








Finding a square root is a common interview question. Patrick Martin demonstrates eight different ways to find a root.
Sigh… Some things we have to deal with … like interview questions. Recently I’ve been interviewing candidates a bit more and naturally some old coding exercises I’ve collected over time have come to the fore, along with some impressions I’ve developed.
Let’s assume it’s that time in the interview when the candidate shows signs of being suitable to step up to the next level. At this point it really starts to matter whether the interviewer has prepared sufficiently well for this eventuality. Therefore, a question that has several such plateaus to provide some good challenge for the candidates who are on a roll would be very useful. I’m also suggesting the topic should generate discussion points so that in the initial 15 minutes that the candidate and I are forming a mutual opinion, I will get (and generate) as representative an impression as possible. Remember, the candidate is also interviewing you, and they might well form an opinion if all you’re asking them to do is regurgitate facts.
So are there interview questions that have genuine ‘breadth and depth’? 1
Well, here’s a fun little question I’ve been carting along to interviews in note form for some time that I aim to persuade you will generate discussion points, and my notes have grown to either being
- a significant number of sheets of paper
- or one page of an entirely unusable font size
So, without further ado.
The question
Please implement the square root function[ Wikipedia_1 ] [ monkeys_sqrt ]
One thing I like about this question as that it’s really quite easy to run and test even in some minimal web based online coding tool.
What one learns in asking this question
-
First up: some people are really quite wary of
sqrt()in this context. I am not judging, let us be clear. - There is a giant range in the comfort level for working through the issues in implementing this deceptively simple function.
-
People are generally wrong to be frightened of the problem.
They often surprise themselves when they reach the end.
- There are quite a few approaches that are recognisable.
5.000000 stages of shock.
It would be a fair point that there is a sneaky element of testing character and resilience with this question. I am going to argue this is both legitimate and worthwhile, based on my assertion that [i] it’s not that hard and [ii] there is so much to discuss that running out of steam / time is not that much of an issue in the wider scheme of things.
Nevertheless it seems people pass through shock and a number of other stages when presented with this challenge: Denial, Anger, Bargaining, Depression. I would like to think we can short-circuit this and skip straight to Acceptance (and perhaps a little Fun?). Let’s dive in and see what I’m talking about.
Initial unstructured points
The exercise typically goes through a number of phases, sometimes the first of which is akin to scoping out the problem.
This can be a very revealing phase: demonstrating the candidate’s process for collecting information. Amusingly, some make adequate assumptions and plough on, because as we will see later: ‘double is just fine’ 2 , whereas some might ask about which arbitrary precision packages we’re allowed to use.
Assuming we’re here though: here’s an incomplete list of things one might want to touch upon
-
what is the return type?
discussion points might be considering arbitrary precision
-
what’s the input type?
discussion points – is it the same as the return type, what bit size is the range, compared to the domain? 2
-
what happens for inputs of 1, > 1, < 1 or negative values?
is this going to influence your thinking on the approach you take?
- what is your criterion for accuracy?
- how about float denormal values inputs, results [ Wikipedia_2 ]
- what about NAN, NaNQ, NaNS? [ Wikipedia_3 ]
-
‘Oh hey, what do CPUs do?’
discussion points
3
you may want to keep your powder dry when asked, so push it, and pop it later
-
finally, $bright_spark may well know the POSIX prototypes [
posix
].
These prototypes address a lot of the above questions
#include <math.h> double sqrt(double x); float sqrtf(float x); long double sqrtl(long double x);
Eight approaches
So, having got past the initial stage of get to know the question, it’s probably time to start writing code. Here follow eight implementations of varying quality, nominally in C++.
Caveat
Please remember that for some of these implementations, it may be hard to find canonical examples ‘out there’ of some of these algorithms. This is because they are in fact a bit rubbish. The more ‘recognisable versions’ are pretty much shadows of the many already thoroughly written-up versions available for research. Remember though, the name of the game here is to get discussion points , any and all means are acceptable.
Alien technology
An additional benefit of these discussions is when a novel-looking implementation arises, having some preparation under your belt will serve you well in recognising a variant of one of the following principles and steering the code/conversation in a more productive direction for discussion points .
