








Programming parallel algorithms correctly is hard. Jason McGuiness and Colin Egan demonstrate how a C++ DESEL can make it simpler.
Computers with multiple pipelines have become increasingly prevalent, hence a rise in the available parallelism to the programming community. For example the dual-core desktop workstations to multiple core, multiple processors within blade frames which may contain hundreds of pipelines in data centres, to state-of-the-art mainframes in the Top500 supercomputer list with thousands of cores and the potential arrival of next-generation cellular architectures that may have millions of cores. This surfeit of hardware parallelism has apparently yet to be tamed in the software architecture arena. Various attempts to meet this challenge have been made over the decades, taking such approaches as languages, compilers or libraries to enable programmers to enhance the parallelism within their various problem domains. Yet the common folklore in computer science has still been that it is hard to program parallel algorithms correctly.
This paper examines what language features would be required to add to an existing imperative language that would have little if no native support for implementing parallelism apart from a simple library that exposes the OS-level threading primitives. The goal of the authors has been to create a minimal and orthogonal DSEL that would add the capabilities of parallelism to that target language. Moreover the DSEL proposed will be demonstrated to have such useful guarantees as a correct, heuristically efficient schedule. In terms of correctness the DSEL provides guarantees that it can provide deadlock-free and race-condition free schedules. In terms of efficiency, the schedule produced will be shown to add no worse than a poly-logarithmic order to the algorithmic run-time of the schedule of the program on a CREW-PRAM ( Concurrent-Read , Exclusive-Write , Parallel Random-Access Machine [ Tvrkik99 ]) or EREW-PRAM ( Exclusive-Read EW-PRAM [ Tvrkik99 ]) computation model. Furthermore the DSEL described assists the user with regard to debugging the resultant parallel program. An implementation of the DSEL in C++ exists: further details may be found in [ McGuiness09 ].
Related work
From a hardware perspective, the evolution of computer architectures has been heavily influenced by the von Neumann model. This has meant that with the relative increase in processor speed vs. memory speed, the introduction of memory hierarchies [ Burger96 ] and out-of-order instruction scheduling has been highly successful. However, these extra levels increase the penalty associated with a miss in the memory subsystem, due to memory access times, limiting the ILP (Instruction-Level Parallelism). Also there may be an increase in design complexity and power consumption of the overall system. An approach to avoid this problem may be to fetch sets of instructions from different memory banks, i.e. introduce threads, which would allow an increase in ILP, in proportion to the number of executing threads.
From a software perspective, the challenge that has been presented to programmers by these parallel architectures has been the massive parallelism they expose. There has been much work done in the field of parallelizing software:
- Auto-parallelizing compilers: such as EARTH-C [ Tang99 ]. Much of the work developing auto-parallelizing compilers has derived from the data-flow community [ Snelling94 ].
- Language support: such as Erlang [ Virding96 ], UPC [ El-ghazawi03 ] or Intel’s [ Tian03 ] and Microsoft’s C++ compilers based upon OpenMP.
- Library support: such as POSIX threads ( pthreads ) or Win32, MPI, OpenMP, Boost, Intel’s TBB [ Pheatt08 ], Cilk [ Leiserson10 ] or various libraries targeting C++ [ Giacaman08 , Bischof05 ]. Intel’s TBB has higher-level threading constructs, but it has not supplied parallel algorithms, nor has it provided any guarantees regarding its library. It also suffers from mixing code relating to generating the parallel schedule and the business logic, which would also make testing more complex.
These have all had varying levels of success, as discussed in part in [ McGuiness06b ], with regards to addressing the issues of programming effectively for such parallel architectures.
Motivation
The basic issues addressed by all of these approaches have been: correctness or optimization. So far it has appeared that the compiler and language based approaches have been the only approaches able to address both of those issues together. But the language-based approaches require that programmers would need to re-implement their programs in a potentially novel language, a change that has been very hard for business to adopt, severely limiting the use of these approaches.
