








Dealing with an infinite sequence requires some thought. Thomas Guest presents various ways to approach such a problem.
I chanced upon an interesting puzzle:
Find the smallest number that can be expressed as the sum of 5, 17, 563 and 641 consecutive prime numbers, and is itself a prime number.
Here, the prime numbers are an infinite steam:
2, 3, 5, 7, 11, 13 ...
and sums of N consecutive primes are similarly infinite. For example, the sum of 2 consecutive primes would be the stream:
2+3, 3+5, 5+7, 7+11, 11+13 ...
which is:
5, 8, 12, 18, 24 ...
and the sum of 3 consecutive primes is:
10 (=2+3+5), 15, 23, 31 ...
Had we been asked to find the smallest number which can be expressed as the sum of 3 consecutive primes and as the sum of 5 consecutive primes and is itself prime, the answer would be 83.
>>> 23 + 29 + 31
83
>>> 11 + 13 + 17 + 19 + 23
83
Infinite series and Python
My first thought was to tackle this puzzle using Python iterators and generators. Here’s the outline of a strategy:
- starting with a stream of primes
- tee the stream to create 4 additional copies
- transform these copies into the consecutive sums of 5, 17, 563 and 641 primes
- merge these consecutive sums back with the original primes stream
- group the elements of this merged stream by value
- the first group which contains 5 elements must have occurred in every source, and is therefore a prime and representable as the consecutive sum of 5, 17, 563 and 641 primes
- which solves the puzzle!
Note that when we copy an infinite stream we cannot consume it first. We will have to be lazy or we’ll get exhausted.
Courtesy of the Python Cookbook , I already had a couple of useful recipes to help implement this strategy (see Listing 1).
def primes():
'''Generate the sequence of prime numbers: 2,
3, 5 ... '''
....
def stream_merge(*ss):
'''Merge a collection of sorted streams.
Example: merge multiples of 2, 3, 5
>>> from itertools import count, islice
>>> def multiples(x):
return (x * n for n in count(1))
>>> s = stream_merge(multiples(2),
multiples(3), multiples(5))
>>> list(islice(s, 10))
[2, 3, 4, 5, 6, 6, 8, 9, 10, 10]
'''
....
|
| Listing 1 |
Both these functions merit a closer look for the cunning use they make of standard containers, but we’ll defer this inspection until later. In passing, note that
stream_merge()
’s docstring suggests we might try using it as basis for
primes()
:
- form the series of composite (non-prime) numbers by merging the streams formed by multiples of prime numbers;
- the primes remain when you remove these composites from the series of natural numbers.
This scheme is hardly original – it’s a variant of Eratosthenes’ sieve – but if you look carefully you’ll notice the self-reference. Unfortunately recursive definitions of infinite series don’t work well with Python
1
, hence
primes()
requires a little more finesse. We’ll take a look at it later.
Moving on, to solve the original puzzle we need a consecutive sum filter. Listing 2 will transform a stream of numbers into a stream of consecutive sums of these numbers.
def consecutive_sum(s, n):
'''Generate the series of sums of n
consecutive elements of s
Example: 0, 1, 2, 3, 4 ... => 0+1, 1+2,
2+3, 3+4, ...
>>> from itertools import count, islice
>>> list(islice(consecutive_sum(count(), 2),
10))
[1, 3, 5, 7, 9, 11, 13, 15, 17, 19]
'''
lo, hi = itertools.tee(s)
csum = sum(next(hi) for _ in range(n))
while True:
yield csum
csum += next(hi) - next(lo)
|
| Listing 2 |
Here we can think of the summed elements as lying within a sliding window: each time we slide the window an element gets added to the top and an element gets removed from the bottom, and we adjust
csum
accordingly.
So, now we have:
-
the series of prime numbers,
primes() -
a
stream_merge()connector -
a
consecutive_sum()filter
The remaining stream adaptors come from the standard itertools module. Note that the
stream_merge()
works here since all the consecutive sum series are strictly increasing. Note also that the stream of prime numbers can be treated as
consecutive_sum(s=primes(), n=1)
, handling the ‘and is itself a prime number’ requirement. (See Listing 3.)
>>> lens = 1, 5, 17, 563, 641
>>> N = len(lens)
>>> from itertools import tee, groupby
>>> ps = tee(primes(), N)
>>> csums = [consecutive_sum(p, n) for p, n in zip(ps, lens)]
>>> solns = (n for n, g in groupby(stream_merge(*csums))
if len(list(g)) == N)
|
| Listing 3 |
Here,
solns
is yet another stream, the result of merging the
N
input consecutive sum streams then filtering out the numbers which appear
N
times; that is, the numbers which can be expressed as sums of 1, 5, 17, 563 and 641 consecutive primes.
