








Portable streaming is challenging. Alf Steinbach describes how his library fixes problems with non-ASCII characters.
My Boost licensed stdlib header library [ stdlib ] applies some crucial fixes to the C++ implementation’s standard library, and provides a (hopefully) complete set of wrapper headers that apply these fixes; some functionality used internally in the stdlib implementation; and a number of convenience headers for the standard library.
The most important fix, because it enables portability and reasonable functionality for beginners’ programs, is of
char
-based text iostreams (e.g.
cout
) console i/o in Windows.
stdlib
installs special buffers in the standard iostreams that are connected to the console, and these buffers provide an UTF-8 view of the console. That means that portable ordinary
char
and
std::string
based code can present e.g. Norwegian and Russian text in the console, via
cout
, and can input international text from the user, via
cin
.
stdlib
also provides an UTF-16 view of the console for
wchar_t
based i/o via the wide iostreams, such as
wcout
.
The UTF-16 view was functionality that essentially came for free, because it was base functionality needed for the UTF-8 view, and it means that in addition to supporting portable
char
based code
stdlib
also supports
wchar_t
-based pure Windows programs.
Here I discuss only this portable console i/o aspect of stdlib – the other stdlib stuff is also nice, but is not as significant.
Goal: portable console i/o
The main goal with stdlib was to enable simple textbook style console based exploratory C++ programs, like the example in Listing 1.

|
| Listing 1 |
A student should be able to type in his or her own non-English name into this program, and see it accurately presented back by the program, also in Windows . This goal is accomplished, modulo the Windows console windows’ restriction to the BMP 1 part of Unicode.
Without a console i/o fix applied, Visual C++’s runtime library forwards the nullbytes that a Windows console window in UTF-8 mode (codepage 65001) produces for non-ASCII characters, i.e. yielding a
name
string with embedded nullbytes, which in the console window’s presentation leaves blank areas (see Figure 1).
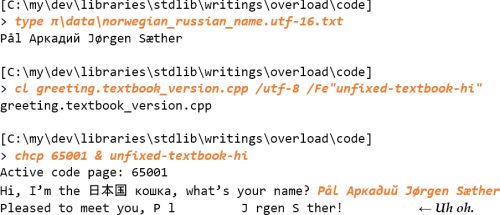
|
| Figure 1 |
Using the Visual C++ 2017 compiler
cl
in Windows 10 and applying the
stdlib
i/o fix via the
/FI
option for a forced include gives the output in Figure 2.

|
| Figure 2 |
This correct result is independent of the console window’s active codepage, and is the same in the *nix world.
The
stdlib
i/o fix includes a convenience
#pragma
for Visual C++, setting the execution character set to UTF-8, for otherwise the execution character set would have had to be specified explicitly as UTF-8 in every compilation, like the
/utf-8
option in the first compiler invocation above. Visual C++ defaults to Windows ANSI encoding, which depends on the locale Windows is installed for. With g++ the execution character set default is already UTF-8.
The technical problem(s)
I hate to hear ‘Less is more.’ It’s a crock of crap.
~ R. Lee Ermey, American soldier and movie star of
Full Metal Jacket
[
Ermey
]
The C and C++ standard libraries’ unified view of console, pipe and file i/o as minimalist streams of bytes, works fine in the *nix world where C and C++ originated. But Windows is based on different ideas, ideas of more rich standard functionality – much richer standard functionality. And so, in Windows the limited byte streams are second or third class citizens, not the primary way to interact with consoles: the streams are evidently there as backward compatibility support for archaic pre-Unicode programs, because UTF-8 console input Just Doesn’t Work™ for non-ASCII characters.
So, what happens if you tell a Windows console window to use UTF-8 encoding, by setting its active codepage to 65001?
As of Windows 10 byte stream output appears to work, but, down at the Windows API level, byte stream input of non-ASCII characters produces just nullbytes, as illustrated by a program that directly uses Windows’
ReadFile
and
WriteFile
functions (see Figure 3).

