








Modifiable and testable software makes life easier. Lucian Radu Teodorescu explores how Data-oriented Design can help here.
If one made a list of the top most outstanding C++ talks in the last 10 years, Mike Acton’s talk ‘Data-Oriented Design and C++’ [Acton14] would probably rank very high on it. A relatively recent tweet chain started by Victor Ciura [Ciura21] is just a small confirmation of this. The talk covers the fundamental principles for building software, and shows with multiple examples how to get 10x improvements in performance. For a C++ programmer, such an improvement is close to the holy grail.
The common belief these days is that Data-Oriented Design (for short, DOD) is an approach that focuses on program optimisation, an approach brought into the light by Mike Acton.
This article aims at revisiting Acton’s main ideas on Data-Oriented Design and seeing its general applicability for software systems that don’t have hard performance constraints. That is, ignoring performance, we are going to focus on the design part of Data-Oriented Design.
A recap of Acton’s Data-Oriented Design
If you haven’t watched Mike Acton’s presentation [Acton14], it’s best for you to pause reading this article and watch the recording first. The text is waiting patiently.
The ‘Data-Oriented Design and C++’ talk can be divided into four parts. In the first part, Mike describes the constraints that the game industry typically faces, giving a context and a justification for some problems exposed in the talk. In the second part, the talk focuses on the principles of Data-Oriented Design, rules of thumb and a few myths in Software Engineering – this is, more or less, the theoretical framework of Data-Oriented Design. He then goes to give examples from the game industry on how performance can be improved by using DOD; improvements of 10x can be seen by making some relatively simple transformations, having data usage in mind – this is probably regarded as the most powerful part of the presentation. At the end, the talk comes back to reinforce some principles by drawing some conclusions from the presented examples.
Principles and rules of thumb
We will list here the principles and the rules of thumb that Acton exposed in his CppCon 2014 talk [Acton14], in the second part of the presentation. We will separate out the principles from the rules of thumb, and we will number them so that we can refer to them.
[DOD-P1] The purpose of all programs, and all parts of those programs, is to transform data from one form to another.
[DOD-P2] If you don’t understand the data, you don’t understand the problem.
[DOD-P3] Conversely, understand the problem by understanding the data.
[DOD-P4] Different problems require different solutions.
[DOD-P5] If you have different data, you have a different problem.
[DOD-P6] If you don’t understand the cost of solving the problem, you don’t understand the problem.
[DOD-P7] If you don’t understand the hardware, you can’t reason about the cost of solving the problem.
[DOD-P8] Everything is a data problem. Including usability, maintenance, debug-ability, etc. Everything.
[DOD-P9] Solving problems you probably don’t have creates more problems you definitely do.
[DOD-P10] Latency and throughput are only the same in sequential systems.
[DOD-ROT1] Rule of thumb: Where there is one, there are many. Try looking on the time axis.
[DOD-ROT2] Rule of thumb: The more context you have, the better you can make the solution. Don’t throw away data you need.
[DOD-ROT3] Rule of thumb: NUMA extends to I/O and pre-built data all the way back through time to original source creation.
[DOD-P11] Software does not run in a magic fairy aether powered by the fevered dreams of CS PhDs.
These are old principles, but they are even more important these days with the uneven growth of performance for different hardware parts and the ever-increasing demanding needs of the industry.
The three big lies in the software industry
According to Acton, in the software industry we have three big lies that made us move away from these principles:
- Software is a platform. He argues, obviously, that the end hardware is the actual platform. Those who believe that software can be the platform are just ignoring the reality.
- Code designed around model of the world. Here the argument is a bit more complicated; it involves the confusion between the needs for data maintainability and an understanding of the properties of the data, and also the confusion about what IS-A means in the real world and what it means in software. That is, what can be easily done in the real world cannot be simply translated to software. In a previous Overload article, I also argued that IS-A is far too confusing to be used as a basis for software construction [Teodorescu20].
