








Many numberic estimation techniques are easily parallelisable. Steve Love employs multi-threading, message passing, and more in search of π.
You have to tell a complete story
and deliver a complete message
in a very encapsulated form.
It disciplines you to cut away extraneous information.
~ Dick Wolf, on Advertising
The Monte-Carlo simulation is a common occurrence in computing, used as a way of ‘guess-timating’ some outcome through repeated sampling. Very often, simulations are processor and memory intensive, performing millions of calculations. The idea is simple: do the same (possibly small) calculation lots of times, usually with random inputs (called sampling), and aggregate all the results in some way.
A larger simulation (more calculations) generally has more accurate results, and so being able to scale in terms of time and space is of great importance. As the uses of calculation services become more sophisticated and demand increasingly precise and timely results, the problem remains the same: how to provide more accuracy in less time. Which means making better use of available resources.
To illustrate the concept, this article takes the example of estimating using a simulation. Although it’s a simple enough calculation, it demonstrates some techniques to make a calculation ‘engine’ scale well with available resources, and examines some of the trade-offs which are inevitable.
Give me π
Estimating π using a simulation is a straightforward enough calculation. The principle is as follows:
The area of a circle inscribed within a square has a ratio of π/4 to the area of the square. If a number of items of equal size are dropped randomly within the square, then the ratio of the number of items within the circle to the total number of items is (approximately) π/4.
In a computer program, dropping items is a matter of getting a pair of random numbers to represent x and y coordinates within the square. For this example, pseudo-random numbers uniformly distributed over a given range is random enough. Assuming a unit-square, then two random numbers between 0.0 and 1.0 provide the necessary co-ordinates. This is the sampling of the data.
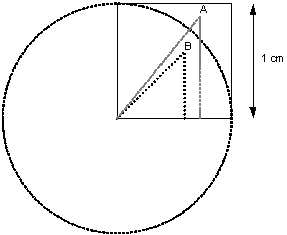
Determining if that co-ordinate is also inside the circle requires reference to Pythagoras:
The square of the length of the hypotenuse of a right-angled triangle is equal to the sum of the squares of the lengths of the other two sides.
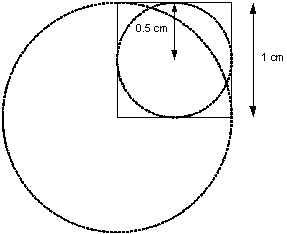
Or, perhaps more memorably, x 2 + y 2 = h 2 . Note that the area of quarter of a circle with radius 1.0 is the same as the area of a circle with radius 0.5 (see figure 1). It is a simple matter to calculate the length of the hypotenuse of the triangle formed by the point at the x , y co-ordinates, the projection of that point on to the x-axis and the origin of the square (the centre of the circle). See figure 2. If the length of the hypotenuse is greater than 1.0 (the radius of the circle), then the location is not within the circle.
|
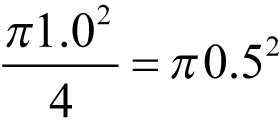
|
| Figure 1 |
|
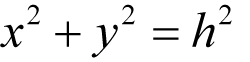
|
| Figure 2 |
Using many such random co-ordinates (samples), the ratio of those within the circle to the total number of samples should be approximately π/4.
Listing 1 shows C# code to sample the co-ordinates. Listing 2 shows the code to calculate the ratio of hits within the circle and multiply up by a factor of 4 to estimate. [ MonteCarlo ]
public static int Simulate( int count )
{
var hits = 0;
var rnd =
new Random( ( int )DateTime.Now.Ticks );
foreach( var i in Enumerable.Range( 0, count ) )
{
var xSq = Math.Pow( rnd.NextDouble(), 2 );
var ySq = Math.Pow( rnd.NextDouble(), 2 );
if( Math.Sqrt( xSq + ySq ) <= 1.0 )
++hits;
}
return hits;
}
|
| Listing 1 |
public static
double EstimatePi( int hits, int count )
{
return 4.0 * hits / count;
}
|
| Listing 2 |
Running the simulation code with a sufficiently large sample size should produce a reasonable estimate of π. The larger the sample size, the more accurate the result is likely to be.
