








Using data mining techniques to write an editorial.
In Overload 108, Ric Parkin said goodbye as Overload editor after a four year stint. Allow me to introduce myself. I’m Fran Buontempo and I am your new editor. Choosing a suitable topic for editorials is difficult, yet it seems suitable to use this as an opportunity to reminisce about issues gone by, as we say goodbye to our old editor, while obviously looking forward to many articles from him in the future. Many months ago, in January in fact, Nigel Lister posted a word cloud of this year’s conference on accu-general [ Lister12 ]. This is a beautiful way of representing the frequency of words contained in documents. A more traditional approach would present a histogram, with bars showing how many times an item appears. Wikipedia [ Histogram ] suggests these were invented by Karl Pearson, though I like to think the ideas trace back to Florence Nightingale’s innovations in statistical graphics, such as the rose diagrams [ Nightingale ]. I therefore produced a word cloud of Overload 108 [ Overload ], and was pleased to see the words ‘Surreal’ ‘Mutation’ standing out proudly.
Word clouds are part of the growing ‘Big data’ trend, which seems to be one of the latest buzz-words [ Gigaom ]. Though big data involves the hardware to deal with vast quantities of bits and bytes, at its heart is the attempt to extract information from data, which can be used to make money through smart business decisions, to cure cancer or to categorise proteins or new galaxies. I regard big data as the trendy face of data mining and machine learning. These disciplines are related to statistics, though encompass a much broader scope of approaches including swarm-inspired algorithms such as ant-colony optimisations, other nature inspired approaches such as neural networks and genetic algorithms, as well as clustering and classification and many other ways of searching data for meaning, or at least patterns. On a smaller scale, data mining and machine learning can provide a way to reflect and reminisce on historical trends, for example, issues of a magazine. Communications, the ACM members magazine, recently ran an article using n-Grams to analyse its previous content [ ACM ]. The motivation of the article was to delve into the institution's identity, considering its worldwide readership, long history and churn of members, using previous publications as input. As an organisation, the ACCU seems to have been through a time of similar reflection, for example musing on the ‘Professionalism in Programming’ tag line on accu-general. The coincidence between the ACM musings and our search for identity, and amused by ‘surreal’ ‘mutations’ in the Overload 108 tag cloud, the most sensible option for my first editorial had to be to get a computer to write it for me. I’m a geek, so what did you expect?
