








(Re)Actor serialisation requires an allocator. Sergey Ignatchenko, Dmytro Ivanchykhin and Marcos Bracco pare malloc/free down to 15 CPU cycles.
Disclaimer: as usual, the opinions within this article are those of ‘No Bugs’ Hare, and do not necessarily coincide with the opinions of the translators and Overload editors; also, please keep in mind that translation difficulties from Lapine (like those described in [ Loganberry04]) might have prevented an exact translation. In addition, the translator and Overload expressly disclaim all responsibility from any action or inaction resulting from reading this article.
Task definition
Some time ago, in our (Re)Actor-based project, we found ourselves with a need to serialize the state of our (Re)Actor. We eventually found that app-level serialization (such as described in [ Ignatchenko16 ]) is cumbersome to implement, so we decided to explore the possibility of serializing a (Re)Actor state at allocator level. In other words, we would like to have all the data of our (Re)Actor residing within a well-known set of CPU/OS pages, and then we’d be able to serialize it page by page (it doesn’t require app-level support, and is Damn Fast™; dealing with ASLR when deserializing at page level is a different story, which we hope to discuss at some point later).

However, to serialize the state of our (Re)Actor at allocator level, we basically had to write our own allocator. The main requirements for such an allocator were that:
- We need a separate allocator for each of the (Re)Actors running in the same process
- At the same time, we want our app-level (Re)Actors to be able to use simple new and delete interfaces, without specifying allocators explicitly
-
We need each of our allocators to reside in a well-defined set of CPU pages (those pages obtained from the OS via
mmap()/VirtualAllocEx())This will facilitate serialization (including stuff such as Copy on Write in the future).
-
We do NOT need our allocator to be multi-threaded. In the (Re)Actor model,
all
accesses from within (Re)Actor belong to one single thread (or at least ‘as if’ they are one single thread), which means that we don’t need to spend time on thread sync, not even on atomic accesses.
The only exception is when we need to send a message to another (Re)Actor. In this case, we MAY need thread-safe memory but, in comparison with intra-(Re)Actor allocations, this is a very rare occurrence – so we can either use standard
malloc()for this purpose or write our own message-oriented allocator. The latter will have very different requirements and therefore very different optimizations from the intra-(Re)Actor allocator discussed in this article.
Actually, when we realized that we only needed to consider single-threaded code was when we thought, ‘Hey! This can be a good way to improve performance compared to industry-leading generic allocators’. Admittedly, it took more effort than we expected, but finally we have achieved results which we think are interesting enough to share.
What our allocator is NOT
By the very definition of our task, our allocator does not aim to be a drop-in replacement for existing allocators (at least, not for all programs). Use of our allocator is restricted to those environments where all accesses to a certain allocator are guaranteed to be single-threaded; two prominent examples of such scenarios are message-passing architectures (such as Erlang) and (Re)Actors a.k.a. Actors a.k.a. Reactors a.k.a. ad hoc FSMs a.k.a. Event-Driven Programs.
In other words, we did not really manage to outperform the mallocs we refer to below; what we managed to do was to find a (very practical and very important) subset of use cases (specifically message passing and (Re)Actors), and write a highly optimized allocator specifically for them. That being said, while writing it, we did use a few interesting tricks (discussed below), so some of our ideas might be usable for regular allocators too.
On the other hand, as soon as you’re within (Re)Actor, our allocator
does
not
require additional programming effort from the app-level; this gives it an advantage over manually managed allocation strategies such as used by
Boost::Pool
(not forgetting that, if necessary, you can still use
Boost::Pool
over our allocator).
Major design decisions
When we started development of our allocator (which we named iibmalloc , available at [ Github ]), we needed to make a few significant decisions.
First, we needed to decide how to achieve multiple allocators per process, preferably without specifying an allocator at app-level explicitly. We decided to handle it via TLS (
thread_local
in modern C++). Very briefly:
-
By task definition, our allocator is single-threaded.
This allows us to speak in terms of the ‘function which is currently executed within the current thread’.
-
Moreover, at any point in time, we can say which allocator is currently used by the app level (it is the allocator which belongs to the currently running (Re)Actor).
Even if there are multiple (Re)Actors per thread, this still stands.