Of course, the
Simulate
function could assume a simulation size of 1, and the calling code could just invoke it many times, but this turns out to be – unsurprisingly – colossally inefficient.
This isn’t really a Monte-Carlo simulation as such; the next stage is to perform many such simulations and aggregate the results.
Average π
As with most Monte-Carlo scenario calculations, we want to aggregate the results of many simulations by taking the mean average. Naively, the method for this is straightforward. If we have n results, then the mean is calculated by summing all the results and dividing by n .
As noted previously, however, the greatest benefit of performing a Monte-Carlo simulation is obtained by making n as large as possible, with the result that taking the mean that way can cause issues with such things as overflow, not to mention the overhead of having to store all of the results before the mean can be calculated.
Listing 3 shows how a running average can be taken at each step, effectively eliminating the problem.
public static double RunningAverage( int count,
double last, double next )
{
return last + ( next - last ) / ( count + 1 );
}
|
| Listing 3 |
It’s now practical to put these bits of code together and perform a Monte-Carlo simulation. Listing 4 demonstrates a single-threaded version, along with the results of four runs.
var simsize = 999999;
var count = 100;
var pi = 0.0;
foreach( var i in Enumerable.Range( 0, count ) )
{
var hits = Common.Simulate( simsize );
pi = Common.RunningAverage( i, pi,
Common.EstimatePi( hits, simsize ) );
}
Console.WriteLine( pi );
3.1414193014193
3.1415431015431
3.14159102159102
3.1414877014877
|
| Listing 4 |
In this example – and all the following examples – n is quite small, just 100, whilst the sample size is relatively large. The purpose of that will become apparent later, but for now it is merely enough to note that it’s sufficient to estimate π fairly well.
Shared π
In order to make better use of any multi-core or multi-processor resources, a multi-threaded version seems an obvious next step. Listing 5 shows one way that might be done.
var pi = 0.0;
var locked = new object();
Action action = delegate
{
foreach( var i in Enumerable.Range( 0,
count / 4 ) )
{
var hits = Common.Simulate( simsize );
lock( locked )
pi = Common.RunningAverage( i, pi,
Common.EstimatePi( hits,simsize ) );
}
};
var tasks = Enumerable.Range( 0, 4 )
.Select( id => Task.Factory.StartNew(action) )
.ToArray();
Task.WaitAll( tasks );
Console.WriteLine( pi );
|
| Listing 5 |
The work to be done is split between 4 threads, each doing one quarter of the necessary work, with the running average calculated by each thread.
Since the results are written to a shared resource (the variable
pi
), access to it must be synchronised safely, resulting in the need to lock. Additionally, the code must explicitly wait for all of the launched threads to complete before attempting to read the final value of the pi; not only would an early read be getting an incomplete value, it also introduces a race-condition.
Arguably, the simple
RunningAverage
function might be better encapsulated as a simple class, but this would add an extra point in the code where a lock would be required to protect concurrent access to it since it would need to maintain some internal state.
Nevertheless, this code is far from ideal, but it has a more subtle problem.
The running average calculation depends upon knowing how many results have been seen so far. Since each thread is operating on (conceptually) a quarter of the input range, the average will be skewed. In effect, the mean gets calculated for only a quarter of the simulations.
The promise of π
The standard solution to that particular problem is to ensure that the results are aggregated from all the threads when they’re done. One way to achieve that is to use a Promise.