Amongst the criticisms raised regarding the use of libraries [ McGuiness06b , McGuiness06a ] such as pthreads, Win32 or OpenMP have been:
- They have been too low-level so using them to write correct multi-threaded programs has been very hard; it suffers from composition problems. This problem may be summarized as: atomic access to an object would be contained within each object (using classic OOD), thus when composing multiple objects, multiple separate locks, from the different objects, have to be manipulated to guarantee correct access. If this were done correctly the usual outcome has been a serious reduction in scalability.
- A related issue has been that that the programmer often intimately entangles their thread-safety, thread scheduling and the business logic of their code. This means that each program would be effectively a bespoke program, requiring re-testing of each program for threading issues as well as business logic issues.
- Also debugging such code has been found to be very hard. Debuggers for multi-threaded code have been an open area of research for some time.
Given that the language has to be immutable, a DSEL defined by a library that attempts to support the correctness and optimality of the language and compiler approaches and yet somehow overcomes the limitations of the usual library-based approaches would seem to be ideal. This DSEL will now be presented.
The DSEL to assist parallelism
We chose to address these issues by defining a carefully crafted DSEL, then examining its properties to demonstrate that the DSEL achieved the goals. The DSEL should have the following properties:
- The DSEL shall target what may be termed as general purpose threading , the authors define this to be scheduling in which the conditions or loop-bounds may not be computed at compile-time, nor could they be represented as monads, so could not be memoized 1 . In particular the DSEL shall support both data-flow and data parallel constructs.
- By being implemented in an existing language it would avoid the necessity of re-implementing the programs, a more progressive approach to adoption could be taken.
- It shall be a reasonably small DSEL, but be large enough to provide sufficient extensions to the host language that express parallel constructs in a manner that would be natural to a programmer using that language.
- It shall assist in debugging any use of a conforming implementation.
- It should provide guarantees regarding those banes of parallel programming: dead-locks and race-conditions.
- Moreover it should provide guarantees regarding the algorithmic complexity of any parallel schedule it would generate.
Initially a description of the grammar will be given, followed by a discussion of some of the properties of the DSEL. Finally some theoretical results derived from the grammar of the DSEL will be given.
Detailed grammar of the DSEL
The various types, production rules and operations that define the DSEL will be given in this section. The basic types will be defined first, then the operations upon those types will be defined. C++ has been chosen as the target language in which to implement the DSEL. This was due to the rich ability within C++ to extend the type system at compile-time: primarily using templates but also overloading various operators. Hence the presentation of the grammar relies on the grammar of C++, so it would assist the reader to have familiarity of that grammar, in particular Annex A of the ISO C++ Standard [ ISO12 ]. Although C++11 has some support for threading, this had not been widely implemented at the time of writing, moreover the specification had not addressed the points of the DSEL in this paper.
Some clarifications:
- The subscript opt means that the keyword is optional.
- The subscript def means that the keyword is default and specifies the default value for the optional keyword.
Types
The primary types used within the DSEL are derived from the thread-pool type.
-
Thread pools can be composed with various subtypes that could be used to fundamentally affect the implementation and performance of any client software:
thread-pool-type:
thread_poolwork-policy size-policy pool-adaptor- A thread pool would contain a collection of threads that may be more, less or the same as the number of processors on the target architecture. This allows for implementations to visualize the multiple cores available or make use of operating-system provided thread implementations. An implementation may choose to enforce a synchronization of all threads within the pool once an instance of that pool should be destroyed, to ensure that threads managed by the pool are appropriately destroyed and work in the process of mutation could be appropriately terminated.
work-policy: one of
worker_threads_get_work one_thread_distributes-
The library should implement the classic work-stealing or master-slave work sharing algorithms. Clearly the specific implementation of these could affect the internal queue containing unprocessed work within the
thread_pool. For example aworker_threads_get_workqueue might be implemented such that the addition of work would be independent to the removal of work.
size-policy: one of
fixed_size tracks_to_max infinite- The size-policy when used in combination with the threading-model could be used to make considerable simplifications in the implementation of the thread-pool-type which could make it faster on certain architectures.