‘One liners’
Closed form FOR THE WIN
Explanation: closed form for the win!
return exp(0.5 * log(val));
This hinges on the identity
log x y = y log x
and if we remind ourselves that the power that generates a square root is 0.5, and exp is the inverse of log
sqrt( x ) == x 1/2 , log(exp( x )) == x
it all drops into place. 4
Note that I did eliminate
pow(x, 0.5)
as a possible solution as that felt a bit too much like cheating to me.
Search algorithms
This class of solution hinges on iterating upon a trial value until convergence is attained – I’ve introduced a
seed_root()
function with no explanation that returns a ‘good initial guess’ for sqrt() in order to concentrate on the details. We’ll come back to
seed_root()
later on.
The Babylonian method or Hero’s method
The graphical explanation of this algorithm is: iterative search for square root by successive reduction of difference in length between the 2 sides of a rectangle with the area of the input value. [ Wikipedia_4 ]:
pick side
derive other_side by A / side
if side == other_side: return side
else split the difference for the next side and loop
and hence Listing 1.
double my_sqrt_bablyonian(double val) {
double x = seed_root();
while (fabs((x * x) - val) > (val * TOLERANCE))
{
x = 0.5 * (x + (val / x));
}
return x;
}
|
| Listing 1 |
The loop is controlled by a test on whether we’re ‘near enough’ to the answer, which may be a discussion point . Also note the mechanism for generating a new trial value always narrows the difference between the trial and trial / input.
Notable points:
- it’s quite possibly the only algorithm to be presented here that you can implement using a piece of rope and a setsquare. See [ Wikipedia_5 ] for the classical Ancient toolset
- this algorithm is somewhat unique in that it can handle finding the negative root if the trial value passed in is negative
- there is one more interesting fact we will discover shortly
Although there is the amazing Bablyonian Tablet YBC 7289 [ YBC7289 ], it’s hard to find a lo-fi image of this implementation so I persuaded a 12-year old to do it for me. Figure 1 shows a Hero’s Method contemporary reimplementation for the value 23. We started with a trial value of 6 and got the result 4.8 which is accurate to 0.08%.
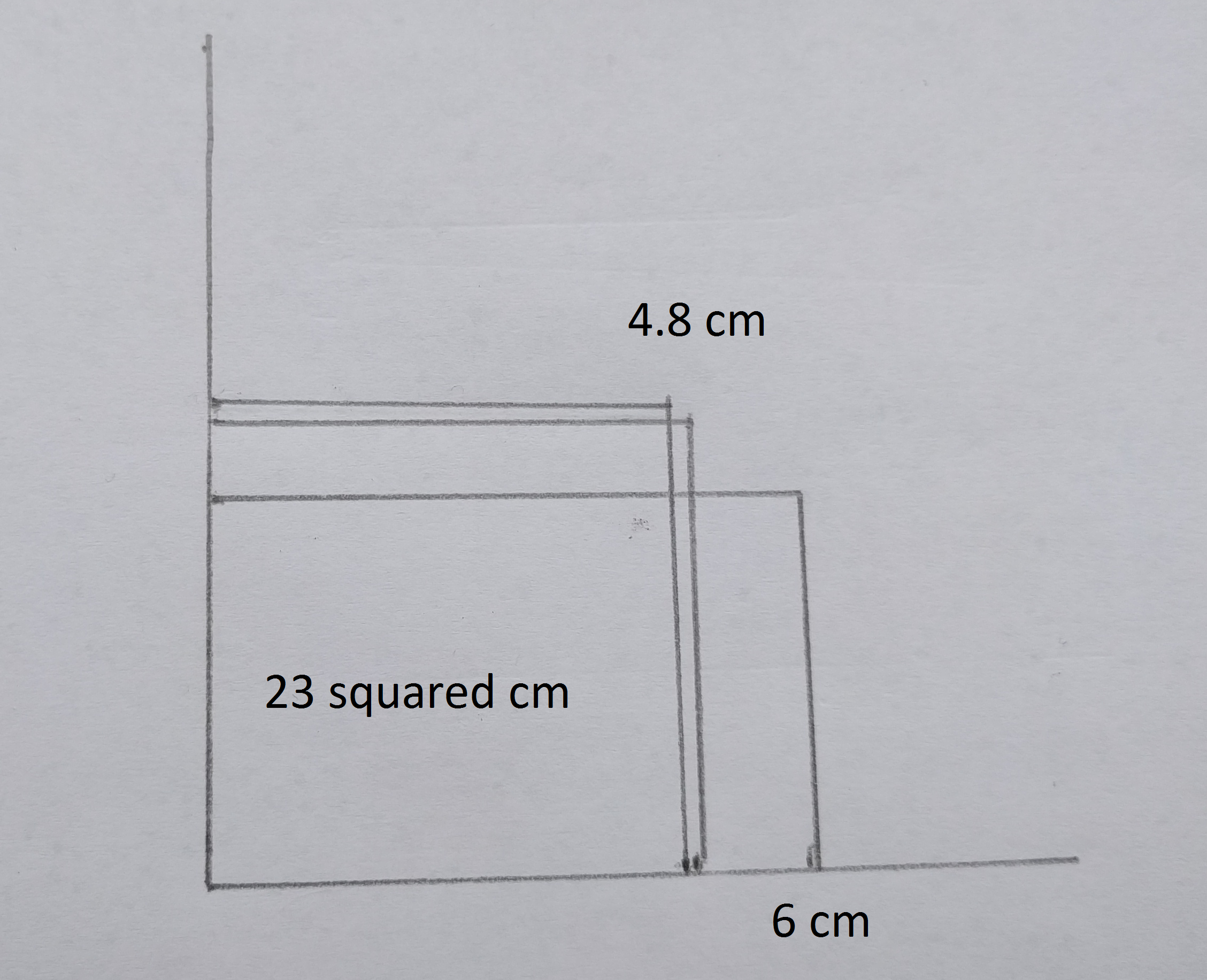
|
| Figure 1 |
Note the Babylonian tablet has sqrt(2) to 9 decimal digits of precision – how did they do that?
Finding the root using Newton Raphson
Explanation: Newton Raphson [ Wikipedia_6 ] searches for the value of x yielding zero for x 2 - value, (hence x 2 = value)
Graphical explanation:
pick a trial value
search for the zero
by building the line passing through
the current trial output with the gradient