-
Hence, a
thread_localallocator will do the job:- For a single (Re)Actor per thread , we can have a per-thread allocator (this is the model we were testing for the purposes of this article).
-
For
multiple (Re)Actors per thread
, our Infrastructure Code (which runs threads, instantiates (Re)Actors, and calls
Reactor::react()) can easily put a pointer to the allocator of the current (Re)Actor right before calling the respectiveReactor::react().
- In addition, we found that the performance penalties of accessing TLS (usually one indirection from a specially designated CPU register into a highly-likely cached piece of memory) are not too high even for our very time-critical code.
Second, we needed to decide whether we want to spend time keeping track of whole pages becoming empty so we can release them. Based on the logic discussed in [ NoBugs18 ], we decided in favor of not spending any effort on keeping track of allocation items as long as there is more than one such item per CPU page.
Third, in particular based on [ NoBugs16 ], we aimed to use as few memory accesses as humanly possible . Indeed, on modern CPUs, register–register operations (which take ~1 CPU cycle) are pretty much free compared to memory accesses (which can go up to 100+ CPU cycles).
Implementation
We decided to split all our allocations into four groups depending on their size:
-
‘small’ allocations – up to about one single CPU page.
We decided to handle them as ‘bucket allocators’ (a.k.a. ‘memory pools’). Each page contains buckets of the same size; available bucket sizes are some kind of exponent so that we can keep overheads in check.
Whenever a new page for a specific bucket size is allocated, we ‘format’ it, creating a linked list of available items in the page, and adding these items to the ‘bucket’, which is essentially a single-linked list with all the free items of this size.
-
‘medium’ allocations – those taking just a few pages (currently – up to 4 pages IIRC).
These are also handled as ‘bucket allocators’, but they may span several CPU pages (we named these ‘multi-pages’). Note that for ‘medium’ allocations, all the allocation items are page-aligned.
-
‘large’ allocations – those which are already too large for buckets, but which are still too small to request from the OS directly as a single range (doing so would create too many virtual memory areas a.k.a. VMAs, and may result in running out of available VMA space – which is manifested by
ENOMEMreturned bymmap()even if there is still lots of both of address space and physical RAM). Currently, ‘large’ allocations go up to about a few hundred kilobytes in size.‘large’ allocations are currently handled as good ol’ Knuth-like first-fit allocators working at page level (i.e. granularity of allocations is one page), and with some further relatively minor optimizations.
‘Large’ allocations are not aligned at page boundaries (though, of course, they’re still aligned at 8-byte boundaries).
-
‘very large’ allocations – those allocations which are large enough to feed them to the OS directly. Currently, they start at about a few hundred kilobytes.
Like ‘large’ allocations, ‘very large’ allocations are not aligned on page boundaries.
‘very large’ allocations are the only kind of allocations which can be returned back to the OS.
Optimizing allocation – calculating logarithms
Up to now, everything has been fairly obvious. Now, we can get to the interesting part: specifically, what did we do to optimize our allocator? First, let’s note that we spent most of our time optimizing ‘small’ and ‘medium’ allocations (on the basis that they’re by far the most popular allocs in most apps, especially in (Re)Actor apps).
The first problem we faced when trying to optimize small/medium allocations was that – given the allocation size, which comes in a call to our
malloc()
– we need to calculate the bucket number. As our bucket sizes are exponents, this means that effectively we had to calculate an (integer) logarithm of the allocation size.
If we have bucket sizes of 8, 16, 32, 64, … – then calculating the integer logarithm (more strictly, finding the greatest integer so that two raised to that integer is less or equal to the allocation size) becomes a cinch. For example, on x64 we can/should use a BSR instruction, which is extremely fast. (How to ensure that our code generates a BSR is a different compiler-dependent story but it can be done for all major compilers.) Once we have our BSR, skipping some minor details, we can calculate
bucket_number = BSR(size-1)-2
, or, in terms of bitwise arithmetic, the ordinal number of the greatest bit set of (size-1) minus two.
However, having bucket sizes double at each step leads to significant overheads, so we decided to go for a ‘half-exponent’ sequence of 8, [12 omitted due to alignment requirements], 16, 24, 32, 48, 64, … In this case, the required logarithm to find our bucket size can still be calculated very quickly along quite similar lines: it is a doubled ordinal number of a greatest bit set of (size-1) plus second greatest bit of (size-1) minus five.