-
tracks_to_maxwould implement some model of the cost of re-creating and maintaining threads. If thread were cheap to create & destroy with little overhead, then aninfinitesize might be a reasonable approximation, conversely threads with opposite characteristics might be better maintained in afixed_sizepool.
pool-adaptor:
joinability api-type threading-model priority-mode opt comparator opt GSS(k)-batch-size opt
joinability: one of
joinable nonjoinable-
The
joinability
has been provided to allow for certain optimizations to be implementable. A
thread-pool-type
that is
nonjoinablecould have a number of simplifying details that would make it not only easier to implement but also faster in operation.
api-type: one of
no_api MS_Win32 posix_pthreads IBM_cyclops-
Both
MS_Win32andposix_pthreadsare examples ofheavyweight_threadingAPIs in which threading at the OS-level would be made use of to implement the DSEL.IBM_cyclopswould be an implementation of the DSEL using the lightweight_threading API implemented by IBM BlueGene/C Cyclops [ Almasi03 ].
threading-model: one of
sequential_mode heavyweight_threading lightweight_threading-
This specifier provides a coarse representation of the various implementations of threadable construct in the multitude of architectures available. For example Pthreads would be considered to be
heavyweight_threadingwhereas Cyclops would belightweight_threading. Separation of the threading model versus the API allows for the possibility that there may be multiple threading APIs on the same platform, which may have different properties, for example if there were to be a GPU available in a multi-core computer, there could be two different threading models within the same program. -
The
sequential_modehas been provided to allow implementations to removal all threading aspects of all of the implementing library, which would hugely reduce the burden on the programmer regarding identifying bugs within their code. If all threading is removed, then all bugs that remain, in principle should reside in their user-code, which once determined to be bug-free, could then be trivially parallelized by modifying this single specifier and re-compiling. Then any further bugs introduced would be due to bugs within the parallel aspects of their code, or the library implementing this DSEL. If the user relies upon the library to provide threading, then there should be no further bugs in their code. We consider this feature of paramount importance, as it directly addresses the complex task of debugging parallel software, by separating the algorithm by which the parallelism should be implemented from the code implementing the mutations on the data.
priority-mode: one of
normal_fifodefprioritized_queue-
This is an optional parameter. The
prioritized_queuewould allow the user to specify whether specific instances of work to be mutated should be performed ahead of other instances of work, according to a user-specified comparator .
comparator:
std::lessdef-
A unary function-type that specifies a strict weak-ordering on the elements within a the
prioritized_queue.
>GSS(k)-batch-size:
1def- A natural number specifying the batch-size to be used within the queue specified by the priority-mode . The default is 1, i.e. no batching would be performed. An implementation would be likely to use this for enabling GSS(k) scheduling [ Kennedy02 ].
-
Adapted collections to assist in providing thread-safety and also specify the memory access model of the collection:
safe-colln:
safe_collncollection-type lock-type- This adaptor wraps the collection-type and an instance of lock-type in one object, and provides a few thread-safe operations upon that collection, plus access to the underlying collection. This access might seem surprising, but this has been done because locking the operations on collections has been shown to not be composable, and cross-cuts both object-orientated and functional-decomposition designs. This could could be open to misuse, but otherwise excessive locking would have to be done in user code. This has not been an ideal design decision, but a simple one, with scope for future work. Note that this design choice within the DSEL does not invalidate the rest of the grammar, as this would just affect the overloads to the data-parallel-algorithms , described later.
- The adaptor also provides access to both read-lock and write-lock types, which may be the same, but allow the user to specify the intent of their operations more clearly.
lock-type: one of
critical_section_lock_type read_write read_decaying_write-
A
critical_section_lock_typewould be a single-reader, single-writer lock, a simulation of EREW semantics. The implementation of this type of lock could be more efficient on certain architectures. -
A
read_writelock is a multi-readers, single-write lock, a simulation of CREW semantics. -
A
read_decaying_writelock would be a specialization of aread_writelock that also implements atomic transformation of a write-lock into a read-lock. - The lock should be used to govern the operations on the collection, and not operations on the items contained within the collection.