of the function at that point
– a numerically estimated gradient will do, for discussion points .
the intersection of that triangle with zero is the new trial
exit when desired accuracy attained
Listing 2 is one interpretation.
double my_sqrt_newtonraphson(double val) {
double x = seed_root();
while (fabs((x * x) - val) > (val * TOLERANCE))
{
// x * x - value is the root sought
double gradient =
(((x * 1.5) * (x * 1.5)) -
((x * 0.5) * (x * 0.5))) / (x);
x = x - ((x * x - value) / gradient);
}
return x;
}
|
| Listing 2 |
For discussion points see also the related Householder methods [ Wikipedia_7 ]
Newton Raphson with a closed form identity for the gradient
Now, some may know that there is a very simple result d( x 2 )/d x = 2 x for the gradient that is needed for Newton Raphson and hence plugging in the closed form result for dy / dx , we can skip some typing to yield this (see Listing 3).
double my_sqrt_newtonraphson(double val) {
double x = seed_root();
while (fabs((x * x) - val) > (val * TOLERANCE))
{
// x * x - val is root sought
x = x - ((x * x - val) / (2 * x));
}
return x;
}
|
| Listing 3 |
Note the original expression containing the gradient:
double gradient = ((( x * 1.5) * ( x * 1.5)) - (( x * 0.5) * ( x * 0.5)));
This is the lazy man’s version of calculating the gradient around the domain value x using the values at x +/- b.
( x + b ) 2 - ( x - b ) 2 / 2 b
= x 2 + 2 bx + b 2 - x 2 + 2 bx - b 2 / 2 b
= 2 x
If b were a constant this would not scale with the value of x ; however, b can be substituted by x /2 and we recover the initial gradient calculation, and hence an equivalent expression for the closed form expression.
Confession time: I first picked 0.5 * x and 1.5 * x intuitively, having been hand-bodging numerical estimates into code for some time now, so I didn’t think too hard about it (this time around) and serendipitously hit a solution that can be transformed using simple algebra into the closed form solution.
3.0, 2.0 or 1.0 methods?
So far the last 3 solutions have used identical outer loops, merely with different expressions for generating new trial values in the middle. Let’s take a closer look at that expression: with the closed form for the gradient we get this expression:
x = x - (( x * x - value) / (2 * x ));
⇒ x = 0.5 * (2 x - ( x - (value / x )))
⇒ x = 0.5 * ( x + (value / x ))
This is the Hero’s method expression, so the final notable point about Hero’s method is that it’s a condensed version of the more taxing Newton Raphson approach.
Confession time
Having encountered the two methods (Babylonian and Newton Raphson) independently, I missed the equivalence between them until I took a look at the iteration values.