|
| Figure 3 |
Additionally, Visual C++’s
setlocale
in Windows [
Microsoft-a
] explicitly does not support UTF-8. A possible reason is the C standard’s requirement that a
wchar_t
“
can represent distinct codes for all members of the largest extended character set specified among the supported locales
” [
C99
]. For Windows’
wchar_t
type, from the early Unicode adoption, is just 16 bits, which with modern 21-bit Unicode is not enough for all members of an UTF-8 locale.
And in addition to the limited Windows support for UTF-8 in consoles, the C and C++ standard libraries fail to support UTF-8 text handling. There is no functionality for iterating over code points (which can be of a variable number of bytes); the functionality for
char
classification, such as the C library’s
isupper
, only works for single bytes, i.e. when the UTF-8 character is in the ASCII subset; the C++ library’s
std::ctype::widen
, which can deal with a string of encoding units, is rendered impotent for portable code by the fact that there’s no UTF-8 locale in Windows, so there’s no way to tell it that those bytes are UTF-8 encoded text; and so on, and on. AFAIK there’s no solution that addresses all the issues.
However, the lack of C++ standard library support was not a showstopper for the *nix world’s transition to UTF-8. In the late 1990s and early 2000s one simply let existing tools treat UTF-8 as extended ASCII text with occasional pass-them-right-through-please hey just ignore them high value bytes. Today, as of 2017, the *nix world appears to be all UTF-8 for text files, so that approach worked, and hence it can presumably also work for Windows.
Possible solutions
The missing functionality for text handling is offered by various 3rd party libraries, including IBM’s open source ICU library [
ICU
], and Boost Locale, which is a
char
-based wrapper over ICU. The Boost Locale documentation notes that “
The default character encoding is assumed to be UTF-8 on Windows
” [
Boost-a
]. So evidently, an assumption of UTF-8 as the main text encoding on every platform, including in Windows, is not unheard of.
A mainly all UTF-8 approach for external text and for simple processing, with conversion to and from UTF-16 for e.g. use of ICU, seems to be where we’re heading, also for Windows programs.
Anyway, to work with international text in Windows consoles, especially for beginners, it’s practically necessary to
- change the default font for Windows console windows 2 to one that can display international characters, such as Lucida Console, or else use 3rd party console windows.
With that display fix in place one basically has three options for portable C++ code:
- use byte stream i/o with some fix applied in Windows, e.g. the standard library’s byte streams with a restricted character set from a national codepage, or with conversion to/from internal UTF-8 such as provided by stdlib ;
-
use wide stream i/o (note: the standard library’s wide stream i/o converts to and from external byte streams) with some platform-dependent fix applied, e.g. in Windows, using the standard library’s wide streams with Microsoft’s
_setmodeextension [ Microsoft-b ], or again using stdlib , and in the *nix world, with a suitable UTF-8 locale; or - use an abstraction that transparently adapts the encoding to the system, selecting between byte and wide stream i/o within the implementation of that abstraction, with an encoding unit type suitably defined for each system.
Some years ago, I saw adaptive encoding and i/o as a viable compromise between conflicting goals [ Steinbach13 ].
One main problem with that approach, however, is that it’s necessarily intrusive, e.g. requiring string literals wrapped in adaptive macro calls like
S("Hi")
and use of standard streams via adaptive references like
sys::out
for
std::cout
, so that
- the approach can’t handle simple textbook example program code as-is, and hence
- existing code doesn’t automatically benefit.
This is what stdlib addresses with its UTF-8 console i/o: it can handle textbook example program code as-is, and if existing code uses the C++ iostreams, then that code benefits automatically.
In contrast the nowide library [ nowide ], adopted in Boost [ Boost-b ] in June 2017, is an intrusive UTF-8 i/o approach, and thus, except that it handles ordinary nartr literals, it suffers from the drawbacks above.