-
The
lock-type
parameter may be used to specify if EREW or CREW operations upon the collection are allowed. For example if EREW operations are only allowed, then overlapped dereferences of the
execution_contextresultant from parallel-algorithms operating upon the same instance of a safe-colln should be strictly ordered by an implementation to ensure EREW semantics are maintained. Alternatively if CREW semantics were specified then an implementation may allow read-operations upon the same instance of the safe-colln to occur in parallel, assuming they were not blocked by a write operation.
collection-type:
A standard collection such as an STL-style list or vector, etc. -
The
thread-pool-type
defines further sub-types for convenience to the programmer:
create_direct:This adaptor, parametrized by the type of work to be mutated, contains certain sub-types. The input data and the mutation operation combined are termed the work to be mutated , which would be a type of closure. If the mutation operation does not change the state of any data external to the closure, then this would be a type of monad. More specifically, this work to be mutated should also be a type of functor that either:
-
Provides a type
result_typeto access the result of the mutation, and specifies the mutation member-function, -
or implements the function
process(result_type &), and the library may determine the actual type ofresult_type.
The sub-types are:
joinable: A method of transferring work to be mutated into an instance of thread-pool-types . If the work to be mutated were to be transferred using this modifier, then the return result of the transfer would be anexecution_context, that may subsequently be used to obtain the result of the mutation. Note that this implies that the DSEL implements a form of data-flow operation.execution_context: This is the type of future that a transfer returns. It is also a type of proxy to theresult_typethat the mutation returns. Access via this proxy implicitly causes the calling thread to wait until the mutation has been completed. This is the other component of the DSEL that implements the data-flow model. Various sub-types ofexecution_contextexist specific to theresult_typesof the various operations that the DSEL supports. Note that the implementation ofexecution_contextshould specifically prohibit aliasing instances of these types, copying instances of these types and assigning instances of these types.nonjoinable: Another method of transferring work to be mutated into an instance of thread-pool-types . If the work to be mutated were to be transferred using this modifier, then the return result of the transfer would be nothing. The mutation within the pool would occur at some indeterminate time, the result of which would, for example, be detectable by any side effects of the mutation within theresult_typeof the work to be mutated.time_critical: This modifier ensures that when the work is mutated by a thread within an instance of thread-pool-type into which it has been transferred, it will be executed at an implementation-defined higher kernel priority. Other similar modifiers exist in the DSEL for other kernel priorities. This example demonstrates that specifying other modifiers, that would be extensions to the DSEL, would be possible.cliques(natural_number n): This modifier is used with data-parallel-algorithms . It causes the instance of thread-pool-type to allow the data-parallel-algorithm to operate with the number of threads shown, where p is the number of threads in the instance: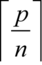
-
Provides a type
-
The DSEL specifies a number of other utility types such as
shared_pointer, various exception types and exception-management adaptors amongst others. The details of these important, but ancillary types has been omitted for brevity.
Operators on the thread-pool-type
The various operations that are defined in the DSEL will now be given. These operations tie together the types and express the restrictions upon the generation of the control-flow graph that the DSEL may create.
-
The transfer work to be mutated into an instance of
thread-pool-type
is defined as follows:
transfer-future :
execution-context-result opt
thread-pool-type transfer-operationexecution-context-result :
execution_context <<-
The token sequence
<<is the transfer operation, and also used in the definition of the transfer-modifier-operation , amongst other places. -
Note how an
execution_contextcan only be created via a transfer of work to be mutated into the suitably definedthread_pool. It is an error to transfer work into athread_poolthat has been defined using thenonjoinablesubtype. There is no way to create anexecution_contextwith transferring work to be mutated, so everyexecution_contextis guaranteed to eventually contain the result of a mutation.
transfer-operation:
transfer-modifier-operation opt transfer-data-operationtransfer-modifier-operation :
<< transfer-modifiertransfer-modifier: one of
time_critical joinable nonjoinable cliquestransfer-data-operation:
<< transfer-datatransfer-data: one of
work-to-be-mutated parallel-binary-operation data-parallel-algorithm -
The token sequence
The details of the various parallel-binary-operations and data-parallel-algorithms will be given in the next section.
