








Comprehensibility of end-to-end scenarios and quick feedback of unit tests are competing goals. Seb Rose introduces Cucumber with tags to meet both needs.
I was talking to a senior developer at a conference recently who was very supportive of TDD. However, he couldn’t see why anyone would want to automate examples that were written in a way that was understandable by business folk – analysts, customers, product owners and so on. His experience was that the business people never participated in creating the examples and weren’t interested in looking at them once they were automated. He also believed that the examples were frequently duplicated in unit tests and that since the unit tests ran so much faster, there was nothing to be gained from automating at the business level. In this article I want to examine this position and try to describe a way out of the impasse.
Business engagement
First, we need to address the lack of engagement of the business. The regular complaint is that the business people are too busy to spend time working on the examples with the development team, and the only way round this is to point out that unless someone who understands the business’s needs is involved in the product evolution, then it’s unlikely that the end result is going to be satisfactory. There are lots of ways to arrange business involvement, from having a fully empowered Product Owner co-located with the development team, through to scheduling regular times that a business person will be available to work with the team. The key point is that whoever works with the team needs to be authorised to make decisions regarding the development of the product – if all questions lead to an “I’ll get back to you on that” then there will be problems.
A less satisfactory solution is for the development team to produce all the examples and then have them reviewed and signed-off. Many of the benefits of deriving the examples collaboratively are lost if you work this way:
- Deliberate discovery [ Keogh12 ] – by having representatives of diverse stakeholder communities working collaboratively you can efficiently drive out more hidden issues than having them work separately. This harnesses the observed ‘wisdom of crowds’ phenomenon.
- Ubiquitous language [ Fowler ] – communication is about shared understanding. It’s all too common for a term to have subtly different meanings to different communities, and the most effective way to combat this is to have those communities develop the organisation’s vocabulary together.
- Immediate feedback – any process that involves hand offs between disparate groups is introducing delays, which affect the ability of the organisation to deliver value and respond to change.
Notice that I’m not talking about automation at all. No tools have been mentioned. Nor have I introduced any of the techy acronyms (BDD [ North ], ATDD [ Hendrickson ], SbE [ Adzic11 ], EDD, TDD). I’m talking about collaboration pure and simple. This style of collaboration has been popularised by the Agile Manifesto [ Agile ], one of whose principles states:
The most efficient and effective method of conveying information to and within a development team is face-to-face conversation.
You don’t have to be agile to work like this (most organisations that think they are ‘agile’ don’t work like this), but working like this will improve communication in any organisation and remove many of the hurdles from the real job of delivering something that the customer wants.
Automated examples
At this point you can decide to go no further, but there is great value to be had by considering automating some (or all) of the examples that were collaboratively authored:
- Living documentation – consider how often you have seen documentation that is out of date. By writing examples that demonstrate the behaviour of the system by actually executing against it, your documentation will always be up to date (as long as the examples all pass).
- Regression pack – since the examples describe the behaviour of the system, if that behaviour changes unexpectedly then some examples will fail.
- Feedback speed – because the examples run automatically against the system, they can be run frequently. The limiting factor for feedback speed is how quickly they run, but this will always be quicker than running an equivalent suite of manual tests.
Once you have decided to automate, you’ll need to choose your approach. For the purposes of this article I will use examples written in Gherkin [ Cucumber ] (which interprets examples for Cucumber [ Cucumber ]). I am a fan of Cucumber/Gherkin, but there are many other tools available, most of which will automate the execution of examples.
Let’s assume we have the example below, that deals with registering at some website:
Feature: Sign Up Scenario:
New user redirected to their own page
When I sign up for a new account
Then I should be taken to my feeds page
And I should see a greeting message
When Cucumber runs this scenario (example) it tries to match each step (introduced by the keywords Given, When, Then, And, But) with some glue code that exercises the system under test. The glue code can be written in various languages, depending on which port of Cucumber you are using, but for the purposes of this article I will limit myself to Java and so will be using Cucumber-JVM [ Hellesøy12 ]. Each method in the glue code is annotated with a regular expression, against which Cucumber tries to match the text of each step:
- if there is no match, Cucumber generates an error
- if there are multiple matches Cucumber generates an error
-
if there is exactly one match, Cucumber executes the method in the glue code
- if the method returns without raising an exception the step passes
- if an exception propagates out of the method the step fails
How you implement the step definitions is up to you, and depends on the nature of your system. The example above might:
- fire up a browser, navigate to the relevant URL, enter specific data, click the submit button and check the contents of the page that the browser is redirected to
- call a method on a Registration object and check that the expected event is fired, with the correct textual payload
- or anything else that makes sense (e.g. using smart card authentication or retina scanning).