- Code is more important than data. The reasoning against this fallacy starts with [DOD-P1]. If the purpose of any code is to transform data, then data must be more important than code.
An analysis of the DOD principles
While the actual phrasing for some principles may create confusion and may lead to false interpretation, we believe that these are generally true. One reason for accepting them so quickly is because they echo what Brooks had to say in a section called ‘Representation Is the Essence of Programming’ from his The Mythical Man-Month book [Brooks95]:
Much more often, strategic breakthrough will come from redoing the representation of the data or tables. This is where the heart of a program lies. Show me your flowcharts and conceal your tables, and I shall continue to be mystified. Show me your tables, and I won't usually need your flowcharts; they'll be obvious. […] Representation is the essence of programming.
Having Brooks backing it up gives DOD a considerable boost in confidence.
We said that the aim of this article is to not-focus on performance, so let’s split up Acton’s principles and rules of thumb into two categories:
- general software design principles: [DOD-P1] to [DOD-P5], [DOD-P8], [DOD-P9], [DOD-ROT2], and [DOD-ROT3]
- performance-related principles: [DOD-P6], [DOD-P7], [DOD-P10], [DOD-ROT1], and [DOD-P11]
We will entirely ignore the performance-related principles.
The first principle is probably the most important one. It echoes what Brooks also said, and puts the data and data transformation in the centre of all our programming activities. This is obviously true. The important part to notice is that this applies not only to the whole program, but also to program parts. That is, regardless of what size a unit of code is, its purpose is to transform data. This applies from small code snippets, functions, and program components to entire programs. This is an important fact, which we will explore in more detail later. Please also note that it’s hard to fit classes on the same bill; it’s hard to say that the purpose of classes is to transform data – we will cover this later, too.
The principles [DOD-P2]-[DOD-P5] are somehow expressing the same idea: a software problem is a data transformation problem, and the solution needs to be closely related to the data. This can be viewed as a direct consequence of the first principle.
Principle [DOD-P8] extends the data-centric view from just programming to related activities: maintenance, debugging, and even usability. Properly justifying this principle is a more complex endeavour, so we will skip it. What is interesting here is the idea that we often need to look at a larger context when designing a solution. It’s the same idea that is expressed in [DOD-ROT2] and [DOD-ROT3]. And this perfectly aligns with a quote from Eliel Saarinen that Kevlin Henney often brings up in his talks:
Always design a thing by considering it in its next larger context
In Software Engineering, we frequently focus on a narrow part of the universe and try to solve that part. But that is just part of the problem; the final problem that we need to solve is typically much bigger than our focus. Acton also reminds us that we often have additional duties, not just the coding part. [DOD-ROT3] is especially intriguing as it makes us think outside the box. For example, some problems are better solved at compile-time, and not at run-time; this is also appropriate not just for performance, but for modifiability, testability, and other concerns that we might have.
Finally, [DOD-P9] is a truism, but something that we software engineers probably need to hear more often. For some strange reason, we tend to create problems for ourselves out of thin air, as if the problems that we already have are not enough.
To summarise, these principles state that data and data transformation are at the heart of software engineering, and that we should also be aware of the context of this data to fully meet our goals. We argued that all of these make a lot of sense as general principles for Software Engineering, not just for performance-focused development.
Building software with Data-Oriented Design
The name Data-Oriented Design indicates that we can use this approach to design applications. We try to use these data-centric principles, together with the modular decomposition, to sketch a process of designing an application. We will attempt a hierarchical decomposition of the problem, so we will apply the same techniques at multiple levels.
For our purposes, we assume that the process follows somehow an ideal (waterfall) model: we work on a level of abstraction, we fully perform our duties there, and we never invalidate our assumptions. This rarely happens in practice, but let us simplify the exposition here.
Let us take an artificial problem as our running example. Let’s assume that we are building a web service that can be used to do image processing. Some descriptions here are a bit fuzzy on the actual problem to be solved; in real-life, the engineer should fully understand the problem before attempting to solve it.