These are still register-only operations, are still branch-free, and are still extremely fast. In fact, when we switched to ‘half-exponent’ buckets, we found that – due to improved locality – the measured speed improved in spite of the extra calculations added.
Optimizing deallocation – placing information in a dereferenceable pointer?!
The key, the whole key, and nothing but the key, so help me Codd ~ unknown
Up to now, we have described nothing particularly interesting. It was when we faced the problem of how to do deallocation efficiently that we got into the really interesting stuff.
Whenever we get a
free()
call, all we have is a pointer, and nothing but a pointer (for C++
delete
). And from this single pointer we need to find: (a) whether it is to a ‘small’, ‘medium’, ‘large’, or ‘very large’ allocated block, and for small/medium blocks, we have to find (b) which of the buckets it belongs to.
Take 1 – Header for each allocation item
The most obvious (and time-tested) way of handling it is to have an allocated-item header preceding each allocation item, which contains all the necessary information. This works, but requires 2 memory reads (cached ones, but still taking 3 cycles or so each) and, even more importantly, the item header cannot be less than 8 bytes (due to alignment requirements), which means up to twice the overhead for smaller allocation sizes (which also happen to be the most popular ones).
We tried this one, it did work – but we were sure it was possible to do it better.
Take 2 – Dereferenceable pointers and bucket page headers
For our next step, we had two thoughts:
-
All large/very-large allocated items have values of
CPU_page_start+16(this happens naturally as these items in our implementation always start at page beginning, after a 16-byte header). BTW, ‘16’ is not really a magic number, it is just the size of a large/very-large item header.We can also ensure that all small/medium pointers never start at
CPU_page_start+16. This is assured by the ‘bucket page formatting’ routine, which, if it runs into such a size, simply skips this one single item (note that it won’t happen for larger item sizes, so the memory overhead due to such skipping is negligible).This means that (assuming a 64-bit app and a 4K-page, but for other page sizes the logic is very similar) an expression (
(pointer_to_be_freed&0xFFF)==16) will give us an answer to the question of whether we’re freeing a small/medium alloc or a large/very-large alloc.BTW, this means that we already achieved the supposedly-impossible feat of effectively placing a tiny bit of information into a dereferenceable pointer. In other words, having nothing but the pointer itself (not even accessing the memory the pointer refers to), we can reach conclusions about certain properties of the memory it points to.
-
And for small/medium allocs, we can exploit the fact that all of the buckets within the same page are of the same size. This means that if we place a header into each page (instead of placing it into each allocated item), we’ll be able to reach it using
((page_header*)(pointer_to_be_freed&0xFFFFFFFFFFFFF000))– and get information about the bucket number out of our page_header.
This approach worked, but while it reduced memory overhead, the cost of the indirection to the
page_header
(which was less likely to be cached than the allocation item header) was significant, so we observed minor performance degradation.☹
Take 3 - Storing the bucket number within a dereferenceable pointer
However, (fortunately) we didn’t give up - and came up with the following schema, which effectively allows us to extract the bucket number from each small/medium allocated pointer. It requires a bit of explanation.
Whenever we’re allocating a bunch of pages from the OS (via
mmap()
/
VirtualAllocEx()
) – we can do it in the following manner:
- Let’s assume we have 16 buckets (this can be generalized for a different number of buckets, even for non-power-of-2 ones, but let’s be specific here).
-
We’re
reserving
16 pages, without
committing
them (yet). Sure, it does waste a bit of address space – but at least for 64-bit programs it is not really significant; and as we’re
not
committing, we do
not
waste any RAM (well, except for an additional VMA, but a number of VMAs have to be addressed separately anyway).
As for the wasting of address space , in the worst possible case such a waste is 16x (it won’t happen in the real-world, but let’s assume for the moment it did). And while 16x might look a lot, we can observe that modern OSs running under x64 CPUs have 47-bit address spaces; even with the 16x worst-case overhead, we still can physically allocate 2 43 bytes of RAM, or 8 Terabytes of RAM – which is still well beyond practical capabilities of any x64 box I’ve ever heard of (as of this writing, even the largest TPC-E boxes which cost $2 million, use ‘only’ 4T of RAM). If you ever have such a beast at your disposal, we’ll still have to see whether it will need all this memory within a single process. In any case, it is clear that this waste won’t matter for the vast majority of currently existing systems.
