based on keys and how to apply merge policies to the update process.
struct Event {
using Key = std::string;
Key key;
std::string payload;
bool bypass_coalescing = false;
};
“Latest value wins” merge policy
The LatestValueWins structure is an example of a merge policy functor. Ownership transfer is achieved via passing-by-value of the newer event because it is intentional that the ownership transfer process should be made efficient for merging processes. This enables the merge policy to perform the necessary payload transfer when needed.
The MergePolicy describes a strategy according to which two events with identical keys will be merged together.
struct LatestValueWins {
Event operator()(Event const& older,
Event newer) const {
return newer;
}
};
Coalescing queue implementation
The CoalescingQueue handles the processing part, including buffering events and merging them.
The helper function upsert_locked() uses the common upsert convention: it inserts a new pending event when the key is not present, or updates the existing pending event when the key is already present.
See Listing 1.
#include <chrono>
#include <condition_variable>
#include <functional>
#include <mutex>
#include <string>
#include <thread>
#include <unordered_map>
#include <vector>
template <typename MergePolicy,
typename Dispatch>
class CoalescingQueue {
public:
using Clock = std::chrono::steady_clock;
using Duration = Clock::duration;
CoalescingQueue(Duration window,
MergePolicy merge_policy,
(Dispatch dispatch)
: window_(window),
merge_policy_(std::move(merge_policy)),
dispatch_(std::move(dispatch)),
worker_(&CoalescingQueue::run, this) {}
// A queue owns a live worker thread and
// synchronization state shouldn’t be
// accidentally copied or moved.
CoalescingQueue(CoalescingQueue const&)
= delete;
CoalescingQueue& operator
=(CoalescingQueue const&) = delete;
CoalescingQueue(CoalescingQueue&&) = delete;
CoalescingQueue& operator=(CoalescingQueue&&)
= delete;
~CoalescingQueue() {
close();
}
void enqueue(Event event) {
std::vector<Event> immediate;
{
std::lock_guard<std::mutex> lock(mutex_);
if (closed_) {
return;
}
if (event.bypass_coalescing) {
immediate.push_back(std::move(event));
} else {
upsert_locked(std::move(event));
}
}
if (!immediate.empty()) {
dispatch_(std::move(immediate));
}
cv_.notify_one();
}
void close() {
{
std::lock_guard<std::mutex> lock(mutex_);
if (closed_) {
return;
}
closed_ = true;
}
cv_.notify_one();
if (worker_.joinable()) {
worker_.join();
}
}
private:
void upsert_locked(Event event) {
auto iter = index_.find(event.key);
if (iter == index_.end()) {
auto position = pending_.size();
index_.emplace(event.key, position);
pending_.push_back(std::move(event));
return;
}
auto& existing = pending_[iter->second];
existing = merge_policy_(existing,
std::move(event));
}
std::vector<Event> take_pending_locked() {
std::vector<Event> result;
result.swap(pending_);
index_.clear();
return result;
}
void run() {
std::unique_lock<std::mutex> lock(mutex_);
while (true) {
cv_.wait(lock, [this] {
return closed_ || !pending_.empty();
});
if (closed_) {
break;
}
cv_.wait_for(lock, window_, [this] {
return closed_;
});
auto batch = take_pending_locked();
lock.unlock();
if (!batch.empty()) {
dispatch_(std::move(batch));
}
lock.lock();
}
auto final_batch = take_pending_locked();
lock.unlock();
if (!final_batch.empty()) {
dispatch_(std::move(final_batch));
}
}
Duration window_;
MergePolicy merge_policy_;
Dispatch dispatch_;
std::mutex mutex_;
std::condition_variable cv_;
bool closed_ = false;
std::vector<Event> pending_;
std::unordered_map<Event::Key, std::size_t>
index_;
std::thread worker_;
};
|
| Listing 1 |
Example usage
Listing 2 is an example of usage. After the coalescing window expires, the dispatched batch contains only the latest event for component-a.
auto dispatch = [](std::vector<Event> batch) { // Serialize and forward the reduced batch. }; CoalescingQueue queue{ std::chrono::milliseconds{200}, LatestValueWins{}, dispatch }; queue.enqueue(Event{.key = "component-a", .payload = "state=starting”}); queue.enqueue(Event{.key = "component-a", .payload = "state=ready"}); queue.enqueue(Event{.key = "component-b", .payload = "load=0.72"}); |
| Listing 2 |
Commentary on the design
The most important characteristic of this implementation is not raw performance. The important property is that the queue semantics remain explicit and understandable.
Merge policy injection
The queue itself does not need to understand application semantics. The merge policy decides whether events should be replaced, aggregated, merged field-by-field, or preserved based on lifecycle state.
For example, a terminal-state-preserving policy might look like this:
struct TerminalStateDominates {
Event operator()(Event const& older,
Event newer) const {
if (older.payload == "state=closed") {
return older;
}
if (newer.payload == "state=closed") {
return newer;
}
return newer;
}
};
In production systems, merge policies would typically operate on strongly typed event fields rather than parsing string payloads.