The
nowide
web page refers to a 2011 blog posting of mine [
Steinbach11
] about Unicode in Windows console windows, which, incidentally, is how I became aware of
nowide
, some time after I started work on
stdlib
. In that article, I argued for leveraging Microsoft’s
_setmode
extension, using wide text internally in the C++ program, and I referred to a 2008 blog posting by Microsoft’s Unicode guru Michael Kaplan, titled ‘Conventional wisdom is retarded, aka What the @#%&* is
_O_U16TEXT
?’ [
Kaplan08
]. Both
stdlib
and
nowide
now go in the opposite direction, using nartr text internally in C++.
General comparison: adaptive versus stdlib versus nowide
The C++ core language is involved in two areas: string literals and process command line arguments, namely the arguments of
main
. Happily, with the all UTF-8 approach of
stdlib
and
nowide
, and with modern compilers’ (especially now Visual C++’s) support for UTF-8 as the execution character set, one can just use ordinary nartr literals. Unfortunately, there seems to be no portable non-intrusive way to fix the encoding of the arguments of
main
in Windows, and so both libraries provide intrusive, portable means of obtaining UTF-8 encoded command line arguments.
Apart from that the stdlib library is based on only providing transparent fixes to the standard library implementation, and a minimum of new functionality, while the adaptive approach and the nowide library are based on providing alternatives to the core language and standard library in certain areas.
With stdlib ’s goal of providing as little new functionality as possible, checking which of stdlib and other libraries provide the most features, would be mostly meaningless. But one can still compare general goals or ideals achievement for the libraries. For the adaptive approach, the table below just lists what will be generally true of any reasonable implementation of that approach.
| Goal/ideal | Adaptive | stdlib | nowide |
|---|---|---|---|
| General | |||
| Working nartr Unicode console i/o | n/a | Success | Partial |
| Working wide Unicode console i/o | n/a | Success | Failure |
| That it fails gracefully for bad data | - | Success | Failure |
| Support of coding | |||
Idiomatic
char
based learner’s C++
|
Failure | Success | Success |
| No <windows.h> namespace pollution | - | Success | Success |
| Few or no explicit encoding conversions | Partial | Failure | Failure |
| Using textbook example code as-is | Failure | Mostly | Failure |
| Automatic benefit for existing code | Failure | Mostly | Failure |
| Support of building & other tool usage | |||
| No large 3rd party library dependency | - | Success | Success |
| Header only library | - | Success | Failure |
| Tools, e.g. string display in debuggers | Success | Failure | Failure |
| Clean build with common compilers | - | Success | Failure |
My ‘partial’ mark on nowide ’s working is mainly due to its failure to remove carriage return characters from input in Windows (Listing 2). The result is in Figure 4.

|
| Listing 2 |

|
| Figure 4 |
This problem, plus a ditto problem with Windows’ convention of using Ctrl Z as EOF marker, has probably already been fixed by the time you’re reading this. But I was perplexed to discover that the library bungled input, which is so fundamental to what it’s all about, after it had been approved for Boost. It’s really strange.
With Visual Studio’s debugger in Windows one can use the format specifier
,s8
on a watch of a raw C string to force UTF-8 interpretation of the bytes. However, with other presentations of nartr strings the VS debugger uses Windows ANSI, even when the program’s execution character set is UTF-8, with gobbledygook as the result. This is the main tool support failure of
stdlib
and
nowide
, and it’s one area where the adaptive approach would shine.
Hopefully, in the not distant future the Visual Studio debugger will gain some option to assume UTF-8, or maybe it will just pick up what the program’s execution character set is, not to mention encoding information for each literal, and use that.
stdlib ’s not quite 100% success in supporting textbook example code is due to the following constraints:
-
automatic conversion to/from internal UTF-8 for console i/o seems to not be portably possible for C
FILE*i/o, and -
with both Visual C++ and MinGW g++ the arguments of
mainare (incorrectly) Windows ANSI-encoded even when the execution character set is UTF-8, and a transparent automatic fix appears to not be practically possible.