The first such number solves the original puzzle.
>>> next(solns) 7002221
Figure 1 is a picture of how these stream tools link up to solve this particular puzzle. The great thing is that we can reconnect these same tools to solve a wide range of puzzles, and indeed more practical processing tasks. To use the common analogy, we direct data streams along pipes.
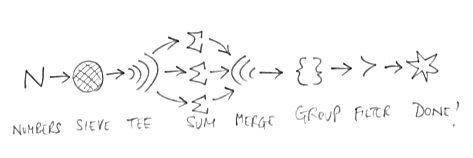
|
| Figure 1 |
Infinite series in other languages
Python is the language I find most convenient most of the time, which explains why I reached for it first. It’s an increasingly popular language, which helps explain why I didn’t need to write the tricky parts of my solution from scratch: they’d already been done. Python is also a language which makes compromises. Having used Python to find a solution to the puzzle I wondered if there wasn’t some other language better suited to this kind of problem.
Haskell makes no compromises when it comes to functional programming. Its lazy evaluation and inductive recursion make it a perfect fit for this kind of puzzle – but my approach of teeing, filtering and merging made me consider the Unix Shell. Now, I use Bash every day and page through its manual at least once a week. Scripting appeals and I’m comfortable at the command line. How hard could it be to solve this puzzle using Bash? After all, I already knew the answer!
Partial sums
Here’s a simple shell function to generate partial sums. I’ve used awk, a little language I gave up on a long time ago in favour of more rounded scripting languages like Perl and then Python. Now I look at it again, it seems to fill a useful gap. Awk processes a file sequentially, applying pattern-action rules to each line, a processing template which I’ve reinvented less cleanly many times. Despite my rediscovery of awk, I’ll be keeping its use strongly in check in what follows.
$ psum() { awk '{ print s += $1 }'; }
Much like Perl, awk guesses what you want to do. Here, it conjures the summation variable,
s
, into existence, assigning it a default initial value of 0. (Good guess!) Since we’re doing arithmetic awk converts the first field of each input line into a number. We can test
psum
by using
jot
to generate the sequence 1, 2, 3, 4, 5 (this is on a Mac – on a Linux platform use
seq
instead of
jot
).
$ jot 5 | psum 1 3 6 10 15
Consecutive sums
You may be wondering why we’ve bothered creating this partial sum filter since it’s the sums of consecutive elements we’re after, rather than the sum of the series so far. Well, notice that if
P[i]
and
P[i+n]
are two elements from the series of partial sums of S, then their difference,
P[i+n] - P[i]
, is the sum of the
n
consecutive elements from S.
So to form an n-element consecutive sum series we can
tee
the partial sums streams, advance one of these by n, then zip through them in parallel finding their differences. An example makes things clear – see Listing 4.
$ mkfifo pipe
$ jot 5 | psum | tee pipe | tail -n +2 | paste - pipe
3 1
6 3
10 6
15 10
15
|
| Listing 4 |
Here,
jot 5
generates the sequence 1, 2, 3, 4, 5, which
psum
progressively accumulates to 1, 3, 6, 10, 15. We then
tee
this partial sum series through two pipes: the first,
pipe
, is an explicitly created named pipe created by
mkfifo
, the second is implicitly created by the pipeline operator,
|
. The remainder of the command line delays one series by one (note that
tail
numbers lines from 1, not 0, so tail -n +1 is the identity filter) then pastes the two series back together.
2
By appending a single
awk
action to the pipeline we get a consecutive sum series (see Listing 5).
$ jot 5 | psum | tee pipe | tail -n +2 | paste - pipe | awk '{print $1 - $2}'
2
3
4
5
15
|
| Listing 5 |
The output 2, 3, 4, 5 is the series of consecutive sums of length 1 taken from the original series 1, 2, 3, 4, 5. The trailing 15 and the 1 missed from the start are edge case problems, and easily corrected.
Accumulating an increasing series of numbers in order to find the differences between elements lying a given distance apart on this series isn’t a very smart idea on a computer with a fixed word-size, but it’s good to know (e.g.) that awk doesn’t stop counting at 32 bits. (See Listing 6.)
$ let "N=1<<32" && echo $N | tee >(awk '{print $1 * $1}')
4294967296
18446744073709551616
|
| Listing 6 |
Exactly if and when awk stops counting, I’m not sure. The documentation doesn’t say and I haven’t looked at the source code.
Bug fixes
Let’s capture these tiny functions and name them. In Listing 7, then, are revised
psum()
and
sdiff()
filters. The edge case problems should now be fixed.