Dispatch outside the lock
The worker thread extracts pending state, clears internal structures, and releases the mutex before dispatching downstream. This separation is essential because dispatch operations may involve serialization, transport I/O, allocation, or external callbacks.
Holding queue locks during dispatch would couple producer latency to downstream performance and significantly reduce scalability.
Explicit bypass semantics
Not every event should be coalesced. Certain events represent commands, audit records, lifecycle transitions, or non-idempotent operations.
The bypass_coalescing flag demonstrates one possible mechanism for preserving such events independently from coalesced state updates.
Graceful shutdown
The destructor invokes close(), allowing the worker thread to drain pending events before shutdown. Without this behavior, the final coalescing window could be silently lost.
Merge policy comparison
Different merge policies encode different notions of correctness (see Table 1).
|
||||||||||||||||
| Table 1 |
These policies demonstrate that coalescing is not simply about dropping events. It is about applying explicit semantics to determine which representation of state should survive within a bounded window.
Aggregate policy example
An aggregate policy may compute summary statistics such as averages, counts, sums, or minimum and maximum values. (See Listing 3.)
struct NumericEvent {
std::string key;
double sum = 0.0;
std::size_t count = 0;
};
struct AverageOverWindow {
NumericEvent operator()(NumericEvent older,
NumericEvent newer) const {
older.sum += newer.sum;
older.count += newer.count;
return older;
}
};
double average(NumericEvent const& event) {
return event.count == 0
? 0.0
: event.sum / event.count;
}
|
| Listing 3 |
The identical input sequence may result in different output sequences based on the merge policy chosen. For example, consider a series of events corresponding to the same key arriving in the same coalescing window in the following order: K:10, K:20, K:30, followed by K:closed. With the Latest Value Wins approach, the final state K:closed will be kept because it replaces each preceding state with a new one.
The Terminal State Wins policy, however, will maintain the K:closed state for a different reason, as terminal lifecycle states are purposely shielded from overwriting by future nonterminal events. If the Aggregate Over Window approach is adopted, the numeric events will be aggregated into a single summary representation, K:count=3, avg=20.
This example clearly illustrates one of the essential guidelines: merge policies must be designed based on event semantics rather than just the shape of the event.
Performance characteristics
The practical impact of coalescing becomes visible under sustained high-frequency workloads.
Table 2 is a theoretical representative rather than absolute, but it illustrates the key property of coalescing: system cost becomes state-driven rather than event-volume-driven.
|
||||||||||||||||||||||||||||||
| Table 2 |
Window size and latency
The coalescing window is the first line of defense when considering latency/throughput tradeoffs. With smaller windows, there will be lower queue delays but fewer opportunities for merge reduction. With large windows, merge efficiency is better during traffic bursts, albeit with higher propagation latency. Hence, the ideal window size is determined by several criteria, such as the degree of input volatility, freshness needs downstream, queue delay tolerance, and efficiency of merge. Moreover, the coalescing queue should not be taken as a black box but be measured appropriately. For instance, useful performance metrics are event acceptance count, emission count, replacement count, bypass count, flush frequency, distribution of batches, dispatch duration, and queue drain characteristics.
Backpressure and capacity management
While coalescing helps reduce pressure downstream, it does not address the issue of capacity management.
The memory usage of a coalescing queue depends mainly on the number of keys that are active in the coalescing window and not on the number of events being processed. Since all events with a common key get coalesced, there cannot be more than one pending item per key.
There is one major benefit that coalescing queues offer over a FIFO approach. However, a workload involving very large numbers of keys may still pose problems with respect to memory pressure.
Some common methods of managing capacity are to reject events and create backpressure, to drop only lossy events, to flush earlier due to increased internal pressure, to distribute keys across several coalescers, or to spill important events to durable storage. The correct method would depend purely on event semantics.
Ordering guarantees
Coalescing disrupts standard semantics of queue ordering.
The example above maintains ordering for the first appearance of the key in the context of a coalescing window. For instance, if there is a sequence of key A, followed by key B, followed by A, then the output order will be A, B, and the data of A will be updated in place.
Other implementation options would delete the original A and enqueue the new version of the event to the end of the batch.
Neither implementation works in all cases. The critical part is to document the guarantee on the queue explicitly.
It should be clear which type of ordering a coalescing queue provides: does it provide the latest value of a key? The initial position of the key during its lifetime in the window? Latest position? Terminal lifecycle state? Aggregations of many events? The whole set of events?
Documenting the semantics explicitly is crucial since the consumer of this queue might get the wrong idea about what is going on with the queue and how it works.
Scaling the design
The single-worker model is often sufficient because expensive downstream work has already been reduced through state convergence.
If a single coalescer starts lagging or becomes too slow, the next step is partitioning by key:
partition = hash(key) % number_of_partitions;
Each partition maintains its own queue, worker thread, pending map, and dispatch path. Partitioning introduces several trade-offs. Uneven key distribution may create hot partitions, cross-key merge policies become more difficult, ordering guarantees become partition-local, and shutdown and observability become more complex. For this reason, partitioning should generally be introduced only after measured contention.
