








Character encoding can cause problems. Péter Ésik explains why UTF-16 interfaces help on Windows.
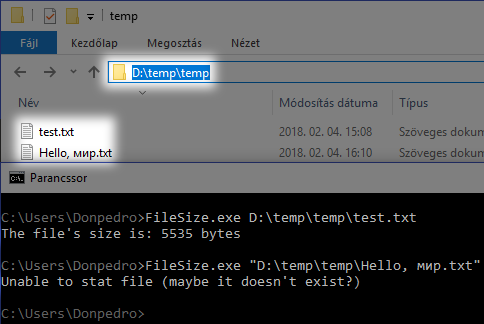
Listing 1 is a small program that takes a file path as a parameter, and queries its size. Even though
stat
is a POSIX function, it happens to be available on Windows as well, so this small program works on both POSIX platforms and Windows. Or does it? Let’s try it out with two test files. For
test.txt
, it correctly reports the file’s size. For
Hello,
мир
.txt
, however, the
stat
call fails (on my machine), even though the file clearly exists (see Figure 1). Why is that?
#include <iostream>
#include <sys/stat.h>
int main (int /*argc*/, char* argv[])
{
struct stat fileInfo;
if (stat (argv[1], &fileInfo) == 0) {
std::cout << "The file's size is: "
<< fileInfo.st_size << " bytes\n";
} else {
std::cout << "Unable to stat file (maybe it
doesn't exist?)\n";
}
}
|
| Listing 1 |
|
| Figure 1 |
The ‘ANSI’ vs. UTF-16 story in five minutes (or less)
Back in the day, character encodings were quite rudimentary. The first encoding widely adopted by computer systems was ASCII [ Wikipedia-1 ] (a 7-bit encoding) , capable of encoding the English alphabet and some other characters (numbers, mathematical symbols, control characters, etc.). Of course, the obvious need arose to encode more characters as users expected computers to speak their language, to type their native letters in e-mails, etc. 8-bit encodings provided a partial solution: code points 0–127 were the same as ASCII (for compatibility), while extra characters were encoded in the range 128–255. 1 Those extra 128 code points were not enough to encode all letters of all languages at once, so character mappings were applied, most commonly known as code pages.
This means that a character or a string that’s encoded like this has no meaning in itself, you need to know what code page to interpret it with (this is somewhat analogous with files and their extensions). For example, code point 0x8A means ä (lowercase a with an umlaut) if you interpret it using the Macintosh Central European encoding [ Wikipedia-2 ], but encodes Š (uppercase S with caron) if you use the Windows-1252 [ Wikipedia-3 ] (Latin alphabet) code page.
This approach has two obvious problems: first, it’s easy to get encodings wrong (for instance, .txt files have no header, so you simply can’t store the code page used), resulting in so-called mojibake [ Wikipedia-4 ]. Second, you can’t mix and match characters with different encodings easily. For example, if you wanted to encode the string "Шнурки means cipőfűző" (with Windows code pages), you would have to encode "Шнурки" with code page 1251 (Windows Cyrillic) [ Wikipedia-5 ], " means " with a code page of your choice (as it contains ASCII characters only), and "cipőfűző" with code page 1250 (Windows Central European) [ Wikipedia-6 ]. To correctly decode and display this string later, you would have to store which code pages were used for which parts, making string handling inefficient and extremely complex.
Because of problems like these, encodings were desired that could represent ‘all’ characters at once. One of these emerging encodings was UCS-2 (by the Unicode working group), which used 16-bit wide code units and code points. Windows adopted UCS-2 quite early, Windows NT 3.1 (the very first OS of the NT series, released in 1993) and its file system, NTFS, used it internally. Even though the 32-bit Windows API debuted with NT 3.1 as brand new, support for 8-bit encodings was still necessary.
2
As UCS-2 used 16-bit code units, and the C language does not support function overloading, Microsoft introduced two versions of every API function that had to work with strings (either directly or indirectly): a UCS-2 version, with a W suffix (‘wide’, working with
wchar_t
strings), and one for 8-bit code paged strings, with an A suffix (‘ANSI’
3
, working with
char
strings).