By saving all the words in Overload 103–108 inclusive in separate text files, and applying the Porter stemmer algorithm, [ Porter ], a tally chart of word frequencies for each edition can be produced. This algorithm trims or stems words such as ‘mutation’ and ‘mutated’ to ‘mutat’, so they are counted as the same word. When this is applied to several journals the information can be combined to graph the top n words for each issue, over time. Taking care to insert zeros for runs where words disappear off the radar, this can be used to look for trends. Using so few articles will almost certainly not reveal any long term trends, but will hopefully give a starting point for further investigation. Table 1 shows the frequencies of the top four stem words over the articles considered, and Figure 1 graphs this for us. Immediately ‘test’ jumps out as the highest scorer in two different issues, by a large margin. Perhaps this is a topic that captures our imagination at periodic intervals. Next, certain words seem to have a mini-trend for two or three articles running such as ‘function’, ‘code’, ‘list’ and ‘type’. The stemmer algorithm will chop short words, such as C++, C, Go, R, Q, so it might be interesting to adapt it to include language specific words that it would otherwise filter out, taking care to disambiguate ‘go’ and the language ‘Go’. Increasing the number of top words considered will clearly reveal further trends and mini-trends, but filling my editorial with computer generated graphs and tables might be considered cheating.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Table 1 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
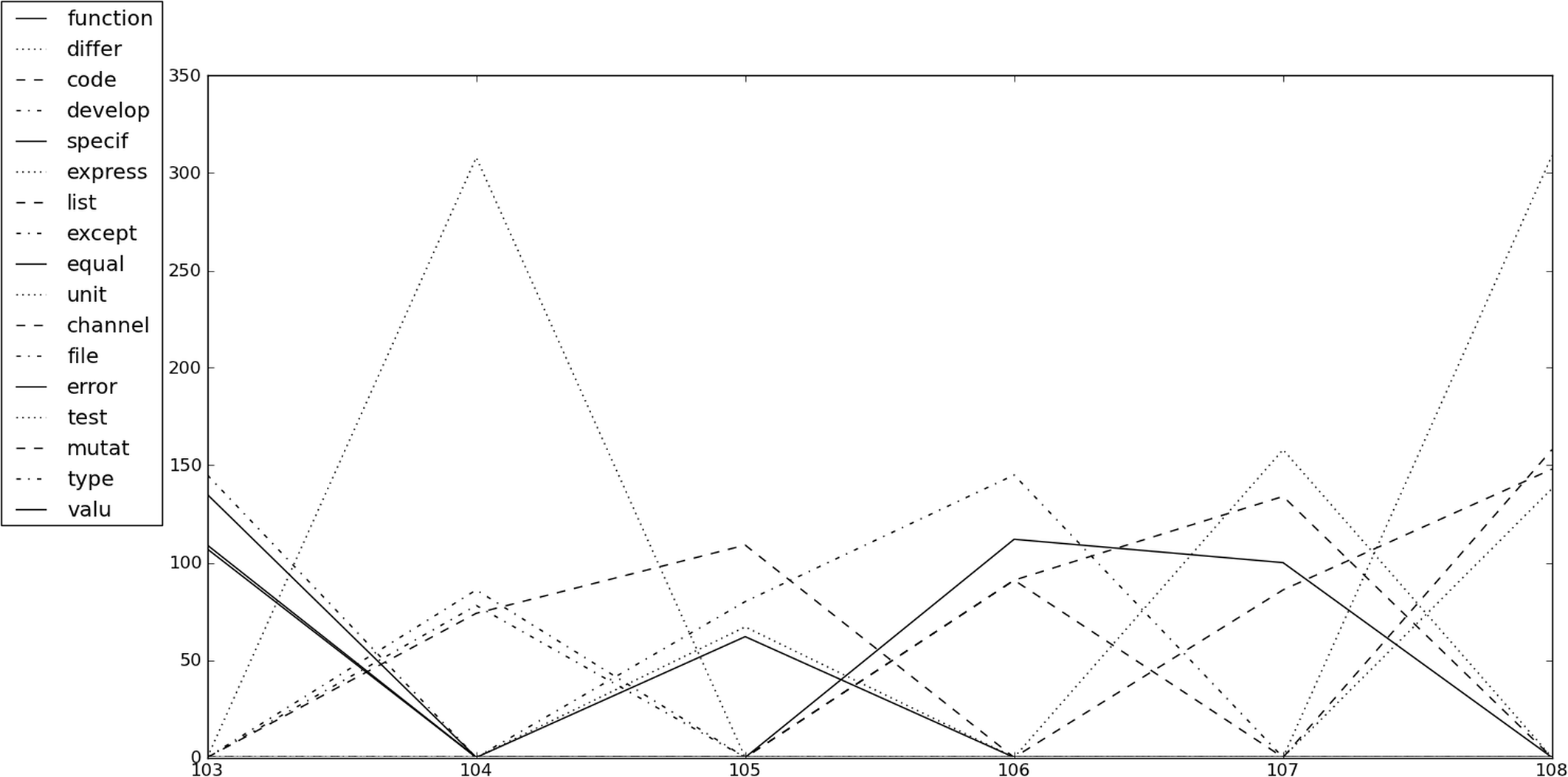
|
| Figure 1 |
I look forward to the future editions of Overload, and would like to thank Ric for all his hard work, including keeping an eye on my first issue as editor. Thanks also to the Overload review team, and welcome to Chris Oldwood who has just come on board.
References
[ACM] Communications of the ACM, Vol 55, No 5, 2012
[Gigaom] http://gigaom.com/cloud/big-data-the-quick-and-the-dead/
[Histogram] http://en.wikipedia.org/wiki/Histogram
[Lister12] http://dl.dropbox.com/u/34106607/ACCU_SCHEDULE_smaller.png
[Nightingale] http://en.wikipedia.org/wiki/Florence_Nightingale
[Overload] http://www.wordle.net/show/wrdl/5128616/overload108

{kind=link}