When not to coalesce
Coalescing should not be done if each and every event is meaningful on its own.
The examples include auditing logs, accounting transactions, legal documentation, control data, event sourcing implementations, cumulative counts, and exact replay processes.
Another design error would be doing coalescing at too low a level in the infrastructure stack where the system cannot ascertain if merging these events can be safely performed.
Advanced variations
The basic design can be extended in several ways.
- Adaptive Windows: In case of bursts, the coalescing window could grow, whereas for steady state operation, the window size could shrink. Such an approach would enhance the efficiency of coalescing but make it harder to predict latency.
- Priority Flush: Important high-priority events, or certain terminal events, could result in immediate flushing instead of waiting until the expiration of the whole coalescing window. This would allow for immediate propagation of significant lifecycle changes or events.
- Structured Merge Policies: Rather than merging unstructured data payloads, structured event types with explicit properties, such as timestamps, sequence numbers, severity level, or lifecycle state, are used in practice. These structured event formats simplify the implementation of merging policies and preserve semantic details in coalesced data.
- Lock-Free Ingestion: To support extremely high throughput of events, producers would publish events directly to a lock-free MPSC queue, and a separate worker would drain that queue and insert events to the private merge map.
This ensures minimal producer interference along with maintaining the single-owner merge semantics.
Testing the coalescing queue
A coalescing queue should be tested at both the semantic and concurrency levels. The first group of tests should verify merge behavior. For example, a LatestValueWins policy should emit only the newest event for a key within the window, while a terminal-state policy should preserve terminal states even when later non-terminal updates arrive. These tests should use deterministic inputs and short controlled windows.
The second group of tests should verify flush behavior. Tests should confirm that pending events are emitted after the configured window, that bypass events are dispatched immediately, and that shutdown drains any remaining pending events. These cases are important because most correctness bugs in coalescing queues occur at timing boundaries.
Concurrency tests should run multiple producer threads that call enqueue() while a single worker drains the queue. The expected result is not necessarily FIFO ordering of every event, but preservation of the documented coalescing contract. Stress tests should also measure whether events are lost during close, whether duplicate keys are merged correctly under load, and whether dispatch occurs outside the queue lock.
Conclusion
A coalesced event queue is applicable where there are frequent updates being generated by a system but where downstream consumers only care about the current state and not every step in between.
This architecture should not be mistaken as a substitute for FIFO queues, persistent logging, and event sourcing. Rather, it’s an alternative approach that works better with state-based operations.
One of the key decisions in implementing this system is making sure that the semantics of the merger are explicitly known. After the merger semantics have been defined, the rest of the implementation remains straightforward: multiple producers generate updates, one merging engine manages the pending state, a time window manages the latency period, and a dispatcher routes reduced events downstream.
With proper implementation, this system will save effort, reduce latency spikes, improve efficiency, and ensure that only important information is passed through.
Disclaimer
The technical design patterns that are discussed in this paper are meant to be generic and used as discussion topics. This discussion does not include any copyrighted software or an actual employer’s software infrastructure or confidential implementation.
Further reading
- ‘Types of message conflation’ in Diffusion 6.12.0 User Manual, available online at https://docs.diffusiondata.com/docs/latest/manual/html/designguide/data/conflation/conflationtypes.html
- Marco Terzer, ‘Conflation Queues: Protecting High-Freq. Systems During Peak Loads’, posted 31 May 2028, available at https://www.linkedin.com/pulse/conflation-queues-protecting-high-frequency-systems-marco-terzer
- StreamNative, ‘Latency Numbers Every Data Streaming Engineer Should Know’ posted 24 September 2025 and available online at https://streamnative.io/blog/latency-numbers-every-data-streaming-engineer-should-know
- Martin Thompson, ‘Inter Thread Latency’, posted 9 August 2011 on the blog Mechanical Sympathy’ https://mechanical-sympathy.blogspot.com/2011/08/inter-thread-latency.html
- Herb Sutter, Lock-free programming and concurrency articles, posted on Sutter’s Mill https://herbsutter.com/category/concurrency/
- Maged M. Michael (2002), ‘High performance dynamic lock-free hash tables and list-based sets’ in SPAA ‘02: Proceedings of the fourteenth annual ACM symposium on Parallel algorithms and architectures, pages 73–82, available at https://dl.acm.org/doi/10.1145/564870.564881
- Dmitry Vyukov (no date) ‘Bounded MPMC Queue’ on 1024cores, available at https://sites.google.com/site/1024cores/home/lock-free-algorithms/queues/bounded-mpmc-queue
- LMAX Disruptor: High Performance Inter-Thread Messaging Library https://lmax-exchange.github.io/disruptor/
is a software engineering leader and distributed systems architect specializing in modern C++, concurrency, and high-frequency event-driven systems. He has over two decades of experience developing C++ backend application servers for Fixed Income trading systems and Intelligent Network platforms in the telecom industry. His interests include scalable architectures, low-latency engineering, event coalescing, and resilient real-time platforms. You can reach him through his LinkedIn profile: https://www.linkedin.com/in/ajay-pandey-76158310/