Command line arguments in stdlib versus nowide
Both
stdlib
and
nowide
assume that
main
arguments on other platforms than Windows are UTF-8 encoded. In Windows, they both use the
GetCommandLineW
API function to obtain the original UTF-16 encoded command line passed to the process, and
CommandLineToArgvW
to parse it into individual arguments.
stdlib
uses this info to provide a separate set of UTF-8 encoded original command line arguments, while
nowide
uses the info to replace the
main
arguments with UTF-8 encoded originals.
The intended default usage in
stdlib
(and what I hope for in some future C++ standard library support for this) is that a
Command_line_args
object should be default-constructed wherever command line arguments are needed, which supports use in e.g. the constructor of a namespace scope variable, or in some other function without access to the actual
main
arguments.
As of July 2017, default construction of
Command_line_args
is implemented only for Windows and Linux, but code that only needs to be portable to these two systems can look like Listing 3.

|
| Listing 3 |
This can be made fully portable by replacing the
main
code with Listing 4... which, however, is not possible for the mentioned case of constructor for a namespace scope variable (without employing a time machine to check what the future call of
main
will have).

|
| Listing 4 |
The
nowide
library offers only this latter restricted approach of passing the actual
main
arguments to a fixer object (see Listing 5).
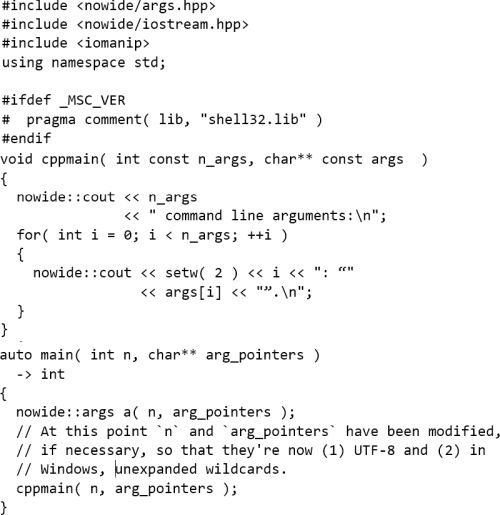
|
| Listing 5 |
Using the *nix world convention of representing the command line arguments as an
int
+
char**
pair makes it easy to use library functions based on that convention, such as
getopt
. With
stdlib
the
Command_argv_array
class offers this value pair. A key difference is that an instance of
stdlib
’s
Command_argv_array
is a copy of the argument string data, so that the data can be freely modified.
Note: with MinGW g++ and
nowide
the value of
n
above
can be reduced
by the declaration of the
nowide::args
variable, because MinGW g++ provides wildcard expansion of arguments, and the synthesized UTF-8 encoded arguments are not expanded.
Neither
stdlib
nor
nowide
provide dedicated wildcard expansion functionality, but
stdlib
offers portable access to the C++17 filesystem library, which combined with some regular expression matching can do the chore. However, that’s quite complex machinery. E.g. with normal Windows filename wildcards a
*
doesn’t match backward slashes (which a regular expression simple
.*
pattern does), and one has to deal with absolute and relative paths. I think wildcard expansion functionality properly belongs with the iteration ability of the filesystem library, and not with mainly a console i/o fix library. Alas, the filesystem library does not yet offer this functionality.
Using the C++17 filesystem library
Sometimes an executable has associated files such as configuration files and resource files, placed in the directory that itself resides in, or in some sub-directory there. Thus, sometimes one needs a path to the executable’s directory. The ‘current directory’, the default origin for relative paths, can be and often is some other directory. Usually the current directory is initially the directory from which the program was launched this time, i.e. some arbitrary directory, anywhere. Since the current directory is used automatically, client code does not usually need its path for e.g. resolving command line filename arguments. But client code does, in general, need the path to the executable’s directory.