The A functions act as mere wrappers, usually
4
they just convert the string parameters and forward the call to the corresponding W version. So for example, there is no such function as
MessageBox
, there is only
MessageBoxA
, and
MessageBoxW
. Depending on the strings you have, you need to call the appropriate version of the two.
5
Which code page is used to interpret strings in the A family of functions? Is there a code page parameter passed? No, they use a system-wide setting called the active code page , located in the registry at HKLM\SYSTEM\CurrentControlSet\Control\Nls\CodePage\ACP. This value is decided based on your region you choose at installation time, but can also be changed later in the Control Panel.
Eventually, UCS-2 evolved into UTF-16, and starting with Windows 2000, the OS had support for it. Since UCS-2 is fully compatible with UTF-16, programs didn’t need to be rewritten or even recompiled.
Back to the test program
Armed with this knowledge, it’s easy to see why the small test program doesn’t work for certain files. This is what happens:
- The program is started (with whatever parameters).
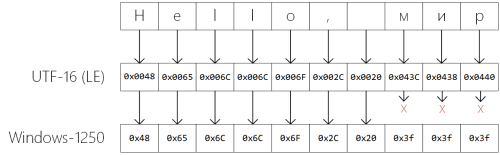
- Very early in the startup phase, Windows converts the (native) UTF-16 command line to an ‘ANSI’ string using the active code page, and stores it in a global variable.
-
Because regular
mainwas used (with ‘narrow’,charparameters) in this application, early in the startup phase the CRT queries the command line withGetCommandLineA(this just returns the global that was set up by the previous step), converts it into an array, and passes it down tomain.
The problem is that there might be characters in the UTF-16 command line that have no representation in the currently active code page. For example, my computer’s locale is set to Hungarian, therefore my ACP is 1250 (Windows Central European) [
Wikipedia-6
]. Cyrillic characters such as м, и, and р have no representation in this encoding, so when the UTF-16 to ‘ANSI’ conversion is performed, these characters are replaced with question marks (see Figure 2).
6
When
stat
is called with the string
"D:\temp\temp\Hello, ???.txt"
(which by the way involves an ‘ANSI’ to UTF-16 conversion internally), of course it fails, because there is no file named
Hello, ???.txt
in that directory.
|
| Figure 2 |
cURL
It’s not that hard to bump into applications or libraries suffering from these problems. cURL, for example, is one of them. Now don’t get me wrong, I’m in no way saying that it’s a badly written piece of software, quite the contrary. It’s a battle-tested, popular open source project with a long history and a plethora of users. Actually, I think this is what makes it a perfect example: even if your code is spot on, this aspect of shipping to Windows is very easy to overlook.
For file IO, cURL uses standard C functions (such as
fopen
). This means that for example, if you want your request’s result written into an output file, it will fail if the file’s path contains characters not representable with the system’s current ‘ANSI’ code page.
Another example is IDN (internationalized domain name) handling. cURL does support IDNs, but let’s see what happens if I try it out using the standalone command line version (see Figure 3).

|
| Figure 3 |
Even though magyarország.icom.museum exists, and its string form is perfectly representable with my machine’s ACP (1250), cURL fails with an error. Looking at the source code quickly reveals the culprit:
- cURL needs to convert the IDN to so-called Punycode [ Wikipedia-7] before issuing the request.
-
It does so with
IdnToAscii[ WindowsDev ], but this function expects a UTF-16 input string. - Even though the original string (which originates from the command line parameter) is an ‘ANSI’ string, conversion to UTF-16 is attempted assuming it’s UTF-8. This makes the conversion fail, and thus cURL aborts with an error message.
cURL developers are aware of this category of problems: it’s listed on their known bugs page [ curl ].
Solution
The solution is in the title of this article: use UTF-16 (native) interfaces on Windows. That is:
-
Instead of regular
main, usewmainas an entry point, which haswchar_tstring arguments. -
Always use the wide version of runtime functions (
_wfopen_sover plainfopen,wcsleninstead ofstrlen, etc.). - If you need to call Win32 functions directly, never use the ‘ANSI’ version with the A suffix, use their UTF-16 counterparts (ending with W).