$ psum() { awk 'BEGIN { print 0 }{print s += $1 }'; }
$ delay() { let "n = $1 + 1" && tail +$n; }
$ sdiff() { mkfifo p.$1 && tee p.$1 | delay $1 | paste - p.$1 | \
awk 'NF == 2 {print $1 - $2 }'; }
|
| Listing 7 |
A quick test:
$ jot 5 | psum | sdiff 3 6 9 12
The output is, as expected, the series of sums of consecutive triples taken from 1, 2, 3, 4, 5 (6=1+2+3, 9=2+3+4, 12=3+4+5).
There’s a pernicious bug, though. These functions can’t handle infinite series so they are of limited use as pipeline tools. For example, if we stream in the series 0, 1, 2, … (generated here as the partial sums of the series 1, 1, 1, …) nothing gets output and we have to interrupt the process.
# This command appears # to hang $ yes 1 | psum | sdiff 1 ^C
To work around this is, we can use Gnu
stdbuf
to prohibit
tail
and
paste
from using output buffers (see Listing 8).
$ psum() { awk 'BEGIN { print 0 }{print s += $1 }'; }
$ delay() { let "n = $1 + 1" && stdbuf -o 0 tail +$n; }
$ sdiff() { mkfifo p.$1 && tee p.$1 | delay $1 | \
stdbuf -o 0 paste - p.$1 | \
awk 'NF == 2 {print $1 - $2 }'; }
|
| Listing 8 |
Now the data flows again:
# Accumulate the stream 1 1 1 ... and print the # difference between successive elements $ yes 1 | psum | sdiff 1 1 1 1 1 ^C
Merging streams
The Unix shell merges streams rather more succinctly than Python.
Sort -m
does the job directly. Note that a standard
sort
cannot yield any output until all its inputs are exhausted, since the final input item might turn out to be the one which should appear first in the output. Merge sort,
sort -m
, can and does produce output without delay.
3
$ yes | sort ^C $ yes | sort -m y y y y y ^C
Generating primes
No doubt it’s possible to generate the infinite series of prime numbers using native Bash code, but I chose to reuse the Python Cookbook recipe (Listing 9) for the job.
primes
#!/usr/bin/env python
import itertools
def primes():
'''Generate the prime number series: 2, 3, 5
... '''
D = {}
for n in itertools.count(2):
p = D.pop(n, None)
if p is None:
yield n
D[n * n] = n
else:
x = n + p
while x in D:
x += p
D[x] = p
for p in primes():
print(p)
|
| Listing 9 |
This is a subtle little program which makes clever use of Python’s native hashed array container, the dictionary. In this case dictionary values are the primes less than n and the keys are composite multiples of these primes. The loop invariant, roughly speaking, is that the dictionary values are the primes less than n, and the corresponding keys are the lowest multiples of these primes greater than or equal to n. It’s a lazy, recursion-free take of Eratosthenes’ sieve.
For the purposes of this article the important things about this program are:
- it generates an infinite series of numbers to standard output 4 , making it a good source for a shell pipeline
- by making it executable and adding the usual shebang incantation, we can invoke this Python program seamlessly from the shell.
Pipe connection
Recall the original puzzle:
Find the smallest number that can be expressed as the sum of 5, 17, 563 and 641 consecutive prime numbers, and is itself a prime number.
First, let’s check the connections by solving a simpler problem which we can manually verify: to find prime numbers which are also the sum of 2 consecutive primes. As we noted before, this is the same as finding primes numbers which are the consecutive sums of 1 and 2 primes.
In one shell window we create a couple of named pipes,
c.1
and
c.2
, which we’ll use to stream the consecutive sum series of 1 and 2 primes respectively. The results series comprises the duplicates when we merge these pipes.
$ mkfifo c.{1,2}
$ sort -mn c.{1,2} | uniq -d
In another shell window, stream data into
c.1
and
c.2
:
$ for i in 1 2; do (primes | psum | sdiff $i > c.$i) & done
In the first window we see the single number 5, which is the first and only prime number equal to the sum of two consecutive primes.
Prime numbers equal to the sum of three consecutive primes are more interesting. In each shell window recall the previous commands and switch the 2s to 3s (a simple command history recall and edit, ^2^3^, does the trick). The merged output now looks like this:
$ sort -mn c.1 c.3 | uniq -d 23 31 41 ...
We can check the first few values:
23 = 5 + 7 + 11 31 = 7 + 11 + 13 41 = 11 + 13 + 17
At this point we’re confident enough to give the actual puzzle a try. Start up the solutions stream.
$ mkfifo c.{1,5,17,563,641}
$ sort -mn c.{1,5,17,563,641} | uniq -c | grep "5 "
Here, we use a standard shell script set intersection recipe:
uniq -c
groups and counts repeated elements, and the
grep
pattern matches those numbers common to all five input streams.
Now we can kick off the processes which will feed into the consecutive sum streams, which sort is waiting on.