Top level
We start by considering the problem as a whole. Based on [DOD-P3], we need to understand all the data around this web service to understand the problem to solve. We must understand the inputs of the service (e.g., images from users, images from a database, data models, commands for processing the images, the parameters for image processing, etc.) but also the data produced by the system (e.g., other images, description of the image properties, etc.) – this is typically called the API of the service. But this is not all the data that needs to be transformed by the service. The service also has interactions with the cloud platform, with the DevOps team, with other nodes in the cloud, etc. For example, logging and monitoring are two important aspects of any web service. Moreover, adjacent concerns like how often the system will be restarted, what is the usage scenario, what are the peak hours/seasons, etc., contribute to the data exchange that the program needs to properly manage. And, even if performance is not a major concern, interaction with the actual physical hardware also needs to be considered (for example, for data reliability concerns, which can dramatically change the architecture of the solution).
These may seem a lot of concerns to be taken care of, but, they all deserve our attention. Applying proper engineering to the problem requires us to consider these aspects.
So far, we have just considered the data that our software needs to interact with. But that’s not everything that we need to consider at this level. We need to look now at the next larger context to understand more about the problem at hand (see [DOD-P8]). We need to look at whether the system will be used by humans or other services, what the long-term plan is for the customer paying for this service, what are other services used by the same customer, what are the forces acting on the customer, etc. These all can influence how the customer demands new features or bug-fixes for the new service. Based on these, we can make decisions on how the application needs to be structured, and, more important for our discussion, what additional data we need to maintain to keep the system operational.
Only when we have all this information, when we know what data needs to be transformed by our system, what additional data we need to support, and how our service interacts with the platform, can we fully understand the problem that we are trying to solve.
Breaking down into modules
After we fully understand the problem that we need to solve, i.e., we fully understand the data (see [DOD-P2]) we are ready to decompose the problem into smaller parts, i.e., modules. In this context, the term module may refer to larger application modules (e.g., libraries) or smaller parts of the application (e.g., translation units, functions)
There are multiple approaches to breaking down a system into sub-systems. It is generally accepted that good decompositions will minimise coupling between the smaller parts. Again, depending on your perspective, there are various approaches to ensure low coupling (by change rate, by functional role, by organisational structure, etc.). But we can also use Data-Oriented Design to offer us guidelines on how to perform the decoupling:
- group together data that is used together
- separate data that is not used together
The usage of the data gives us boundaries for our modules. If there are two completely independent data flows, then it probably makes sense that those two flows be in separate modules.
Passing data across modules is more expensive (modifiability, and typically performance) than passing data inside the same module. Thus, one can find the module boundary at the points in which data is stable enough to form an API. This is one important aspect to take into consideration when decomposing the problem.
Another significant aspect of performing a Data-Oriented decomposition is, following [DOD-P1], making sure that the submodule is a proper abstraction for transforming data. One should be able to think of the new submodule as a large function (not necessarily pure) that takes some input data and produces some output data.
With these in mind, we can identify the requirements for creating a module:
- properly identify the input data for the module
- the input data needs to be stable enough to act as the module API
- properly identify the output data for the module
- the output data needs to be stable enough to act as the module API
- analyse the next larger context to properly know the constraints that are imposed on the new module
- ensure that the module can be easily thought of as a large function that transforms input data into output data
Consider the system depicted in Figure 1. Traditionally, one would decompose the system by considering the nodes; the fewer arrows a node has, the less coupled the node is. In a Data-Oriented approach, we should view the links as the main elements.