The data-parallel operations and algorithms
This section will describe the various parallel algorithms defined within the DSEL.
-
The
parallel-binary-operations
are defined as follows:
parallel-binary-operation: one of
binary_funparallel-logical-operationparallel-logical-operation: one of
logical_and logical_or- It is likely that an implementation would not implement the usual short-circuiting of the operands, to allow them to transferred into the thread pool and executed in parallel.
-
The
data-parallel-algorithms
are defined as follows:
data-parallel-algorithm: one of
accumulate copy count count_if fill fill_n find find_if for_each min_element max_element reverse transform-
The style and arguments of the
data-parallel-algorithms
is similar to those of the STL in the C++ ISO Standard. Specifically they all take a
safe-collnas the arguments to specify the ranges and functors as necessary as specified within the STL. Note that these algorithms all use run-time computed bounds, otherwise it would be more optimal to use techniques similar to those used in HPF or described in [ Kennedy02 ] to parallelize such operations. If the DSEL supports loop-carried dependencies in the functor argument is undefined. -
If algorithms were to be implemented using techniques described in [
Gibbons88
] and [
Casanova08
], then the algorithms would be optimal with
O
(log(
p
)) complexity in distributing the work to the thread pool. Given that there are no loop-carried dependencies, each thread may operate independently upon a sub-range within the safe-colln for an optimal algorithmic complexity shown below where
n
is the number of items to be computed and
p
is the number of threads, ignoring the operation time of the mutations.
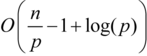
-
The style and arguments of the
data-parallel-algorithms
is similar to those of the STL in the C++ ISO Standard. Specifically they all take a
-
The
binary_funsare defined as follows:binary_fun:
work-to-be-mutated work-to-be-mutated binary_functor- A binary_functor is just a functor that takes two arguments. The order of evaluation of the arguments is undefined. If the DSEL supports dependencies between the arguments is undefined. This would imply that the arguments should refrain from modifying any external state.
-
Similarly, the
logical_operations
are defined as follows:
logical_operation:
work-to-be-mutated work-to-be-mutated binary_functor- Note that no short-circuiting of the computation of the arguments occurs. The result of mutating the arguments must be boolean. If the DSEL supports dependencies between the arguments is undefined. This would imply that the arguments should refrain from modifying any external state.
Properties of the DSEL
In this section some results will be presented that derive from the definitions, the first of which will demonstrate that the CFG ( Control Flow Graph ) would be a tree from which the other useful results will directly derive.
Theorem 1
Using the DSEL described above, the parallel control-flow graph of any program that may use a conforming implementation of the DSEL must be an acyclic directed graph, and comprised of at least one singly-rooted tree, but may contain multiple singly-rooted, independent, trees.
Proof:
From the definitions of the DSEL, the transfer of
work to be mutated
into the
thread_pool
may be done only once according to the definition of
transfer-future
the result of which returns a single
execution_context
according to the definition of
execution-context-result
which has been the only defined way to create
execution_context
s. This implies that from a node in the CFG, each transfer to the
thread-pool-type
represents a single forward-edge connecting the
execution_context
with the child-node that contains the mutation. The back-edge from the mutation to the parent-node is the edge connecting the result of the mutation with the dereference of the
execution_context
. The
execution_context
and the dereference occur in the same node, because
execution_contexts
cannot be passed between nodes, by definition. In summary: the parent-node has an edge from the
execution_context
it contains to the mutation and a back-edge to the dereference in that parent-node. Each node may perform none, one or more transfers resulting in none, one or more child-nodes. A node with no children is a leaf-node, containing only a mutation. Now back-edges to multiple parent nodes cannot be created, according to the definition of
execution_context
, because
execution_context
s cannot be aliased nor copied between nodes. So the only edges in this sub-graph are the forward and back edges from parent to children. Therefore the sub-graph is not only acyclic, but a tree. Due to the definitions of
transfer-future
and
execution-context-result
, the only way to generate mutations is via the above technique. Therefore each child-node either returns via the back edge immediately or generates a further sub-tree attaching to the larger tree that contains it’s parent. Now if the entry-point of the program is the single thread that runs
main()
, i.e. the single root, this can only generate a tree, and each node in the tree can only return or generate a tree, the whole CFG must be a tree. If there were more entry-points, each one can only generate a tree per entry-point, as the
execution_context
s cannot be aliased nor copied between nodes, by definition.