-
Very basic maths
guarantees
us that among our reserved 16 pages, there is
always exactly one
page for which the expression
page_start&0xF000has the value 0x0000, and exactly one page for which the expressionpage_start&0xF000has the value 0x1000, and so on all the way up to 0xF000. In other words, while we do not align our reserved page range, we still can rely on having one page with each of 16 possible values of a certain pre-defined expression over apage_startpointer(!). -
Now, we’re saying, that we need to allocate buckets for
bucket_number7, so let’s pick the page which has the expressionpage_start&0xF000 == 0x7000(as noted above, such a page always exists in our allocated range). Then commit and ‘format’ this page to have buckets corresponding to bucket index == 7. -
Of course, whenever we need a page for a different bucket size, we can (and should) still re-use those reserved-but-not-yet-committed pages, committing memory for them and formatting them for the sizes which follow from their
page_start&0xF000.
After we’re done with this, we can say that:
For each and every ‘small’/‘medium’ pointer to be freed, the expression (
(pointer_to_be_freed>>12)&0xF
) gives us the bucket number.
This information can be extracted purely from the pointer, without any indirections(!). In other words, by doing some magic we did manage to put information about the bucket number into the pointer itself(!!).
In practice, it was a bit more complicated than that (to avoid creating too many VMAs, we needed to reserve/commit pages in larger chunks – such as 8M), but the principles stated above still stand in our implementation.
This approach happened to be the best one both performance-wise and memory-overhead-wise.
How our deallocation works
To put all the pieces of our deallocation together, let’s see how our deallocation routine works:
-
We take the pointer to be freed (which is fed to us as a parameter of a
free()call), and use something along the lines of ((pointer_to_be_freed&0xFFF)==16) to find out if it was small/medium alloc, or large/very-large one. NB: there is a branch here, but large/very-large blocks happen rarely, so mispredictions are rare. - If it is a large/very-large item, we’re using a traditional header-before-allocation-item. As this happens rarely, performance in this branch is not too important (it is fast, but it doesn’t need to be Damn Fast™).
-
If it is a small/medium item, we calculate the bucket size using (
(pointer_to_be_freed>>12)&0xF) and then simply add the current pointer to be freed to the single-linked list of the free items in this bucket.
This is the most time-critical path – and we got it in a very few operations (maybe even close to ‘the-least-possible’). Bingo!
Test results
Of course, all the theorizing about ‘we have very few memory accesses’ is fine and dandy, but to map them into the real world, we have to run some benchmarks. So, after all the optimizations (those above and others, such as forcing the most critical path – and only the most critical path – to be inlined), we ran our own ‘simulating real-world loads’ test [ Ignatchenko18 ] and compared our iibmalloc with general-purpose (multithreaded) allocators. We feel that the results we observed for our iibmalloc were well-worth the trouble we took while developing it.
The testing is described in detail in [ Ignatchenko18 ], with just a few pointers here:
-
We tried to simulate real-world loads, in particular:
- The distribution of allocation sizes is based on p ~(1/ sz ) (where p is the probability of getting allocations of size sz ).
- The distribution of life times of allocated items is based on a Pareto distribution.
- Each allocated item is written once and read once.
- All 3rd-party allocators are taken from the current Debian ‘stable’ distribution.
-
Unless specified otherwise, we ran our tests with total allocation size of 1.3G.
When running multiple threads, the total allocation size was split among threads, so the total allocation size for the whole process remained more or less the same.
As we can see (Figure 1), CPU-wise, we were able to outperform all the allocators at least by 1.5x.
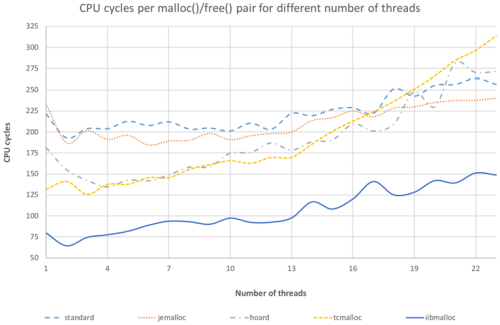
|
| Figure 1 |
And from the point of view of memory overhead (Figure 2), our iibmalloc has also performed well: its overhead was pretty much on par with the best alloc we have seen overhead-wise (jemalloc) – while significantly outperforming it CPU-wise.