The point is that the text in the example describes the behaviour, while the step definitions (the glue code) specify how to exercise the system. An example glue method would be:
@When("I sign up for a new account")
public void I_sign_up_for_new_account() {
// Do whatever it takes to sign up for a new account
}
Examples everywhere
Newcomers to this style of working often adopt a style in which every example is executed as an end-to-end test. End-to-end tests mimic the behaviour of the entire system and create an example’s context by interacting directly with the UI, and the full application stack is involved throughout (databases, app servers etc.). This sort of test is very useful for verifying that an application has deployed correctly, but can become quite a bottleneck if you use it for validating every behaviour of the system. The Testing Pyramid (see Figure 1) [ Fowler12 ] was created to give a visual hint about the relative number of ‘thick’ end-to-end tests and ‘thin’ unit tests. In the middle are the component/integration tests that verify interactions within a subset of the entire system. (The ‘Exploratory and Manual’ cloud at the top is a reminder that not all tests can be automated, and that the amount of effort needed here is very system dependent.)
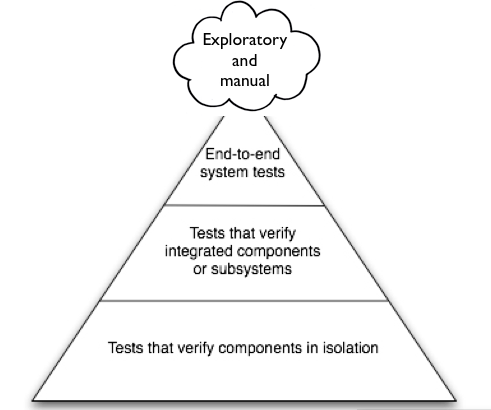
|
| Figure 1 |
It may be reasonable to use the example scenario above as a ‘Happy Path’ end-to-end test, demonstrating that the whole application is hanging together. However, there are some other situations that emerged when this feature was discussed, some of which were:
- what happens if the user already exists?
- what happens if the credentials provided are unacceptable?
- how will errors be communicated to the user?
These questions are still independent of how the system is actually going to be implemented, but we can start fleshing out some examples:
Scenario: Duplicate user registration
Given I already have an account
When I sign up for a new account
Then I should see the “User already exists” error message
Scenario: Unacceptable credentials at signup
Given my credentials are unacceptable
When I sign up for a new account
Then I should see the “Unacceptable credentials” error message
These extra examples could be implemented using the whole application stack, but then the runtime of the example suite begins to rise as we execute more end-to-end tests. Instead, we could decompose these examples into:
- examples that demonstrate the correct feedback is given to the user in various circumstances
- examples that exercise the validation components
Scenario Outline: Display correct error message
When the registration component returns an <error>
Then the correct <message> should be returned
Examples:
| | error | | message | | |
| | error-code-user-already-exists | | "User already exists" | | |
| | error-code-unacceptable-credentials | | "Unacceptable credentials" | | |
Scenario: Detect duplicate user
Given user already exists
When the registration component tries to create the user
Then it will return error-code-user-already-exists
Scenario: Unacceptable credentials at signup
Given the credentials are unacceptable
When the registration component tries to create the user
Then it will return error-code-unacceptable-credentials
Speed, completeness and comprehensibility
These examples should run a lot faster, but are no longer written in business language (if you want an explanation of Scenario Outline look at the Cucumber documentation). They have lost some of their benefit and have become technical tests, mainly of interest to the development team. If we choose to ‘push them down’ into the unit test suite, where they seem to belong, then we will have lost some important documentation that is important to the business stakeholders.