According to the above theorem, one may appreciate that a conforming implementation of the DSEL would implement data-flow in software.
Theorem 2
If the user refrains from using any other threading-related items or atomic objects other than those defined in the DSEL above then they can be guaranteed to have a schedule free of race-conditions.
Proof:
A race-condition is when two threads attempt to access the same data at the same time. A race-condition in the CFG would be represented by a child node with two parent nodes, with forward-edges connecting the parents to the child. Note that the CFG must an acyclic tree according to theorem 1, then this sub-graph cannot be represented in a tree, so the schedule must be race-condition free.
Theorem 3
If the user refrains from using any other threading-related items or atomic objects other than those defined in the DSEL above and that the work they wish to mutate may not be aliased by any other object, then the user can be guaranteed to have a schedule free of deadlocks.
Proof:
A deadlock may be defined as: when threads A and B wait on atomic-objects C and D, such that A locks C, waits upon D to unlock C and B locks D, waits upon C to unlock D. In terms of the DSEL, this implies that
execution_contexts
C and D are shared between two threads. i.e. that an
execution_context
has been passed from a node A to a sibling node B, and vice-versa occurs to
execution_context
B. But aliasing
execution_context
s has been explicitly forbidden in the DSEL by definition 3.
Corollary 1:
If the user refrains from using any other threading-related items or atomic objects other than those defined in the DSEL above and that the work they wish to mutate may not be aliased by any other object, then the user can be guaranteed to have a schedule free of race-conditions and deadlocks.
Proof:
It must be proven that the two theorems 2 and 3 are not mutually exclusive. Let us suppose that a CFG exists that satisfies 2 but not 3. Therefore there must be either an edge formed by aliasing an
execution_context
or a back-edge from the result of a mutation back to a dereference of an
execution_context
. The former has been explicitly forbidden in the DSEL by definition of the
execution_context
, 3, the latter forbidden by the definition of
transfer-future
, 1. Both are a contradiction, therefore such a CFG cannot exist. Therefore any conforming CFG must satisfy both theorems 2 and 3.
Theorem 4
If the user refrains from using any other threading-related items or atomic objects other than those defined in the DSEL above then the schedule of work to be mutated by a conforming implementation of the DSEL would be executed in time taking at least an algorithmic complexity of O(log(p)) and at most O ( n ) in units of time to mutate the work where n is the number of work items to be mutated on p processors. The algorithmic order of the minimal time would be poly-logarithmic, so within NC, therefore at least optimal.
Proof:
Given that the schedule must be a tree according to theorem 1 with at most n leaf-nodes, and that each node takes at most the number of computations shown below according to the definition of the parallel-algorithms .
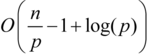
Also it has been proven in [ Gibbons88 ] that to distribute n items of work onto p processors may be performed with an algorithmic complexity of O (log( n )). The fastest computation time would be if the schedule were a balanced tree, where the computation time would be the depth of the tree, i.e. O (log( n )) in the same units. If the n items of work were to be greater than the p processors, then O (log( p )) ≤ O (log( n )), so the computation time would be slower than O (log( p )). The slowest computation time would be if the tree were a chain, i.e. O ( n ) time. In those cases this implies that a conforming implementation should add at most a constant order to the execution time of the schedule.