Another confession – even with the mathematical equivalence, there was still a difference as the version just shown has an issue: it fails to locate values for roots above sqrt(
std::numeric_limits::max()
). This is due to an overflow in the expression to generate the new trial value.
The fix – perhaps unsurprisingly enough – is thus:
- double x = seed_root();
+ long double x = seed_root();
Another set of discussion points arise from the necessity of introducing the long version of the type in the algorithm. Is this choice leading to an implicit conversion in the return statement a maintenance wart? What if we need this to be a generic algorithm, parameterised on the input type?
Slow but sure (?)
A range reduction approach
Graphical explanation: a range reduction approach which aims to halve the range [upper, lower] upon each iteration (does not rely upon a particularly good initial guess, though the bounds do need to be ordered). Newton Raphson / Hero can be proven to converge quadratically [ Wikipedia_8 ], whereas this approach effectively converges linearly, hence it requires many more iterations. The algorithm takes 30 iterations for a double sqrt as achieving over 10 digits of decimal precision will typically require approximately 30 halvings of the interval. (See Listing 4.)
double my_sqrt_range(double val) {
double upper = seed_root(value) * 10;
double lower = seed_root(value) / 10;
double x = (lower + upper) / 2;
int n = 1;
while ((n < RANGE_ITERATIONS) &&
(fabs((x * x) - value) > (value * TOLERANCE)))
{
if (((x * x) > value))
upper = x;
else
lower = x;
x = (lower + upper) / 2;
n++;
}
return x;
}
|
| Listing 4 |
If this is found in the wild it would probably be best to put it out of its misery. The possible benefit of this is that candidates less confident of their mathematics will be able to implement this by concentrating purely upon the logic of searching.
Scan and step reduction
This is a very naive guess step and scan approach, reversing and decreasing the step on each transition from above to below. Feed it a decent enough initial guess and it will work its way towards the solution, as it is another linearly convergent solution. (See Listing 5).
double my_sqrt_naive(double val) {
int n = 1;
double x = seed_root(value) / 2;
double step = x / 4;
double lastdiff = 0;
double diff = (x * x) - value;
while ((n < RANGE_ITERATIONS) &&
(fabs(diff) > (value * TOLERANCE))) {
if (diff > 0)
x -= step;
else
x += step;
if ((diff > 0) != (lastdiff > 0)) {
step = step * 0.5;
}
lastdiff = diff;
diff = (x * x) - value;
}
return x;
}
|
| Listing 5 |
‘Homage to Carmack’ method
Finally, the origin of seed_root() can be revealed. Yes, just for fun, an old example of a very fast approximate inverse square root. Here is the obligatory xkcd reference [xkcd_1]. This still works (on Intel), and there is also a good write-up of how this works [ Wikipedia_9 ]. Note there are other values for the magic value than 0x5f375a86 – which oddly get more search hits in Google(?!!).
The original code, sadly has comments and
#ifdef
rendering it unsuitable for printing in a family oriented programming publication, so Listing 6 is a modified version from Stack Overflow [
SO_2
], and Listing 7 is a version supporting
double
, with the appropriate 64-bit magic value.
float my_sqrt_homage_to_carmack(float x) {
// PMM: adapted from the doubly cleaner
// Chris Lomont version
float xhalf = 0.5f * x;
int i = *(int *)&x;
// get bits for floating value
i = 0x5f375a86 - (i >> 1);
// gives initial guess y0
x = *(float *)&i; // convert bits back to float
// PMM: initial guess: to within 10% already!
x = x * (1.5f - xhalf * x * x);
// Newton step, repeating increases accuracy
return 1 / x;
}
|
| Listing 6 |
double my_sqrt_homage_to_carmack64(double x) {
double xhalf = x * 0.5;
// get bits for floating value
long long i = *(long long *)&x;
// gives initial guess y0
i = 0x5fe6eb50c7b537a9 - (i >> 1);
// convert bits back into double
x = *(double *)&i;
// one Newton Raphson step
x = x * (1.5f - xhalf * x * x);
return 1 / x;
}
|
| Listing 7 |
The result is not super accurate, but works in constant time and can be used as a seed into another algorithm.
For the most condensed explanation as to how that even works, see the closed form solution and consider that the bits of a floating point number when interpreted as an integer can be used to approximate its logarithm.