However, the C++17 filesystem library
-
provides the generally not needed current directory path,
fs
::current_path()– where fs denotesstd::filesystem– and - does not provide the often crucial executable’s directory path.
Happily, the first process command line argument, the first argument of
main
, is in practice a relative or absolute path to the executable. This is not formally guaranteed, but in practice it’s nearly always so. Ideally then, to determine a path to the executable’s directory, code like this should be sufficient (see Listing 6).
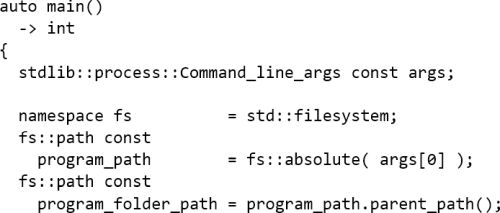
|
| Listing 6 |
But run the program from a directory where the relative path to the executable’s directory contains non-ASCII characters
3
, and then this simple, natural and (assuming the first argument of
main
actually refers to the executable) formally correct code, fails (Figure 5).

|
| Figure 5 |
What’s going on here?
Running from the executable’s directory would work because with this code the name of the executable, passed to
fs
::absolute()
, is then effectively a dummy – any filename-like string would do.
But running it from the parent directory involves a non-ASCII character, π, in the path, which is served correctly, as UTF-8, to
fs
::absolute()
. Here things go haywire because, as of July 2017, the Visual C++ and MinGW g++ implementations of the C++17 filesystem library
ignore
the execution character set and instead assume that nartr strings are and should be Windows ANSI encoded… Since Windows ANSI is a country-specific encoding choice the result
Ï€
can even be different on other machines.
It’s trivially easy to check if the execution character set is UTF-8, and these implementations lay down the rules from scratch, with no frozen history constraining them. So, as I see it, the behaviour is really not excusable. Unfortunately, as far as I know there’s no way that stdlib can fix this functionality transparently.
Until all common implementations of the C++17 filesystem library conform to the standard one therefore has to be very careful about always explicitly specifying UTF-8 in code using the filesystem library, by e.g. using the
fs
::u8path
factory function (see Listing 7).
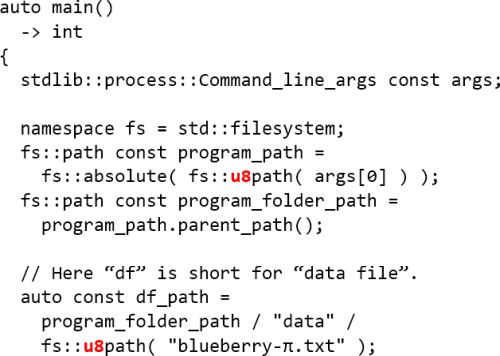
|
| Listing 7 |
… and the other way by using e.g. the
fs
::path::u8string
conversion function:
string const dfp_utf8 = df_path.u8string();
In the first example
"data"
contains only ASCII characters and can therefore be served raw to the filesystem machinery, but
"blueberry-
π
.txt"
is decidedly non-ASCII so that it must be manually tagged as Unicode via a call to
fs
::u8path
.
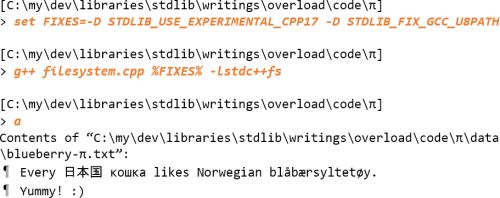
As with the nowide library’s incorrect console input operation in Windows, the continued existence of this fundamental level failure of the filesystem library implementations, so very far into the game, appears perplexing, bewildering, inexplicable. But hopefully both the Visual C++ and the MinGW g++ implementations will be fixed. And, as Jerry Pournelle used to put it, Real Soon Now™.