Some example usage
These are two toy examples, based upon an implementation in [
McGuiness09
], of how the above DSEL might appear. Listing 1 is a data-flow example showing how the DSEL could be used to mutate some work on a thread within the thread pool, effectively demonstrating how the future would be waited upon. Note how the
execution_context
has been created via the transfer of work into the
thread_pool
.
struct res_t {
int i;
};
struct work_type {
void process(res_t &) {}
};
typedef ppd::thread_pool<
pool_traits::worker_threads_get_work,
pool_traits::fixed_size,
pool_adaptor<
generic_traits::joinable,platform_api,
heavyweight_threading
>
> pool_type;
typedef pool_type::create_direct creator_t;
typedef creator_t::execution_context execution_context;
typedef creator_t::joinable joinable;
pool_type pool(2);
execution_context context
(pool<<joinable()<<work_type());
context ->i;
|
| Listing 1 |
The
typedef
s in this example implementation of the grammar are complex, but the
typedef
for the
thread-pool-type
would only be needed once and, reasonably, could be held in a configuration trait in header file.
Listing 2 shows how a data-parallel version of the C++
accumulate
algorithm might appear.
typedef ppd::thread_pool<
pool_traits::worker_threads_get_work,
pool_traits::fixed_size,
pool_adaptor<
generic_traits::joinable,platform_api,
heavyweight_threading,
pool_traits::normal_fifo,std::less,1
>
> pool_type;
typedef ppd::safe_colln<
vector,<int >,
lock_traits::critical_section_lock_type
> vtr_colln_t;
typedef pool_type::accumulate_t<
vtr_colln_t
>::execution_context execution_context;
vtr_colln_t v;
v.push_back(1); v.push_back(2);
execution_context context(
pool<<joinable()
<<pool.accumulate(
v,1,std::plus<vtr_coln_t::value_type>()
)
);
assert(*context==4);
|
| Listing 2 |
All of the parameters have been specified in the
thread-pool-type
to demonstrate the appearance of the
typedef
. Note that the example illustrates a map-reduce operation, an implementation might:
- take sub-ranges within the safe-colln ,
-
which would be distributed across the threads within the
thread_pool, - the mutations upon each element within each sub-range would be performed sequentially, their results combined via the accumulator functor, without locking any other thread’s operation,
- These sub-results would be combined with the final accumulation, in this the implementation providing suitable locking to avoid any race-condition,
-
The total result would be made available via the
execution_context.
Moreover the size of the input collection should be sufficiently large or the time taken to execute the operation of the accumulator so long, so that the cost of the above operations would be reasonably amortized.
Conclusions
The goals of the paper has been achieved: a DSEL has been formulated:
- that may be used to expresses general-purpose parallelism within a language,
- ensures that there are no deadlocks and race conditions within the program if the programmer restricts themselves to using the constructs of the DSEL,
- and does not preclude implementing optimal schedules on a CREW-PRAM or EREW-PRAM computation model.
Intuition suggests that this result should have come as no surprise considering the work done relating to auto-parallelizing compilers, which work within the AST and CFGs of the parsed program [ Tang99 ].
It is interesting to note that the results presented here would be applicable to all programming languages, compiled or interpreted, and that one need not be forced to re-implement a compiler. Moreover the DSEL has been designed to directly address the issue of debugging any such parallel program, directly addressing this problematic issue. Further advantages of this DSEL are that programmers would not need to learn an entirely new programming language, nor would they have to change to a novel compiler implementing the target language, which may not be available, or if it were might be impossible to use for more prosaic business reasons.
Future work
There are a number of avenues that arise which could be investigated, for example a conforming implementation of the DSEL could be presented, for example [ McGuiness09 ]. The properties of such an implementation could then be investigated by reimplementing a benchmark suite, such as SPEC2006 [ Reilly06 ], and comparing and contrasting the performance of that implementation versus the literature. The definition of safe-colln has not been an optimal design decision a better approach would have been to define ranges that support locking upon the underlying collection. Extending the DSEL may be required to admit memoization could be investigated, such that a conforming implementation might implement not only inter but intra-procedural analysis.
References
[Almasi03] George Almasi, Calin Cascaval, Jose G. Castanos, Monty Denneau, Derek Lieber, Jose E. Moreira, Jr. Henry S. Warren: ‘Dissecting Cyclops: a detailed analysis of a multithreaded architecture’, SIGARCH Comput. Archit. News , pp. 26–38, 2003.