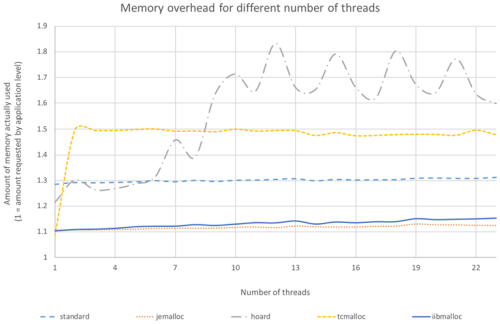
|
| Figure 2 |
Note that comparison of iibmalloc with other allocs is not a 100% ‘fair’ comparison: to get these performance gains, we had to give up on support for multi-threading. However, whenever you can afford to keep the Shared-Nothing model (=‘sharing by communicating instead of communicating by sharing memory’), this allocator is likely to improve the performance of malloc-heavy apps.
Another interesting observation can be seen in the graph in Figure 3, which shows the results of a different bunch of tests, changing the size of allocated memory.
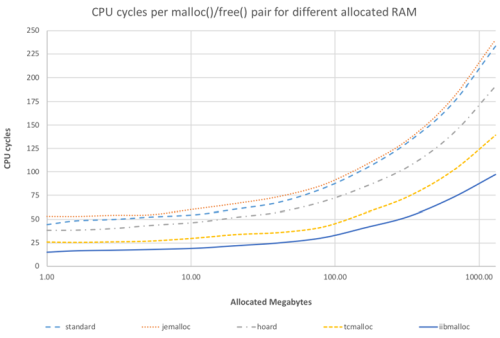
|
| Figure 3 |
NB: Figure 3 is for a single thread, which as we have seen above is the very best case for tcmalloc; for larger numbers of threads, tcmalloc will start to lose ground.
On the graph, we can see that when we’re restricting our allocated data set to single-digit-megabytes (so everything is L3-cached and significant parts are L2-cached), then the combined costs of a
malloc()
/
free()
pair for our
iibmalloc
can be as little as 15 CPU clock cycles(!). For a
malloc()
/
free()
pair, 15 CPU cycles is a pretty good result, which we expect to be quite challenging to beat (though obviously we’ll be happy if somebody does). On the other hand, as we have spent only a few man-months on our allocator, there is likely quite a bit of room for further improvements.
Conclusions
We presented an allocator which exhibits significant performance gains by giving up multi-threading. We did not really try to compete with other allocators (we’re solving a different task, so it is like comparing apples and oranges); however, we feel that we can confidently say that
For (Re)Actors and message-passing programs in general, it is possible to have a significantly better-performing allocator than a generic multi-threaded one.
As a potentially nice side-effect, we also demonstrated a few (hopefully novel – at least we haven’t run into them before) techniques, such as storing information in dereferenceable pointers, and these techniques might (or might not ) happen to be useful for writers of generic allocators too.

References
[Github] https://github.com/node-dot-cpp/iibmalloc
[Ignatchenko16] Sergey Ignatchenko and Dmytro Ivanchykhin (2016) ‘Ultra-fast Serialization of C++ Objects’, Overload #136
[Ignatchenko18] Sergey Ignatchenko, Dmytro Ivanchykhin, and Maxim Blashchuk (2018) ‘Testing Memory Allocators: ptmalloc2 vs tcmalloc vs hoard vs jemalloc While Trying to Simulate Real-World Loads’, http://ithare.com/testing-memory-allocators-ptmalloc2-tcmalloc-hoard-jemalloc-while-trying-to-simulate-real-world-loads/
[Loganberry04] David ‘Loganberry’, Frithaes! – an Introduction to Colloquial Lapine!, http://bitsnbobstones.watershipdown.org/lapine/overview.html
[NoBugs16] ‘Operation Costs in CPU Clock Cycles’, ‘No Bugs’ Hare, http://ithare.com/infographics-operation-costs-in-cpu-clock-cycles/
[NoBugs18] ‘The Curse of External Fragmentation: Relocate or Bust!’, ‘No Bugs’ Hare, http://ithare.com/the-curse-of-external-fragmentation-relocate-or-bust/