This demonstrates the conflict between keeping the examples in a form that is consumable by non-technical team members and managing the runtime of the executable examples. Teams that have ignored this issue and allowed their example suite to grow have seen runtimes that are counted in hours rather than minutes. Clearly this limits how quickly feedback can be obtained, and has led teams to try different solution approaches, none of which are ideal:
- partition the example suite and only run small subsets regularly
- speed up execution through improved hardware or parallel execution
- push some tests into the technical (unit test) suite
In a recent blog post I introduced the Testing Iceberg (see Figure 2) [ Rose ], which takes the traditional Testing Pyramid and introduces a readability waterline. This graphically shows that some technical tests can be made visible to the business, while there are some end-to-end tests that the business are not interested in. We want to implement our business examples in such a way that they:
- document everything relevant to the business
- do not duplicate technical tests
- minimise the execution time of the examples
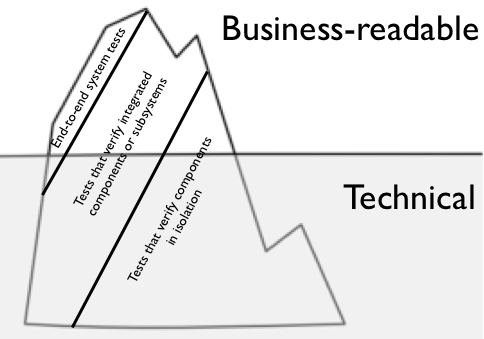
|
| Figure 2 |
Using Cucumber
There are a few features of Cucumber that I need to introduce before describing the technique I use to keep my examples consumable by the business without sacrificing performance of the suite.
Tags
Any Cucumber scenario can have one or more free text tags applied to it:
@this_is_a_tag
@a_different_tag
@regression
Scenario: What just happened?
When I do something
Then something should happen
When invoking Cucumber you can pass in tags as arguments to identify which scenarios should be executed. This is useful when trying to partition the example suite, to build a regression suite or a smoke test suite, for example.
Hooks
Cucumber also allows you to provide setup/teardown hooks in your glue code that are run before and after each example.
@Before
public void beforeScenario() {
// Do some setup work
}
Tagged hooks
And finally, Cucumber allows you to write tagged hooks, which are only run before scenarios that have matching tags (matching can use complex logic – see the documentation).
@Before("@regression")
public void beforeScenario() {
// Do something specific to the "regression" tag.
}
Putting it all together
#sign_up.feature
@without_ui
Scenario: Duplicate user registration
Given I already have an account
When I sign up for a new account
Then I should see the "User already exists" error message
// RegistrationSteps.java
class RegistrationSteps {
private boolean without_ui = false;
@Before("@without_ui")
public void beforeScenario() {
without_ui = true;
}
@When("I sign up for a new account")
public void I_sign_up_for_new_account() {
if (without_ui){
// Send information directly to
// registration component
} else {
// Drive UI directly using Selenium [Selenium]
// or similar.
}
}
}
The benefits of working like this are:
- we can write our examples from a user perspective (which makes it easy for the business to understand)
- we can execute the examples as thinner component or unit style tests (which keeps the runtime down)
- we can avoid duplication by using the glue to delegate directly to the unit tests where appropriate
- we can run the examples using the whole application stack and begin to thin down the stack using tags once we have built some trust in our initial implementation.
It is the business who should prioritise how to evolve a product, based on their understanding of the customers needs. Face to face communication between the business and the development team can help develop a ubiquitous language that can be used to document the behaviour of the system in a manner that is clear and unambiguous to all concerned. The examples that are produced during these conversations can then be automated, but there is an ongoing tension between the comprehensibility of end-to-end scenarios and the quick feedback of unit tests. Using Cucumber and tags it is possible to write the examples in an end-to-end style, but modify how they are executed (and hence their runtime costs) by applying or removing tags, without adversely affecting the comprehensibility of the example itself.
References
[Adzic11] http://specificationbyexample.com/key_ideas.html
[Agile] http://agilemanifesto.org
[Cucumber] http://cukes.info
[Fowler] http://martinfowler.com/bliki/UbiquitousLanguage.html
[Fowler12] http://martinfowler.com/bliki/TestPyramid.html
[Hellesøy12] http://aslakhellesoy.com/post/20006051268/cucumber-jvm-1-0-0
[Hendrickson] http://testobsessed.com/2008/12/acceptance-test-driven-development-atdd-an-overview/
[Keogh12] http://lizkeogh.com/2012/06/01/bdd-in-the-large/
[North] http://dannorth.net/introducing-bdd/
[Rose] http://claysnow.co.uk/?p=175315341
[Selenium] http://docs.seleniumhq.org