The workarounds, the extra care and explicitness, is all that’s needed with Visual C++. However, with MinGW g++ 7.1 and earlier the workarounds run into another filesystem implementation bug. For the MinGW g++ 7.1 implementation of
fs
::u8path
can only handle UTF-16 encoded wide strings…
Happily, stdlib provides a transparent fix for that.
But, that fix must be explicitly requested, by defining
STDLIB_FIX_GCC_U8PATH
, because it’s function template specializations that at least in theory won’t necessarily build for a later or earlier version of the compiler, though this code may still work and may be necessary also for such versions. (See Figure 6.)
|
| Figure 6 |
In passing: internally this fix uses
stdlib::wide_from_utf8
and
stdlib::utf8_from
, which are among the library implementation features that are made available via
stdlib
’s public interface.
4
The fix is not needed in the *nix world. In the *nix world
fs
::u8path
converts the argument to
std::string
with no encoding change. And so, for example, in Ubuntu, using g++ 6.3.0, the code compiles and works fine without the fix.
Just as MinGW g++ 7.1’s
fs
::u8path
punts on implementing an UTF-8 → UTF-16 conversion in Windows, with MinGW g++ 7.1 an
fs
::path
argument to a file iostream constructor is not supported, though it’s required by C++17. The lack of
fs
::path
argument is problematic because g++’s default standard library implementation doesn’t support wide string argument
5
, either, and a nartr string path argument is assumed to be Windows ANSI encoded. And yes, that’s even with UTF-8 execution character set.
There are three main solutions where portable Unicode paths are required:
-
Only C++17-compatible compilers.
This means not using MinGW g++, or not testing parts of the code with MinGW g++, or waiting until MinGW g++’s filesystem and iostreams library implementations are fixed.
-
Pure ASCII alternative paths.
Windows supports, although not completely and not for all Windows ‘technologies’, alternative pure ASCII paths. These are called short paths. The stdlib library provides a more robust abstraction, a best effort mostly readable native encoding nartr path, as
stdlib::char_path()& friends. -
Custom iostream class.
If one controls the file opening code, then better replace e.g.
std::ifstreamwith a custom iostream class that supports fs::pathor wide string argument, or best, that directly and portably supports UTF-8 encoded nartr string argument. The nowide library provides that asnowide::ifstream& friends. Such a class can also relatively easily be implemented in terms of__gnu_cxx::stdio_filebuf<char>.
Alternative ASCII paths were the basis of the MinGW g++ fix employed in the early Boost Filesystem, version 2 [
Boost-c
], but it was discontinued with no alternative fix in version 3, apparently deferring that fix to standardization. The original filesystem TS suggested that iostream constructors in Windows implementations should support the Visual C++ extension of wide character path argument. With C++17 we additionally have iostream constructors accepting
fs
::path
directly, except that – the problem – as of this writing, MinGW g++’s default standard library implements neither.
Figure 7 is an example of a pure ASCII alternative path in Windows.

|
| Figure 7 |
For readability and to preserve as much information as possible, especially for a name of a file to be created,
stdlib::char_path()
provides a Windows ANSI path, not a pure ASCII path, where it retains (transcoded) those items of the original Unicode path specification that can be encoded exactly as Windows ANSI (Figure 8).
|
| Figure 8 |
Where an item can’t be represented exactly as Windows ANSI and doesn’t have an alternative ASCII name,
char_path
replaces any non-ANSI character with
stdlib::ascii::bad_char
, ASCII 127. I assume that this is often the desired behaviour: deferring path validity checking to the file opening code, and just using the path with replacements if it works, e.g. for display, or for creating a file. In contrast,
stdlib::char_path_or_x
thtrs a
std::runtime_error
exception if the Unicode path can’t be represented exactly.
The design intention is to use
char_path
by default, e.g. for portably passing nartr paths to 3rd party library code, and as a not quite 100% but mostly Just Good Enough™ workaround/fix for filesystem-challenged implementations, like Listing 8.