This is a common mechanism by which a launched thread promises to provide a result, and calling code that attempts to access that result will block until the thread has finished. The version in Listing 6 has each thread calculating the running average for its portion of the input, and then returning that to the calling code, which then takes the average of each thread’s result.
var nthreads = 4;
Func< double > action = delegate
{
var part = 0.0;
foreach( var i in Enumerable.Range( 0,
count / nthreads ) )
{
var hits = Common.Simulate( simsize );
part = Common.RunningAverage( i, part,
Common.EstimatePi(hits, simsize) );
}
return part;
};
var results = Enumerable.Range( 0, nthreads )
.Select( id => Task< double >
.Factory.StartNew( action ) )
.ToArray();
var pi = results.Select(
t => t.Result ).Average();
Console.WriteLine( pi );
|
| Listing 6 |
The call to
t.Result
calls in the promise from each task; if a task has not completed, this call will block until it’s ready. Within the delegate that represents a task, it is the return expression that ‘fulfils’ the promise for each task.
Apart from the fact that the final calculation is now correct, this version has other benefits:
- there is no longer a shared resource, and thus no need to lock.
- waiting for the tasks’ results naturally blocks the caller, removing the need to explicitly join on each task.
It does, however, introduce a second calculation of average.
A better solution would be to have all the results collated at a single point in the code, and have each thread somehow present just the results of the simulation. In this version of the simulator, this could be achieved by each task ‘returning’ the number of hits, and the final calculation of π using the running average algorithm as previously shown.
However, there is still a drawback to this approach: the collation of the results (getting the final average) can’t begin until all the tasks have finished.
There is, then, room for improvement.
Queue for π
It would be more ideal if the code to calculate the average could run in parallel to the simulations. The standard solution here is to pass a message from each thread to the collating code, as in listing 7. The running average is specifically designed to take a single item result and calculate a new average for all those seen so far.
var results = new ConcurrentQueue< int >();
var nthreads = 4;
var pi = 0.0;
Action action = delegate
{
foreach( var i in Enumerable.Range( 0,
count / nthreads ) )
{
var hits = Common.Simulate( simsize );
results.Enqueue( hits );
}
};
var tasks = Enumerable.Range( 0, nthreads )
.Select(
id => Task.Factory.StartNew( action ) )
.ToArray();
var n = 0;
while( n < count )
{
int hits;
if( results.TryDequeue( out hits ) )
pi = Common.RunningAverage( n++, pi,
Common.EstimatePi( hits, simsize )
);
}
Console.WriteLine( pi );
|
| Listing 7 |
In this version, the running average calculations will begin as soon as results start appearing on the queue. Now the calculation of π happens in parallel with the simulations themselves.
The use of a queue also provides a natural synchronisation; the loop which collates the results will not complete until all the results are available.
Altogether a much better solution.
Embarrassing π
It’s worth noting at this point that the simulations have become almost embarrassingly parallel; each thread is independent of every other, and in particular doesn’t depend on the results of any other thread. The only point of shared contact is the queue into which results are placed. The use of a concurrent queue means there is no explicit locking of shared resources, but the locks are there nevertheless.
However the code can still benefit from techniques normally used for embarrassingly parallel problems.
Listing 8 makes use of the
Parallel
class available in .Net 4.0. Instead of explicitly launching threads to handle the simulations, the
ForEach
algorithm dispatches
enough
threads to satisfy the given range. For the first time, there is nothing in the code to specify how many threads will run. The
Parallel
class ensures that the best use of available resources is made to execute the code.
var results = new ConcurrentQueue< int >();
var pi = 0.0;
Action< int > action = delegate( int i )
{
var hits = Common.Simulate( simsize );
results.Enqueue( hits );
};
Parallel.ForEach(
Enumerable.Range( 0, count ),
action );
var n = 0;
while( n < count )
{
int hits;
if( results.TryDequeue( out hits ) )
pi = Common.RunningAverage( n++, pi,
Common.EstimatePi( hits, simsize )
);
}
Console.WriteLine( pi );
|
| Listing 8 |
Distribute the π
To this point, all of the code to perform the simulations has been in-process , making use of multi-threading capabilities and supporting features to make the optimum use of a multi-CPU or multi-core environment.