While this sounds great on paper, there is a catch. You can only use these functions on Windows, as:
-
Some of the widechar runtime functions are Windows-only (such as
_wfopen). -
The size and semantics of
wchar_tare implementation defined. While on Windows it’s a 2-byte type representing a UTF-16 code unit, on POSIX systems it’s usually 4 bytes in size, embodying a UTF-32 code unit.
One possible solution is to utilize
typedef
s and macros. See Listing 2.
#ifdef _WIN32 using nchar = wchar_t; using nstring = std::wstring; #define NSTRLITERAL(str) L##str #define nfopen _wfopen /* ... */ #else using nchar = char; using nstring = std::string; #define NSTRLITERAL(str) str #define nfopen fopen /* ... */ #endif // #ifdef _WIN32 |
| Listing 2 |
This simple technique can go a long way (it can be done somewhat more elegantly, but you get the idea), unless you need to exchange strings between different platforms (over the network, serialization, etc.).
Closing thoughts
I know some people think that the problem presented in this article is marginal, and using
char
strings and ‘ANSI’ interfaces on Windows is ‘good enough’. Keep in mind though that in commercial environments the following situation is not that rare:
- Company X outsources work to company Y, but they reside in different parts of the world.
- Therefore, the computers of company Y have a different ACP from those of company X.
- It’s very likely that the outsourced work involves using strings in company X’s locale, which will be problematic on Windows, if the software used for doing said work misbehaves in this situation.
Don’t be surprised if a potential client of yours turns down a license purchase because of problems like this.
References
[curl] ‘Known Bugs’, curl: https://curl.haxx.se/docs/knownbugs.html#can_t_handle_Unicode_arguments_i
[Microsoft18] ‘Working with strings’, published on 31 May 2018 at https://docs.microsoft.com/en-gb/windows/desktop/LearnWin32/working-with-strings
[Wikipedia-1] ASCII: https://en.wikipedia.org/wiki/ASCII
[Wikipedia-2] Macintosh Central European Encoding: https://en.wikipedia.org/wiki/Macintosh_Central_European_encoding
[Wikipedia-3] Windows -1252 code page: https://en.wikipedia.org/wiki/Windows-1252
[Wikipedia-4] Mojibake: https://en.wikipedia.org/wiki/Mojibake
[Wikipedia-5] Windows-1251: https://en.wikipedia.org/wiki/Windows-1251
[Wikipedia-6] Windows-1250: https://en.wikipedia.org/wiki/Windows-1250
[Wikipedia-7] Punycode: https://en.wikipedia.org/wiki/Punycode
[WindowsDev] IdnToAscii function, Windows Dev Center: https://docs.microsoft.com/en-gb/windows/desktop/api/winnls/nf-winnls-idntoascii
- There are some languages with much more symbols than 128 or 255 (Japanese, Chinese, etc.), which led to the invention of DBCS/MBCS character sets. I’m not mentioning them here for simplicity.
- One major reason for this was (other than UCS-2 not being widespread at the time) that the consumer line of Windows OSes (95, 98, etc.) had very limited support for UCS-2, but applications targeting Win32 had to run on both lines of Windows.
- Technically, it’s not correct to call these functions ‘ANSI’ versions, as none of the supported code pages are ANSI standards. This term has historical roots, as the first Windows code page (1252) was based on an ANSI draft. On recent versions of Windows 10, the ACP can be set to UTF-8. Therefore, it’s best to think about ‘ANSI code pages’ as ‘some encoding that’s not UTF-16’.
-
One exception I know of is
OutputDebugString, where the ‘ANSI’ version is the native one (OutputDebugStringWwill convert to ‘ANSI’ and callOutputDebugStringA) - It’s possible to create programs that can be compiled to support either the W or A interfaces without source changes, using predefined macros [ Microsoft18 ]. Nowadays, however, that’s highly irrelevant. If you are writing programs that target modern Windows versions (only NT), there is almost absolutely no reason to use A interfaces.
- The exact mappings are defined in .nls files located in the System32 directory.
Péter has been working as a C++ software developer for 5 years. He has a knack for everything low level, including (but not limited to) OS internals, assembly, and post-mortem crash analysis. His blog can be found at http://peteronprogramming.wordpress.com.
