








Predicting how long something will take is hard. Seb Rose takes us on a brief tour through the swamp that is estimation.
What are estimates for?
Estimates seem to be an essential part of the software development process. People want to know how much things will cost before work starts, and want regular updates on how we’re performing as the project progresses. This seems entirely reasonable until you start looking under the covers at why we’re being asked for estimates and what we’re saying when we give them.
Estimates can be broadly categorised into two types: forecasting and tracking. Forecasts are used before a project starts to decide if it is worth implementing, while tracking estimates are used during project development to manage resources and act as a project health indicator.
Humans aren’t good at estimating in general [ Bowle ]. We’re over optimistic, as described by Pullitzer prize winner Douglas Hofstadter:
It always takes longer than you expect, even when you take into account Hofstadter’s Law.
Steve McConnell wrote a whole book about trying to ‘demystify the black art’of software estimation [ McConnell ], which in the end is far too theoretical and (to my mind) largely impractical. DeMarco and Lister take a less formal approach [ DeMarco ], advising us to emphasise the imprecision of our estimates. Despite these, and other contributions to the field, I’ve seen no evidence to suggest that estimates have got any better over the past 30 years.
Investment decisions
Some years ago, I was working for a retail bank when I was asked to estimate how long it would take to implement a new feature. It took several days to analyse the requirements and come up with a ‘ballpark’ estimate of 3 months. The client reacted with horror, “That’s too long!” but I stuck by the estimate and the feature was shelved.
Why was it shelved? In a rational world it might have been shelved because the value of the feature wasn’t worth the investment. I never saw any prediction of the feature’s value (I don’t believe they had one), but I don’t think this was the reason. I think that they had identified a ‘resource’ surplus and were trying to see if a low priority feature would ‘fit’. When it didn’t, they simply left it.
Five months later they came back with the same feature request and asked me to estimate it again. My estimate remained the same and the request was shelved again. They came back again a couple of months later with the same request. Same outcome.
Why did they keep asking the same question? Partly because they had forgotten that it had already been estimated and partly because they hoped that this time the estimate would ‘fit’ their plan. I’ve spent months of my life being asked to re-estimate features to try and get the numbers smaller. I’ve also had managers cut my estimates before passing them to clients. We don’t want to disappoint people (especially our bosses) so we tell them what they want to hear – recriminations will happen in the future and, anyway, we might just get lucky on this project.
Waltzing bears
Demarco and Lister said, “ If a project has no risk, then don’t do it ” [ DeMarco ]. This isn’t intended to encourage us to do dangerous things, it’s simply an observation that when we deliver value we are going to do something new, which is inherently risky. They talk at length about why estimates are often interpreted as commitments, and why we should provide estimates as a range with our level of confidence of being able to deliver within that range. So, instead of providing a ‘point’ estimate that a project will take 6 months, restate it as “I am 95% confident that we can deliver this within a 3 month to 24 month period.” This is a probability distribution around the original ‘point’ estimate of 6 months. That seems like a huge range, and it is. However, they observe that a 400% overrun (based on ‘point’ initial estimates) is not uncommon in our industry.
Steve McConnell has documented the Cone of Uncertainty [ McConnell ], which describes how our estimates become more accurate as a project progresses. I believe this assumes that we address the most risky parts of the project early, which itself assumes that we ‘know’ what the most risky parts are. As Donald Rumsfeld observed [ Rumsfeld ], however, there’s always the possibility that there are ‘Unknown unknowns’ lurking, that could come to light at any time to de-rail the project.
The other observation is that The Cone of Uncertainty is symmetric – implying that projects are just as likely to come in below estimate as over estimate. Laurent Bossavit has looked into the research that underpins this [ Bossavit ] and has found that it does not support this assumption. Depressingly, it seems that empirical evidence shows that projects rarely come in quicker than our ‘point’ estimates, so the estimate quoted above becomes ‘I am 95% confident that we can deliver this within a 6 month to 24 month period.’
Over confident
Even with such a wide estimate, how can we be 90% confident? Maybe this is based on relevant historical data from your organisation, but every project is different. Different problems, different teams, different context. And we are very bad at estimating – including estimating confidence.
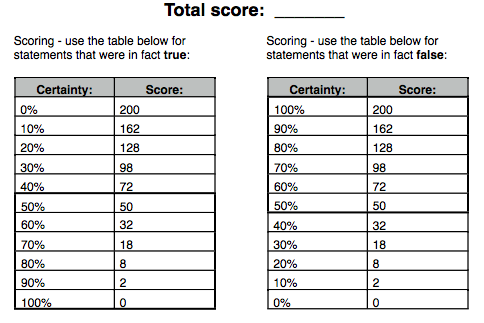
The Brier Score [ Brier ] is a ‘proper score function that measures the accuracy of probabilistic predictions’. Try this yourself at home (thanks to Laurent Bossavit):
Instructions: for each of the statements below, please give an answer between 0% (you are totally certain it is false) and 100% (you are totally certain it is true) – an answer of 50% means you are unable to say one way or the other. No cheating by looking things up!