The problem is that many applications for which Monte-Carlo simulation is appropriate are not as simple as estimating π, and are likely to be much more demanding of the available hardware. The π estimation simulation is, in fact, CPU intensive, but more sophisticated problems may also be memory-bound.
One solution to running simulations where there is insufficient memory to perform many calculations (or possibly more likely, insufficient address space) is to add more memory and address space, by for example upgrading to a 64 bit machine and operating system. This isn’t scalable, however, and merely pushes the problem back until yet more memory is required.
A more scalable and general solution is to use more than one machine: a grid.
It doesn’t make much difference whether the grid is a high-availability cluster, a tightly coupled internal network, or distributed over the Internet, the major difficulty is distributing, running and communicating with the code. To handle this, some kind of middleware is appropriate.
The middleware used here is 0MQ [ 0MQ ], an open-source messaging library with bindings for many languages, including C#.
| Endpoints | |
|
No π?
Listing 9 shows an application that handles collating the results from a simulation. It’s notable because the simulation code is nowhere to be seen, and isn’t even apparently invoked. Instead, messages are consumed from a message queue, and plugged into the now-familiar running average calculation, until the requisite number of results has been received.
static void Main()
{
var simsize = 999999;
var count = 100;
using( var context = new Context( 1 ) )
using( var results =
context.Socket( SocketType.PULL ) )
{
results.Bind( "tcp://*:55566" );
var n = 0;
var pi = 0.0;
while( n < count )
{
var recv = results.Recv();
var hitsString =
Encoding.UTF8.GetString(recv);
var hits = int.Parse(hitsString);
pi = Common.RunningAverage( n++, pi,
Common.EstimatePi( hits, simsize )
);
}
Console.WriteLine( pi );
}
}
|
| Listing 9 |
Listing 10 shows the code for the simulations ‘engine’. Once again, it makes use of the
Parallel.ForEach
algorithm to internally launch several threads, but instead of attempting to service a number of calculations, it’s limited to a number of threads.
static void Simulator( Context ctx, int count,
int simsize )
{
using( var results =
ctx.Socket( SocketType.PUSH ) )
{
results.Connect( "tcp://localhost:55566" );
foreach( var i in Enumerable.Range(0, count) )
{
var hits = Common.Simulate( simsize );
results.Send( Encoding.UTF8.GetBytes
( hits.ToString() ) );
}
}
}
static void Main()
{
var simsize = 999999;
var count = 100;
var nthreads = 4;
using( var context = new Context( 1 ) )
{
Parallel.ForEach(
Enumerable.Range( 0,nthreads ),
i => Simulator( context,
count / nthreads, simsize ) );
}
}
|
| Listing 10 |
The message service connects to an endpoint defined by the collating application (If this sounds counter-intuitive, see sidebar), and ‘publishes’ its results to that connection.
As with the in-process queuing solution shown in listing 7, there is a natural synchronisation in the collating application (listing 9) in that reading from the queue blocks until there are messages available. Also similar between the two methods is that the collating can begin as soon as there are results available, and so operates in parallel with the simulation service.
Key to the benefits here, though, is that the code in listing 9 is a separate process to listing 10 – each has its own
Main()
. It might not be obvious, but the implication of that is that these two separate programs can be run on different machines – provides that those machines can communicate over a network using the specified port number.
1
Modifying the hostname to be something other than ‘localhost’ in listing 10 would enable this.
2
The benefit of each simulation having a large sample size, and using a (relatively) small number of simulations (alluded to in ‘Average π’) should now be evident. When operating in a distributed environment, it’s important for performance that the cost of the calculation is not swamped by the cost of 10 the distribution, i.e. the relative expense of running the simulation is worth the effort to communicate over a network.
Talkin’ π
Just because the code has now been changed to allow it to be executed in a distributed environment, that doesn’t mean it necessarily must be.