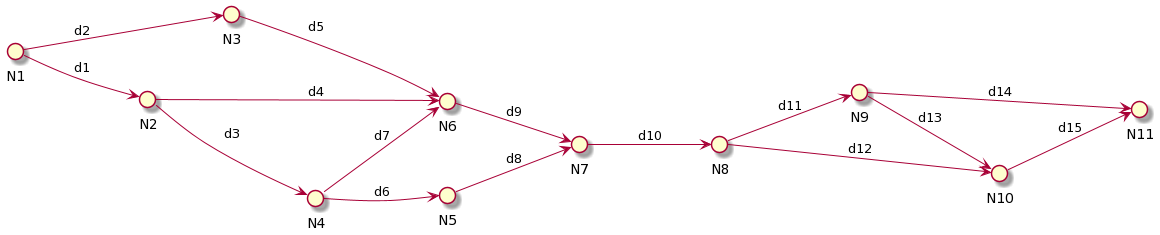 |
| Figure 1 |
The system depicted in Figure 1 can probably be decomposed into two parts: one that contains nodes N1-N7, and one that contains the nodes N8-N11. Looking at the data flow, one can easily see how the two modules would be assimilated as two large functions.
But maybe the data link d10 is not the most stable data channel. It may frequently change with d11 and be very coupled to it. In this case, perhaps it makes more sense to put n7 into the second module, and have the second module depend on two data inputs.
Ideally, each module would have only one data stream as input, but there are countless cases in which multiple input data streams are required. This is especially applicable to modules that maintain state, and interact with other modules in multiple ways.
We might find oftentimes that a data-centric decomposition leads to the same results as a functional decomposition. However, the focus is on the data, not on the code that just transforms the data.
In our imaginary application, we might decide to have a high-level module that deals with HTTP handling, and one module for each type of request handled by the service. These high-level modules can then be subdivided even further into smaller modules, until the decomposition makes sense. This follows because the data required for processing a request type is typically independent of the data required for processing another request type. All the modules created for handling different requests will interact with the module for HTTP handling, but the data passed between these modules is relatively stable.
And, speaking of HTTP services, maybe it’s worth emphasising one important aspects of APIs. From a modifiability perspective, it’s much better to have an API based on HTTP and standard conventions rather than a TCP-based user-defined protocol. The HTTP-based API tends to be more stable, while the TCP-based one may require many changes. Choosing an API based on stability is a consequence of using a data-centric approach.
On reusable libraries
One question that arises is whether Data-Oriented Design encourages or accepts reusable libraries.
The simplistic answer would be NO. A reusable library tends to focus on the code, and abstracts the problem away. In general, different problems require different data; different data means that it’s hard to find a stable API for reusable code libraries. For example, an image can be represented in countless ways; over-generalising a library to process all possible types of image types is an effort that is not needed for most of the applications.
On the other hand, one can easily imagine that the same data structures and same algorithms appear in multiple places in the same application. Maybe the application supports only a limited set of image formats, and this needs to be supported for all the operations our service provides. Or perhaps the linear algebra to be used in the application can be easily abstracted out.
I want to avoid putting words in Acton’s mouth, but I believe that a pragmatic approach to Data-Oriented Design would accept a limited set of reusable libraries. As long as we don’t try to build reusable libraries out of everything; i.e., avoid creating problems that we don’t have.
Use of classes
When we were analysing the DOD principles, we said that classes are a bit odd with respect to these principles. We agreed that the purpose of all code is to transform data, but, if viewed as code, classes don’t typically transform data. Let us analyse a bit more the meaning of this.
When we say classes, in a language like C++ (or C#, or Java, or any language that supports OOP), we typically mean three things:
- a definition of the data layout in memory
- behaviour associated with the data stored in the class
- encapsulating the data of the class through behaviour
The data-layout part of the class is well aligned with DOD. After all, Data-Oriented Design deeply cares about how the data is arranged when solving problems. The problem comes from the other two properties of the class.
First, and more importantly, encapsulating the data inside the class means hiding the data. This is completely against Data-Oriented Design. We cannot have data-orientation when we make extra effort to hide the data. In the spirit of [DOD-P9], we are just creating problems for ourselves, without any real benefit.
Associating behaviour with data is also a bit awkward. This is because we move the focus from the data to the code near the data. We are privileging code inside the class to the detriment of code outside the class. All code should be equal, and inferior to data.
In an ideal world, code should be put in pure functions; impure functions are to be avoided, if possible. If the purpose of the code is to transform data, then it makes sense to make explicit the data we are transforming by making global data either an input or an output of the function.