[Bischof05] Holger Bischof, Sergei Gorlatch, Roman Leshchinskiy, Jens Müller: ‘Data Parallelism in C++ Template Programs: a Barnes-hut Case Study’, Parallel Processing Letters , pp. 257–272, 2005.
[Burger96] Doug Burger, James R. Goodman, Alain Kagi: ‘Memory Bandwidth Limitations of Future Microprocessors’. In ICSA (1996) pp. 78–89, http://citeseer.ist.psu.edu/burger96memory.html
[Casanova08] H. Casanova, A. Legrand, Y. Robert: Parallel Algorithms . Chapman & Hall/CRC Press, 2008.
[El-ghazawi03] Tarek A. El-ghazawi, William W. Carlson, Jesse M. Draper: ‘UPC language specifications v1.1.1’, 2003.
[Giacaman08] Nasser Giacaman, Oliver Sinnen: ‘Parallel iterator for parallelising object oriented applications’. In SEPADS’08: Proceedings of the 7th WSEAS International Conference on Software Engineering, Parallel and Distributed Systems , pp. 44–49, 2008.
[Gibbons88] Alan Gibbons, Wojciech Rytter: Efficient parallel algorithms . Cambridge University Press, 1988.
[ISO12] ISO: ISO/IEC 14882:2011 Information technology – Programming languages – C++ . International Organization for Standardization, 2012. http://www.iso.org/iso/iso_catalogue/catalogue_tc/catalogue_detail.htm?csnumber=50372
[Kennedy02] Ken Kennedy, John R. Allen: Optimizing compilers for modern architectures: a dependence-based approach . Morgan Kaufmann Publishers Inc., 2002.
[Leiserson10] Charles E. Leiserson: ‘The Cilk++ concurrency platform’, J. Supercomput. , pp. 244–257, 2010. http://dx.doi.org/10.1007/s11227-010-0405-3 .
[McGuiness06a] Jason M. McGuiness, Colin Egan, Bruce Christianson, Guang Gao: ‘The Challenges of Efficient Code-Generation for Massively Parallel Architectures’. In Asia-Pacific Computer Systems Architecture Conference (2006), pp. 416–422.
[McGuiness06b] Jason M. McGuiness: ‘Automatic Code-Generation Techniques for Micro-Threaded RISC Architectures’, Masters’ thesis, University of Herfordshire. 2006.
[McGuiness09] Jason M. McGuiness: ‘libjmmcg – implementing PPD’. 2009. http://libjmmcg.sourceforge.net
[Pheatt08] Chuck Pheatt: ‘Intel® threading building blocks’, J. Comput. Small Coll. 23 , 4 pp. 298–298, 2008.
[Reilly06] Jeff Reilly: ‘Evolve or Die: Making SPEC’s CPU Suite Relevant Today and Tomorrow’. In IISWC , pp. 119, 2006.
[Snelling94] David F. Snelling, Gregory K. Egan: ‘A Comparative Study of Data-Flow Architectures’, 1994. http://citeseer.ist.psu.edu/snelling94comparative.html
[Tang99] X. Tang: Compiling for Multithreaded Architectures . PhD thesis, 1999. http://citeseer.ist.psu.edu/tang99compiling.html .
[Tian03] Xinmin Tian, Yen-Kuang Chen, Milind Girkar, Steven Ge, Rainer Lienhart, Sanjiv Shah: ‘Exploring the Use of Hyper-Threading Technology for Multimedia Applications with Intel® OpenMP* Compiler’. In IPDPS , p. 36, 2003.
[Tvrkik99] Pavel Tvrdik: ‘Topics in parallel computing – PRAM models’. 1999. http://pages.cs.wisc.edu/~tvrdik/2/html/Section2.html
[Virding96] Robert Virding, Claes Wikström, Mike Williams: Concurrent programming in ERLANG (2nd ed.) (Armstrong, Joe, ed.). Prentice Hall International (UK) Ltd., 1996.