Listing 11 shows an in-process simulation ‘service’ running in parallel to the main collating code in the same way as listings 9 and 10.
static void Simulator( Context ctx, int count,
int simsize )
{
using( var results =
ctx.Socket( SocketType.PUSH ) )
{
results.Connect( "inproc://results" );
foreach( var i in Enumerable.Range(0, count) )
{
var hits = Common.Simulate( simsize );
results.Send( Encoding.UTF8.GetBytes
( hits.ToString() ) );
}
}
}
static void Main()
{
var simsize = 999999;
var count = 100;
var nthreads = 4;
using( var context = new Context( 1 ) )
using( var results = context.Socket
( SocketType.PULL ) )
{
results.Bind( "inproc://results" );
var tasks = Enumerable.Range( 0, nthreads )
.Select
( id => Task.Factory.StartNew(
() => Simulator( context,
count / nthreads,
simsize ) ) )
.ToArray();
var n = 0;
var pi = 0.0;
while( n < count )
{
var recv = results.Recv();
var hitsString =
Encoding.UTF8.GetString(recv);
var hits = int.Parse(hitsString);
pi = Common.RunningAverage( n++, pi,
Common.EstimatePi( hits, simsize )
);
}
Console.WriteLine( pi );
}
}
|
| Listing 11 |
The difference here is that the Simulator is now being run directly as a thread, and launched in the same way as shown in previous sections (notably in the section called ‘Queue for π’) which uses a concurrent queue).
Although it’s not necessary to do so, the addressing method for the 0MQ sockets has changed; instead of using a ‘tcp’ protocol definition with a port number (and ‘localhost’ in the case of the connecting code) the binding and connecting addresses are now symmetric, using the ‘inproc’ protocol and a symbolic name for the connection.
There are pros and cons to using this approach; a benefit of the 0MQ connection model that has not been mentioned so far is that a ‘tcp’ socket can be connected that has not yet been bound ( not possible with raw sockets). The implication of that is important in a distributed environment: the ‘engines’ can all be running before the collating code (which binds the endpoint) has been launched. Using ‘inproc’, the endpoint must be bound before downstream connections can connect, or a runtime error occurs.
It is perfectly valid to use the ‘tcp’ protocol even in-process, and the performance degradation is minimal. Mileage, as ever, may vary between convenience and raw speed.
A minor problem
With one exception, the multi-threaded and distributed examples so far exhibit a common problem that has been consciously ignored. It is most noticeable in the original multi-threaded queue version in ‘Queue for π’.
Listing 12 shows the offending code from Listing 7. The problem really is minor, but significant.
Action action = delegate
{
foreach( var i in Enumerable.Range( 0,
count / nthreads ) )
{
var hits = Common.Simulate( simsize );
results.Enqueue( hits );
}
};
|
| Listing 12 |
If the number of simulations to perform is not an exact multiple of the number of threads used to service the requests, some further processing is required to mop up any remainder. This isn’t a difficult problem to solve but it suffers from two drawbacks:
- It is very easy to get wrong
- It duplicates code.
The exception so far has been Listing 8. There was no reference there to a particular number of threads; the
Parallel.ForEach
algorithm handled the mechanics of launching
sufficient
threads to service each element of the range it was given.
This concept doesn’t translate well into a distributed grid environment. Dynamically allocating engines to handle workload is difficult and error-prone. The out-of-process simulation shown in Listing 10 is internally multi-threaded. It doesn’t attempt to dynamically manage the number of threads, but launching multiple instances of that process would affect the characteristics of what are (in that example) hard-coded values for the number of simulations to run versus the number of threads within each process.
Of course, this problem is exacerbated by the fact that the reading client depends on receiving a pre-determined (and common) number of results. It’s probably desirable for the engines to have no knowledge of how many results they must produce.
Slimmer π
The real answer to this problem is to effectively return to single threaded processing.
Really.
Single threaded code is easier to write and easier to understand, and is easy to prove correct, so it has lots of built-in benefits. It does, of course, appear – on the face of it – to be at odds with making the best use of multi-CPU, multi-core and multi-engine processing.