Pure functions are not quite compatible with class methods, so this is another indication that we should not pack together code with data.
Instead of using classes for representing data, we should use plain structures.
As odd as it sounds, functional languages are more suited to Data-Oriented design than Object-Oriented languages, if we entirely ignore the performance aspect.
Completeness
Unlike other methods, applying Data-Oriented Design doesn’t need to be complete. One can design various parts with a DOD mindset, while leaving other parts to use a code-centric approach (for whatever reason).
Similarly, one can refactor legacy systems and introduce DOD in parts where the system most benefits from it. One can hope to improve performance, or maybe maintainability and debug-ability, and can apply DOD just to those parts of the system.
As long as developers don’t switch too often between DOD and non-DOD code, creating a lot of confusion, it’s fine to have both approaches in the same system.
Therefore, if the ideas presented here are appealing, the reader might consider a gradual deployment of DOD practices in their codebase.
Modifiability
Software is not as hard as a rock. This is why it’s called soft. Typically, software is as fluid as a river is, so perhaps fluidware is a better term.
So, how would Data-Oriented Design fare regarding modifiability? Let’s look first at the costs of change. Here we have both good news and bad news.
The bad news is that certain parts of the code might change more often if DOD is strictly applied, and especially when performance is a major concern. Let us take an example from Acton’s presentation. One technique the author uses to improve the performance and “make the code more data-oriented” is to pull out conditions from loops and from functions with a remark that sounds like “if one has a boolean flag then one probably has multiple types of objects; one should create different data structures and different execution paths”. That is, each time one feels like adding a boolean flag, one should probably reimplement a whole chain of processing. That sounds a bit expensive in terms of programming time.
To generalise this, if the data changes, the problem changes, and we have to write new code. This is the true implication of [DOD-P4] and [DOD-P5].
But, if we turn this around, this is also good news: if the data doesn’t change, then the code we might want to change is minimal. There is probably a bug in one small data transformation. As the data doesn’t change, the flow cannot change; if the flow doesn’t change, then probably the bug is in one small part of the flow. And the change required is pretty small, as there isn’t much we can do to change the code without changing the data.
I view this as a trade-off in modifiability: the more data-oriented a system becomes, the harder it is to make a change when the data needs to change; the less data-oriented a system is, the more difficult it is to make a change when data remains the same.
Let us briefly cover debug-ability as part of modifiability.
A typical data-oriented application is harder to debug with breakpoint, as we need to look at larger volumes of data, and how the data changes over time. Any data-oriented program must have easy ways to extract data out of the system. One cannot properly apply DOD to a system in which it is hard to get data out once the code is running. One quick-and-dirty technique is to dump data to a file.
Once one extracts the data from the system, then, as the system is data-oriented, one can make many predictions for the running application. It should be relatively easy to figure out where the problem lies; the data tells it all.
Probably one shortcoming of this is that the developer must not be afraid of looking at potentially large volumes of data. Personally, I don’t see this as a problem, but I know people who are not comfortable with this approach.
Testability
Being able to test the code written is almost as important as writing the main application code itself. So, Data-Oriented Design needs to behave well regarding testability if we were to consider it a viable technique.
First, the data-oriented code will be driven by data. There are no other code-dependencies. Thus, one can easily create tests that provide some input data and check whether that data is correctly transformed. I would argue that regular DOD code is more testable than regular OOP code.
Furthermore, as discussed above, the ideal DOD code would consist of pure functions. This makes it much easier to test compared to traditional OOP systems, in which the global and shared state is always a problem.
However, it’s not just unit tests that benefit from DOD approaches. Integration tests also become easier to write. We argued that a module, at any level, can be thought of as one big function with some inputs and outputs. That is, it doesn’t matter what size of module we are testing: the strategy applied to unit-tests can be applied to integration tests as well. The only inconvenience of having integration tests rather than unit tests is that the pairs of inputs and outputs become far more complex. However, this has to do with the inherent complexity of integration testing, not the method used to write our code.