‘Also ran’
In the grand tradition of sort algorithms [ Wikipedia_10 ], one could always break the ice by discussing solutions that make brute force look cunning.
brutesqrt
d = min_double()
while true:
if (d * d == input) return d
d = next_double(d)
bogosqrt (homage to bogosort)
d = random_double()
while true:
if (d * d == input) return d
d = random_double()
This and the prior approach will need an approach to define the accuracy of match. And perhaps a rather forgiving user calling that code.
Quantum computer method
for value in all_doubles:
return value if value ^ 2 == input
It would be hoped that parallelising this would lead to good wall clock times?
Code and tests
Code demonstrating C++ implementations with tests of all the following are available at: http://www.github.com/patrickmmartin/2.8284271247461900976033774484194
Conclusion
So, let’s review what we can get out of ‘implement sqrt()’ in terms of discussion topics : closed form results versus algorithmic solutions – discussion on the many interesting properties of floating point calculations, bronze age mathematical algorithms, consideration of domains and ranges. I haven’t even touched upon error handling, but it’s needed.
And finally there are other really fascinating techniques I haven’t touched upon as I judged them too abstruse for an interview scenario: like Lagrange’s continued fractions [ Wikipedia_11 ], and also the Vedic techniques mentioned in [ Wikipedia_1 ].
You may have some questions.
Here’s my attempt to anticipate them.
-
What’s with the name for the repo?
It’s the square root of 8, the number of methods, of course cube root would be have yielded a simpler name – presaging the next installment! Of course, there will be no next installment, as one thing we have learned is that this topic is a giant nerd trap [ xkcd_2 ]. Merely perusing the references to this article for a short time will show how many areas of exploration exist to be followed.
-
Will the Fast sqrt work on big-endian?
Very funny.
Acknowledgements
I would like to take the opportunity to thank Frances Buontempo and the Overload review team for their careful review comments.
Gabriel Martin recreated the ancient world glories of calculating the square root of 23.
Also thanks to Hillel Y. Sims for spotting an issue in a code sample that got past everyone.
References
[monkeys_sqrt] http://www.azillionmonkeys.com/qed/sqroot.html
[posix] http://pubs.opengroup.org/onlinepubs/9699919799/functions/sqrt.html
[SO_1] http://math.stackexchange.com/questions/537383/why-is-x-frac12-the-same-as-sqrt-x although the alleged duplicate has a beautiful answer: http://math.stackexchange.com/questions/656198/why-the-square-root-of-x-equals-x-to-the-one-half-power
[SO_2] http://stackoverflow.com/questions/1349542/john-carmacks-unusual-fast-inverse-square-root-quake-iii
[SAR] http://assemblyrequired.crashworks.org/timing-square-root/
[Wikipedia_1] https://en.wikipedia.org/wiki/Methods_of_computing_square_roots
[Wikipedia_2] https://en.wikipedia.org/wiki/Denormal_number
[Wikipedia_3] https://en.wikipedia.org/wiki/NaN
[Wikipedia_4] https://en.wikipedia.org/wiki/Methods_of_computing_square_roots#Babylonian_method
[Wikipedia_5] https://en.wikipedia.org/wiki/Compass-and-straightedge_construction
[Wikipedia_6] https://en.wikipedia.org/wiki/Newton%27s_method
[Wikipedia_7] https://en.wikipedia.org/wiki/Householder%27s_method
[Wikipedia_8] https://en.wikipedia.org/wiki/Rate_of_convergence
[Wikipedia_9] https://en.wikipedia.org/wiki/Fast_inverse_square_root
[Wikipedia_10] https://en.wikipedia.org/wiki/Bogosort
[Wikipedia_11] https://en.wikipedia.org/wiki/Square_root
[xkcd_1] http://www.xkcd.com/664/
[xkcd_2] https://xkcd.com/356/
[YBC7289] https://www.math.ubc.ca/~cass/Euclid/ybc/analysis.html
- Why are we using questions?
- For IEEE 754 double, the maximum sqrt will exceed the maximum value for IEEE 754 float, so this forces us to consider the same return type as the input type.
- These might be using dedicated FPU hardware or native CPU commands. In the silicon itself, one might find GoldSchmidt’s method, or Newton Raphson; Some Assembly Required [ SAR ] has a large number of interesting comparisons, including old and modern native SQRT instructions.
- When multiplied, powers are added, hence sqrt is pow(0.5). Two very good examples of working through this identity are available at [ SO_1 ].