In a distributed environment, however, even though each process is single threaded, there can be many processes . The use of a shared message queue that isolates each process from the code that handles the results, as well as other processes, does require a slightly different approach to designing the code.
One π at a time
The code in listing 13 shows a simulation engine that runs a single-threaded service. The program itself dispatches more than one thread simply so that the engine can be stopped ‘nicely’ without just killing it.
static void Simulator( Context ctx )
{
using( var work =
ctx.Socket( SocketType.REP ) )
using( var results =
ctx.Socket( SocketType.PUSH ) )
using( var done =
ctx.Socket( SocketType.PAIR ) )
{
done.Connect( "inproc://done" );
results.Connect( "tcp://localhost:55557" );
work.Connect( "tcp://localhost:55556" );
var finished = false;
var killEvent =
done.CreatePollItem( IOMultiPlex.POLLIN );
killEvent.PollInHandler += ( sock, ev ) => {
sock.Recv(); finished = true; };
var workEvent =
work.CreatePollItem( IOMultiPlex.POLLIN );
workEvent.PollInHandler += ( sock, ev ) =>
{
var simsize =
int.Parse( sock.Recv( Encoding.UTF8 ) );
sock.Send( Encoding.UTF8.GetBytes( "OK" ) );
var hits = Common.Simulate( simsize );
results.Send( Encoding.UTF8.GetBytes
( hits.ToString() ) );
};
var items = new []{ killEvent, workEvent };
while( ! finished )
ctx.Poll( items );
}
}
static void Main()
{
using( var context = new Context( 1 ) )
using( var done =
context.Socket( SocketType.PAIR ) )
{
done.Bind( "inproc://done" );
Task.Factory.StartNew(
() => Simulator( context ) );
Console.WriteLine( "Press [Enter] to exit" );
Console.ReadLine();
done.Send();
Console.WriteLine( "Done" );
}
}
|
| Listing 13 |
The beating heart of this code is the one-line while loop near the end of the
Simulator
method. It’s the lambda function attached to the
workEvent.PollInHandler
that does the work, however.
In truth, it is not so different to other versions of this code shown previously. Its main distinction is the idea of a message indicating a work item. In this case, a work item simply tells the engine how large a sample size to use for a single calculation. The engine does that calculation and then sends the result on a a different channel. Then, the code waits for the next work item, and will (hopefully) continue to run indefinitely until manual intervention stops it.
The vast majority of the remainder of the code is to setup the network connections, manage object lifetimes and handle graceful termination of the process.
As many instances of this process can be launched as necessary – on different machines if required, by modifying the ‘localhost’ address – to make the most of the available resources.
Having an engine that listens for work requests requires the existence of code to provide those requests. Listing 14 shows this in action.
static void Work( Context ctx, int count,
int simsize )
{
using( var work =
ctx.Socket( SocketType.REQ ) )
{
work.Bind( "tcp://*:55556" );
foreach( var i in Enumerable.Range
( 0, count ) )
{
work.Send( simsize.ToString(),
Encoding.UTF8 );
work.Recv();
}
}
}
static void Main()
{
var simsize = 999999;
var count = 100;
using( var context = new Context( 1 ) )
using( var results =
context.Socket( SocketType.PULL ) )
{
Task.Factory.StartNew(
() => Work( context, count, simsize ) );
results.Bind( "tcp://*:55557" );
var n = 0;
var pi = 0.0;
while( n < count )
{
var hits =
int.Parse( Encoding.UTF8.GetString(
results.Recv() ) );
pi = Common.RunningAverage( n++, pi,
Common.EstimatePi( hits, simsize ));
}
Console.WriteLine( pi );
}
}
|
| Listing 14 |
Once again a separate thread is used to send work requests so that collating the results in
Main()
can start as soon as results are available.
The π message
Anyone familiar with message-passing paradigms such as Actor model or CSP [ Wikipedia ] will recognise (broadly speaking) the code in the previous section. The 0MQ sockets are channels, with two incoming channels (one for work items, one for a ‘stop’ message) and one outgoing channel. The Simulator function is a ‘process’ or ‘actor’ that runs indefinitely.