|
| Listing 8 |
Here, the UTF-8 path is used in the failure reporting instead of just outputting the
fs
::path
directly, because while MinGW g++ 7.1 curiously does support that it adds simple ASCII quotes and duplicates every backslash, sort of happily sabotaging things.
As mentioned, the newly adopted-in-Boost nowide library provides streams that can be opened with UTF-8 encoded paths. And for file opening code that one controls, using an alternative file iostream implementation solves the availability problems of Windows ASCII alternative paths. For the code above, with the standalone variant of nowide , this solution entails just adding a
#include <nowide/fstream.hpp>
replacing
ifstream f{ dfp_native };
with
nowide::ifstream f{ dfp_utf8 };
and removing the
dfp_native
lines, and that’s all.
With this approach, one uses each library for what it’s good at.
| ASCII Alternative Paths | |
|
Invalid-as-UTF-8 bytes, how, what?
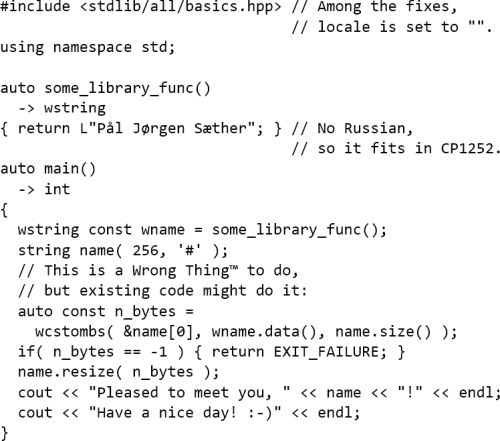
Nartr text bytes that are invalid as UTF-8 can occur due to a number of possible reasons, e.g. just passing raw
main
arguments to
cout
, or doing conversion from wide text to the nartr encoding of the user’s native locale, which in Windows cannot be UTF-8.
When this happens, it’s in my opinion best if it doesn’t stop output of further text, or indeed, of the text containing the bad bytes.
stdlib
just replaces each bad byte with ASCII 127,
DEL
(see Listing 9). The result of the
stdlib
-based code is in Figure 9 – it works the same with g++.
|
| Listing 9 |

|
| Figure 9 |
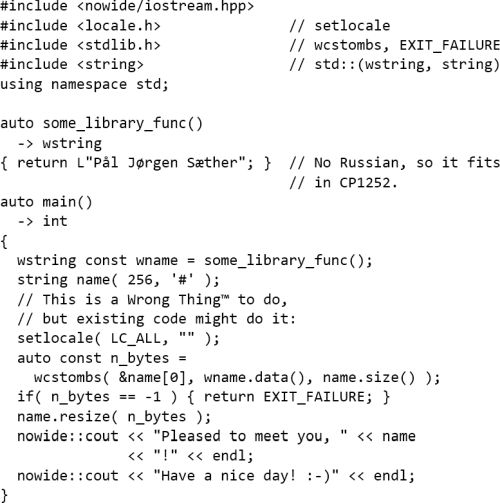
The corresponding nowide -based code is in Listing 10 and the result of the nowide -based code is in Figure 10.
|
| Listing 10 |

|
| Figure 10 |
Summary
There are currently two C++ libraries for UTF-8 console i/o in Windows: the author’s stdlib , and the nowide library recently adopted in Boost. With stdlib , existing textbook code can work for Unicode console i/o in Windows, and since it’s a header only library it’s easy to use for novices. With nowide there is separate compilation, which can be a barrier to novices, and one’s code must be modified to explicitly use the nowide functionality, which also means that existing, unmodified code doesn’t benefit from nowide .
As of this writing, console input just didn’t work correctly with nowide –it included carriage return characters in input lines.