- The language JavaScript was released to the public after 31/12/1994. Certainty: ____
- As of January 2013, LinkedIn reports more registered users than Brazil has citizens. Certainty: ____
- UML (Unified Modeling Language) is a registered trademark of IBM Rational. Certainty: ____
- The average salary for an engineer in test (SDET) at Google is > 85K$ (55K£) yearly. Certainty: ____
- More than 3000 people registered for the Agile2012 conference in the US. Certainty: ____
Now calculate your Brier score .
How small is your Brier score? The good news is that we can train ourselves to be less over-confident [ Web1 ] [ Web2 ] [ Web3 ]. The bad news is that it is very hard to become more precise.
The ROI fallacy
The forecasting charade has two sides: estimation and value. From this, we are told, those who know best can determine the return on investment (ROI). The magic number that predicts whether our work will deliver value to the business or not.
In my experience their value predictions are even less robust than our estimates. They surface in the project proposal documents and, once the project has kicked off, are never seen again. I have never seen an organisation track the value delivered and compare this to the value promised. Partly, this is because success criteria are not rigorously defined in advance and partly this is because tracking value delivered is itself highly subjective.
For example, a team I worked beside at a large online retailer was responsible for the algorithms that delivered targeted advertising on their checkout page. This team is the jewel in the crown of that development centre because, based on a few hours of outage several years ago, they have calculated a massive amount of extra up-sales based on their algorithms. Whether these sales are truly attributable to the algorithms is unknown, and the number is so large that no one wants to turn them off for a longer period to do a more significant investigation.
Anyone for poker?
Once the project has kicked off, teams are often asked to break the coarse functionality down into fine grained tasks and estimate these individually. Within some agile methods this is done to decide how much work the team can commit to completing in the iteration. The de facto method in use today is Planning Poker [ Poker ].
Planning Poker has some theoretical basis. By asking the whole team to make independent estimates we make use of diverse opinions [ Berra ]. Diverse opinions (aka the wisdom of crowds) harnesses the ‘Diversity Prediction Theorem’, which basically says that a “ diverse crowd always predicts more accurately than the average of the individuals ”. Of course this depends on the the group being diverse. How diverse is your team?
The team will discuss the task, but are supposed not to talk about task size. Each member estimates the size ‘in secret’ and then the whole team reveal their estimation at the same time. This is intended to avoid the phenomenon of ‘anchoring’, which is when some members of a group are influenced by the opinions of others – which would negate their independence. In case of disagreement, however, planning poker then requires further rounds of discussion and estimation, during which anchoring becomes very evident.
| Anchoring |
In an experiment conducted in 1956, a group was asked to compare the lengths of a reference line with three other lines marked A, B, and C.
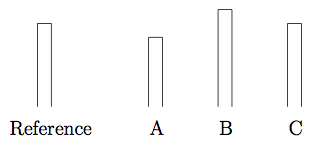 Each group member was asked, in turn, to compare A, B and C to the reference line and decide whether it was longer, shorter or the same length. In groups that had members, planted by the researcher, answer first with purposefully wrong answers, it was found that the rest of the group then went on to give incorrect answers about a third of the time. [
Asch56
]
Each group member was asked, in turn, to compare A, B and C to the reference line and decide whether it was longer, shorter or the same length. In groups that had members, planted by the researcher, answer first with purposefully wrong answers, it was found that the rest of the group then went on to give incorrect answers about a third of the time. [
Asch56
]
|
Relativity
As has already been stated, humans have been found to be bad at estimating. However, we are somewhat less bad at comparing equivalent tasks. Estimating using story points harnesses this by asking the team to compare the current task to tasks already completed and scoring it accordingly. In this way we make our estimates relative.
This benefit is clearly hard to realise at the beginning of a project when there is little historical data to go on. It’s also difficult to make comparisons when the task being estimated is different to anything the team has done before. And if the stories being estimated are large, then it is hard to to make realistic comparisons.
For most teams I have worked with, the biggest single change that can make their task estimation more accurate is to break every story down into several, much smaller stories. This is something that most teams find incredibly hard, not helped by the belief that agile methods require each story to deliver a complete piece of end-user functionality. The team’s ‘definition of done’ should allow teams to use low-fidelity [ Scotland ] stories to incrementally deliver valuable functionality, but is being generally misapplied to keep stories large.
One of the best examples I’ve heard about is from when Matt Wynne worked at Songkick [ Wynne ]. They systematically decomposed their stories till they reached a size that could usually be fully implemented in 1 day. They were then able to skip the estimation phase entirely and simply predict how many stories could be delivered in an iteration. How good does that sound?