Crucially the main idea of passing messages in systems using (for example) CSP is that that is the only way that processes communicate with each other.
The model here is more like Actor than CSP because the channels are buffered and asynchronous, whereas CSP channels involve a ‘rendezvous’ between sender and recipient. Also, the process has no identity. However, in common with CSP, messages are sent to channels with names; in this example the name is the address used to connect or bind a socket.
Apart from receiving the
Context
(a thread-safe socket factory) in its parameter list, the process interacts with the outside world only through the channels. There is no thread synchronisation and no shared state. The process runs until it’s told to stop – by receiving a message on a particular channel.
The difference from other common message-passing schemes in the CSP or Actor Model style is that messages can be passed on those channels between different machines.
The downside to this distribution is the loss of type-safety in messages; the content of each message needs to be agreed between clients and servers – often by convention. Some middleware tools provide a full Remote Procedure Call paradigm [ RPC ] whereby the type of a message is defined precisely in a definition language, and additionally there are libraries available that do not provide a transport, only the marshalling of data in a type-safe way.
Mixed π
Using a message passing middleware that provides bindings to multiple languages means that any supported language can be used as either client or server.
Listing 15 shows a Python version of the ‘client’ code to send work requests and collate results. This code will communicate happily with the calculation engines shown in Listing 14. The definition of
runningAverage
is left as an exercise for the reader.
def work( ctx ):
work = ctx.socket( zmq.REQ )
try:
work.bind( "tcp://*:55556" )
for i in range( count ):
work.send( str( simsize ) )
work.recv()
finally:
work.close()
def recv( ctx ):
results = ctx.socket( zmq.PULL )
try:
results.bind( "tcp://*:55557" )
pi = 0.0
nresults = 0
while nresults < count:
hits = int( results.recv() )
pi = runningAverage( nresults, pi,
estimatePi( hits, simsize ) )
nresults += 1
print( pi )
finally:
results.close()
if __name__ == ’__main__’:
ctx = zmq.Context( 1 )
try:
threading.Thread( target=work,
args=( ctx, ) ).start()
recv( ctx )
finally:
ctx.term()
|
| Listing 15 |
The last π
The benefits of grid computing and message passing are not limited to Monte-Carlo simulations. Any algorithmic problem that can benefit from using the resources of many machines can enjoy the benefits of being designed for message passing, but further than that, programs which use multiple threads can be improved by passing messages instead of sharing state.
Many of the perceived difficulties of writing and maintaining multi-threaded code arise from the sharing of state: deadlock, unwanted serialisation due to locking, context switching. None of these problems arise when passing messages is the only interaction between threads. All state is necessarily local to a thread, because it’s not really a thread – it’s a process.
Many tools are available for lots of languages to provide a message-passing environment for programs to use in an inter-thread capacity, but few provide the same facility to enable not just inter- process but inter- machine message passing with few (if any) changes to the code.
0MQ provides facilities to do exactly that, but at the cost of pure performance. Ultimately, the only way to determine if performance is sufficient for a particular application is to measure and, if necessary, compare results using different technologies. However, it’s always as well to remember that clean, simple and maintainable code to do a job will pay dividends in any case.
Especially if the very clarity and simplicity provides generality and flexibility, too.
Acknowledgements
Many thanks to Frances Buontempo for her patient tutoring in basic numeracy and helpful comments.
References
[MonteCarlo] See http://en.wikipedia.org/wiki/Monte_Carlo_method for more details
[0MQ] See http://www.zeromq.org
[RPC] ICE ( http://www.zeroc.com ) and CORBA ( http://www.omg.org/spec/CORBA ) are well known examples of the Remote Procedure Call paradigm.
[Wikipedia] http://en.wikipedia.org/wiki/Communicating_sequential_processes and http://en.wikipedia.org/wiki/Actor_model have more information about CSP and the Actor Model.