$ for i in 1 5 17 563 641; do (primes | psum | sdiff $i > c.$i) & done
Sure enough, after about 15 seconds elapsed time, out pops the result:
$ sort -mn c.{1,5,17,563,641} | uniq -c | grep "5 "
5 7002221
15 seconds seems an eternity for arithmetic on a modern computer (you could start up a word processor in less time!), and you might be inclined to blame the overhead of all those processes, files, large numbers, etc. In fact it took around 6 seconds for the Python program simply to generate prime numbers up to 7002221, and my pure Python solution ran in 9 seconds.
|
I used a MacBook laptop used to run these scripts.
|
Portability
One of the most convenient things about Python is its portability. I don’t mean ‘portable so long as you conform to the language standard’ or ‘portable if you stick to a subset of the language’. I mean that a Python program works whatever platform I use without me having to worry about it.
Non-portability put me off the Unix shell when I first encountered it: there seemed too many details, too many platform differences – which shell are you using? which extensions? which implementation of the core utilities, etc, etc? Readily available and well-written documentation didn’t help much here: generally I want the shell to just do what I mean, which is why I switched so happily to Perl when I discovered it.
Since then this situation has, for me, improved in many ways. Non-Unix platforms are declining as are the different flavours of Unix. Bash seems to have become the standard shell of choice and Cygwin gets better all the time. GNU coreutils predominate. As a consequence I’ve forgotten almost all the Perl I ever knew and am actively rediscovering the Unix shell.
Writing this article, though, I was reminded of the platform dependent behaviour which used to discourage me. On a Linux platform close to hand I had to use
seq
instead of
jot
, and
awk
formatted large integers in a scientific form with a loss of precision.
$ echo '10000000001 0' | awk '{print $1 - $2}'
1e+10
On OS X the same command outputs 10000000001. I couldn’t tell you which implementation is more correct. The fix is to explicitly format these numbers as decimal integers, but the danger is that the shell silently swallows these discrepancies and you’ve got a portability problem you don’t even notice.
$ echo '10000000001 0' | awk '{printf "%d\n",
$1 - $2}'
10000000001
Stream merge
I mentioned
stream_merge()
at the start of this article, a general purpose function written by Raymond Hettinger which I originally found in the Python Cookbook. As with the prime number generator, you might imagine the merge algorithm to be recursively defined:
- to merge a pair of streams, take items from the first which are less than the head of the second, then swap;
- to merge N streams, merge the first stream with the merged (N-1) rest.
Again the Python solution does it differently, this time using a heap as a priority queue of items from the input streams. It’s ingenious and efficient. Look how easy it is in Python (Listing 10) to shunt functions and pairs in and out of queues.
from heapq import heapify, heappop, heapreplace
def stream_merge(*ss):
'''Merge a collection of sorted streams.'''
pqueue = []
for i in map(iter, ss):
try:
pqueue.append((i.next(), i.next))
except StopIteration:
pass
heapify(pqueue)
while pqueue:
val, it = pqueue[0]
yield val
try:
heapreplace(pqueue, (it(), it))
except StopIteration:
heappop(pqueue)
|
| Listing 10 |
A more sophisticated version of this code has made it into the Python standard library, where it goes by the name of
heapq.merge
(I wonder why it wasn’t filed in
itertools
?)
Alternative solutions
As usual Haskell wins the elegance award, so I’ll quote in full a solution (Listing 11) built without resorting to cookbookery which produces the (correct!) answer in 20 seconds.
module Main where
import List
isPrime x = all (\i -> 0/=x`mod`i) $ takeWhile (\i -> i*i <= x) primes
primes = 2:filter (\x -> isPrime x) [3..]
cplist n = map (sum . take n) (tails primes)
meet (x:xs) (y:ys) | x < y = meet xs (y:ys)
| y < x = meet (x:xs) ys
| x == y = x:meet xs ys
main = print $ head $ \
(primes `meet` cplist 5) `meet` (cplist 17 `meet` cplist 563) `meet` cplist 641
|
| Listing 11 |
- CPython, more precisely — I don’t think anything in the Python language itself prohibits tail recursion. Even using CPython, yet another recipe from the online Python Cookbook explores the idea of an @tail_recursion decorator
- Tail is more commonly used to yield a fixed number of lines from the end of the file: by prefixing the line count argument with a + sign, it skips lines from the head of the file. The GNU version of head can similarly be used with a - prefix to skip lines at the tail of a file. The notation is {compact,powerful,subtle,implementation dependent}.
- Sort -m is a sort which doesn’t really sort — its inputs should already be sorted — rather like the +n option turning tail on its head.
-
The series is infinite in theory only: at time n the number of items in the
has_prime_factorsdictionary equals the number of primes less than n, and each key in this dictionary is larger than n. So resource use increases steadily as n increases.