The
nowide
library’s
nowide::ifstream
(& family) can be very useful as a workaround for MinGW g++’s current filesystem library implementation deficiencies, when one controls the file opening code. The corresponding
stdlib
fix
stdlib::char_path
is based on Windows’ alternative ASCII names, which is easy to use and supports 3rd party library functions such as with OpenCV. It’s guaranteed to work for a path that can be represented exactly with Windows ANSI encoding, plus this approach has worked for general Unicode existing paths on all the myriad local Windows systems that the author has used. I.e. it’s not a perfect fix, but simple and usually Good Enough™.
References
[Boost-a] At http://www.boost.org/doc/libs/1_48_0/libs/locale/doc/html/default_encoding_under_windows.html
[Boost-b] Boost acceptance of NoWide: https://lists.boost.org/boost-announce/2017/06/0516.php
[Boost-c] Referred to in a 2011 discussion between the Boost Filesystem creator Beman Dawes and the author, titled ‘Making Boost.Filesystem work with GENERAL filenames with g++ in Windows (a solution), at https://lists.boost.org/Archives/boost/2011/10/187282.php
[C99] C99 §7.17/2 (I used the N1256 draft, roughly C99 + TC1 + TC2 + TC3, for the quote).
[Ermey] Quoted from https://www.brainyquote.com/quotes/quotes/r/rleeermey464853.html
[ICU] The International Components for Unicode library, available at http://site.icu-project.org/
[Kaplan08] Still available at http://archives.miloush.net/michkap/archive/2008/03/18/8306597.html
[Microsoft-a] Quoting Microsoft’s documentation of
setlocale
: “
If you provide a code page value of UTF-7 or UTF-8,
setlocale
will fail, returning
NULL
.
” ATTOW that documentation was available at
https://docs.microsoft.com/en-us/cpp/c-runtime-library/reference/setlocale-wsetlocale
[Microsoft-b]
_setmode
docs at
https://docs.microsoft.com/en-us/cpp/c-runtime-library/reference/setmode
[Microsoft-c] Windows API function GetShortPathName documentation, at https://msdn.microsoft.com/en-us/library/windows/desktop/aa364989(v=vs.85).aspx
[nowide] The NoWide library is available at http://cppcms.com/files/nowide/html/index.html
[stdlib] The stdlib library is available at https://github.com/alf-p-steinbach/stdlib
[Steinbach11] ‘Unicode part 1: Windows console i/o approaches’, at https://alfps.wordpress.com/2011/11/22/unicode-part-1-windows-console-io-approaches/
[Steinbach13] ‘Portable String Literals in C++’, Overload #116, August 2013, available at https://accu.org/index.php/articles/1842
- The BMP, the Basic Multilingual Plane , is Unicode restricted to 16 bits, like in Unicode version 1 in 1991/1992. The 21-bit version 2 came in 1996. By that time Microsoft had committed to 16-bit Unicode. Unicode 2’s UTF-16 encoding was designed to allow the existing 16-bit Unicode systems (various programming languages, + Windows) to just keep on working; a backward-compatible encoding. So most of Windows uses full UTF-16, but Windows console windows have a non-streaming API that restricts each character position to 16 bits. Hence if you output an UTF-16 surrogate pair (representing a Unicode code point outside the BMP, e.g. an emoji or an archaic Chinese glyph) to a Windows console window, you get two characters displayed, probably as “I didn’t understand that” squares.
- To change the default font for a Windows console window, just right click the window title for a menu, and drill down into it
- Using the name “cat”, expressed as Russian “кошка”, for an executable that lists the contents of a multi-language text file, is a weak pun. It was the best I could do.
- ATTOW these conversion functions are limited to UTF-16 for wide text, e.g. they can’t (properly) handle emojis in the *nix world. I intend to remove that limitation, but must do one thing at a time.
- C++17 §30.9.1/3 requires wide string filename argument support for iostreams implementations on systems with wide native paths. Prior to C++17 this was a Visual C++ extension of the standard library.