No estimates
Over the past year or so there has been a #NoEstimates thread running on Twitter. Two of the major proponents are Woody Zuill [ Woody ] and Neil Killick [ Killick ] who argue that since estimates are little more than guesses they deliver no value. Work that delivers no value is waste and so should be avoided.
The debate was interesting and useful, but, as Ron Jeffries pointed out [ Jeffries ] this is a reminder of an idea that was discussed earlier this century by Arlo Belshee and Joshua Kerievsky. Ron also pointed out some issues that most teams will have getting their organisation to agree to working without estimates. I’m not going to repeat the whole discussion here – go read the blog posts :)
Instead, I’ll relate a story about a team I was working with earlier this year. They were very keen to work in a more responsive and responsible way, with all team members collaborating during the development process. The company, like so many, has serious cost constraints which led the executives to want more certainty around project costs, for which they needed ever more accurate estimates.
I tried to persuade the team that this extra estimation work would mean they had less time to deliver value to the business. I explained the tension between detailed, up-front estimation of a project and more lightweight just-in-time, last-responsible-moment techniques. The team accepted all my arguments, but would respond with “ Yes, but in this financial situation they need to know how much it will cost. ” They didn’t feel it was a battle worth fighting, and I believe that this is a common situation.
What a Bohr
Niels Bohr is credited with having said that “ Prediction is very difficult, especially about the future. ” There’s no evidence that Bohr ever said this [ Bohr ], so I feel justified in modifying the statement to “ prediction is very difficult, even about the past ”.
We don’t know how long a project is going to take until we do it and even once we’ve done it we a) don’t really know how long it took us and b) won’t know how long it would take us to do again. And yet we are regularly asked for estimates and regularly give them. In a bid to reframe the debate, Allan Kelly wrote a ‘Dear Customer’ letter [ Kelly ] explaining how estimates are being used as tools to try and shift the risk one way or the other. Any claim that they are scientifically derived is questionable at best.
Can you quote me for that?
There is another famous quotation, dubiously attributed to Disraeli which describes ‘ the persuasive power of numbers, particularly the use of statistics to bolster weak arguments ’. [ Disraeli ] Irrespective of its actual provenance, I think it is equally applicable to the realm of estimates: ‘There are lies, damn lies and estimates’.
Estimates produced before a project starts are lies about how much something will cost, usually tailored depending on whether the source of the estimate wants the project to go ahead or not. Estimates produced once a project has started are lies that compensate for the inaccuracies of earlier estimates. Both contribute towards an illusion of control that is no more real in software than it is in civil engineering (see the Edinburgh Tram project, for example [ Edinburgh ]).
Until customer and development team operate from a basis of trust, estimates will remain the weapon of choice. They will continue to be misinterpreted as commitments, and the next death march will always be just around the corner. But as Ron Jeffries says, the “ old fogies know your estimates will be bogus, they know you won’t get them right, they know you won’t hit the deadline with full scope ” [ Jeffries2 ]. So, stay calm, make your best guess and have that estimate on my desk on Monday morning.
| Calculating Your Brier Score |
Confidence Quiz Answers 1) True; 2) True; 3) False; 4) True; 5) False
|
References
[Asch56] Asch, S. E. (1956). ‘Studies of independence and conformity: A minority of one against a unanimous majority’ Psychological Monographs , 70: 416
[Berra] http://vserver1.cscs.lsa.umich.edu/~spage/teaching_files/modeling_lectures/MODEL5/M18predictnotes.pdf
[Bohr] http://en.wikiquote.org/wiki/Niels_Bohr
[Bossavit] https://leanpub.com/leprechauns
[Bowle] http://blog.robbowley.net/2011/09/21/estimation-is-at-the-root-of-most-software-project-failures/
[Brier] http://en.wikipedia.org/wiki/Brier_score
[DeMarco] http://www.amazon.co.uk/Waltzing-Bears-Managing-Software-Projects/dp/0932633609
[Disraeli] http://en.wikipedia.org/wiki/Lies,_damned_lies,_and_statistics
[Edinburgh] http://en.wikipedia.org/wiki/Edinburgh_Trams
[Jeffries] http://xprogramming.com/articles/the-noestimates-movement/
[Jeffries2] http://xprogramming.com/articles/artifacts-are-not-the-problem/
[Kelly] http://agile.techwell.com/articles/original/dear-customer-truth-about-it-projects
[Killick] http://neilkillick.com
[McConnell] http://www.amazon.co.uk/Software-Estimation-Demystifying-Black-Art/dp/0735605351
[Poker] http://en.wikipedia.org/wiki/Planning_poker
[Rumsfeld] http://en.wikipedia.org/wiki/There_are_known_knowns
[Scotland] http://availagility.co.uk/2012/09/14/feature-injection-fidelity-and-story-mapping/
[Web1] http://predictionbook.com/
[Web2] https://www.goodjudgmentproject.com/
[Web3] http://calibratedprobabilityassessment.org/
[Woody] http://zuill.us/WoodyZuill/