As with modifiability, the main downside is that, whenever data changes in the code, a lot of the tests need to be updated too. The effort of updating the tests should be proportional to the effort of changing the code.
A refactoring story
I feel that this is the right time to share a personal example that is connected (at least partially) with Data-Oriented Design. A couple of years back, as an architect, I was tasked to help a (newly formed) team refactor a legacy module. The code was so bad that the team supporting it refused to fix bugs when they were shown the root cause by saying: “if I touch this part of the code, everything will break”. The module contained more than 600 files generated by a huge state machine; the state machine was so complex that saying it was over-engineered seems like a compliment. One of the most important classes in the module contained about 70 pure virtual functions, and it was derived in strange and unexpected ways. On top of that, the threading was a complete mess.
After an initial assessment of all the problems of the module and the strategies that could be used to simplify it, I sat with the team to make a concrete plan for improving it.
The first thing we did was to define what data is being processed by the module. We analysed the data that must be stored by the module (it was a module that had responsibility for keeping some system state). Then we analysed how other modules would interact with this module, in terms of needed data. To our surprise, we found out that the data required by the module was much smaller than we initially thought.
That was the most important step of our effort. Once the data was clear to all of us, we were able to quickly identify the boundaries in which we operate. Without looking at the detail, we knew how the system could be dramatically improved – we knew all the possible ways in which the data could be transformed.
Of course, the new data structures were much better than the old ones. The crazy state machine, with all the generated code and the glue code, was reduced to something that was less than 3000 lines of code. The threading was fixed by using tasks and a clever thread-safe copy-on-write technique. In the end, the whole effort was a great success.
For this effort, we didn’t fully utilise Data-Oriented Design techniques. And certainly, performance was not a major concern. However, the upfront discussion on the data structures was the biggest step forward in the entire process. It was at that time that I realised that Data-Oriented Design should be more about design than about performance.
Conclusions
If Mike Acton had named his approach Data-Oriented Optimisation1, then I would probably have quickly dismissed it as something that is important in certain domains, and that maybe it doesn’t have universal applicability. But the approach contains the term design in its name. And design has a more universal meaning in Software Engineering. Most of what we do is design. So, an analysis of the method focusing on the design part and ignoring the performance part was necessary.
In this article, we have analysed the principles of Data-Oriented Design. While they are a bit verbose, they do make sense – they echo well-accepted principles in our field. Thus, if the principles hold, then it follows that we should use DOD approaches more frequently.
We then went on to analyse the implications of using DOD to design complex applications. We found out that, even though the implications are different from what we are typically accustomed to in OOP, DOD can be used successfully. Assuming that the data doesn’t change often, DOD can provide better modifiability, and, in general, it provides better testability.
All these make Data-Oriented Design a set of practices that should be used more often in Software Engineering. Maybe we don’t get 10x improvement in performance, modifiability and testability. However, considering the state of our industry, any visible improvement is highly welcomed.
References
[Acton14] Mike Acton, ‘Data-Oriented Design and C++’, CppCon 2014, https://www.youtube.com/watch?v=rX0ItVEVjHc
[Brooks95] Frederick P. Brooks Jr., The Mythical Man-Month (anniversary ed.)., Addison-Wesley Longman Publishing, 1995
[Ciura21] Victor Ciura, ‘Unpopular opinion (in the C++ community)…’, Twitter, https://twitter.com/ciura_victor/status/1463280526647865353?s=21
[Teodorescu20] Lucian Radu Teodorescu, ‘Deconstructing Inheritance’, Overload 156, April 2020, https://accu.org/journals/overload/28/156/overload156.pdf
Footnote
- Come to think of it, DOO doesn’t sound that bad. And it forms a nice opposition to OOP. One is data-first, the other one focuses on programming, i.e., on code.
has a PhD in programming languages and is a Software Architect at Garmin. He likes challenges; and understanding the essence of things (if there is one) constitutes the biggest challenge of all.
