








Correct use of memory is a major occupation of software development. Sergey Ignatchenko considers what we mean by ‘correct’.
Disclaimer: as usual, the opinions within this article are those of ‘No Bugs’ Bunny, and do not necessarily coincide with opinions of the translator or Overload editors; please also keep in mind that translation difficulties from Lapine (like those described in [ LoganBerry2004 ]) might have prevented from providing an exact translation. In addition, both translator and Overload expressly disclaim all responsibility from any action or inaction resulting from reading this article.
Memory leaks are one big source of problems which have plagued both developers and users for generations. Still, the term itself is not as obvious as it might seem, so we’ll start from the very beginning: how should a memory leak be defined?
Definition 1: the user’s perspective
I shall not today attempt further to define the kinds of material
I understand to be embraced . . . But I know it when I see it . . .
Justice Potter Stewart on the definition of obscenity
The first point of view we’d like to mention is the one of the user. It is not that easy to define, but we’ll try nevertheless. Wearing the user’s hat, I would start with saying that a ‘memory leak is any memory usage which I, as a user, am not interested in’. This one is probably a bit too broad (in particular, it will include caches which are never in use), so I (still wearing the user’s hat) will settle for a less all-inclusive definition 1 :
A memory leak is any memory which cannot possibly be used for any meaningful purpose.
Definition 2: the developer’s perspective
In developer (and computer science) circles, definitions similar to definition 2 are quite popular:
A memory leak is any memory which is not reachable.
Here ‘reachable’ is a recursive definition, and ‘reachable memory’ is memory which has a reachable pointer to it – or stack, and ‘reachable pointer’ is a pointer which resides within reachable memory.
This definition is much more formal than our definition 1 (and therefore it is much easier to write a program to detect it), but is it a strict equivalent of definition 1 ? Apparently, it is not: let’s consider the Java program (Program 1) in Listing 1.
Vector bufs = new Vector();
while( true )
{
String in = System.console.readLine( "..." );
if( in == "*" )
break;
byte buf[] = new byte[ 1000000 ];
bufs.add( buf );
// do something with buf
}
//bufs is not used after this point
|
| Listing 1 |
According to definition 2 , there is no possible memory leak in Java (the garbage collector takes care of unreachable objects). Still, according to definition 1 there is a memory leak. It illustrates that definition 1 and definition 2 are not strictly equivalent: at the very least, definition 1 has elements which are not members of definition 2 (see Figure 1).
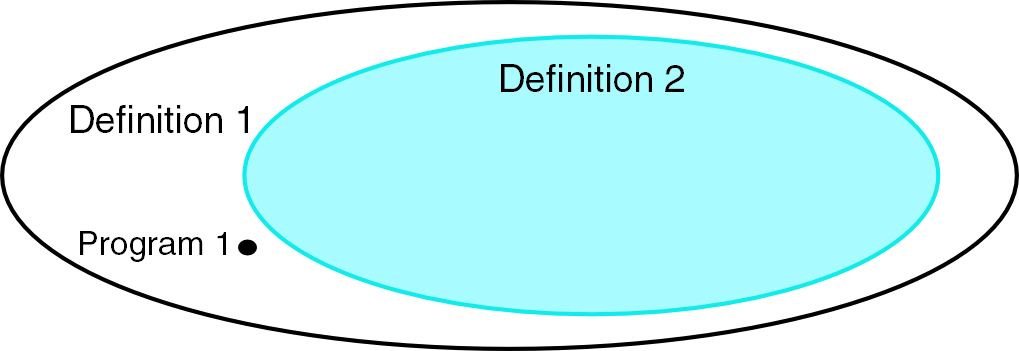
|
| Figure 1 |
It should be mentioned that, obviously, Program 1 shows just one trivial example, and much more sophisticated examples of such behaviour are possible (for example, code may allocate huge objects in response to some events, and forget to clean them up until some later event where these objects will be simply discarded without ever reading them).
Definition 3: the debugger’s perspective
Going even further into formalism, let’s consider a very popular way of memory leak detection deployed by many programs (from Visual Studio to Valgrind). These programs tend to keep track of all allocations and deallocations (either within the heap itself, or otherwise) and report whatever has not been deallocated at the program exit as a memory leak. This leads us to definition 3:
A memory leak is memory which has not been deallocated at the program exit.
It is fairly obvious that according to this definition, Program 1 doesn’t suffer from memory leaks, so definition 3 is not equivalent to definition 1 , and some of situations described as leaks by definition 1 , are not leaks by definition 3 . But can we say that all situations described as leaks by definition 3 , are leaks by definition 1 ? Apparently, we cannot. Let’s consider another program (Program 2) which allocates a buffer of 4K at the very beginning, uses it through the life cycle of the program and doesn’t deallocate it ever, relying on the operating system to clean up after the program terminates. Is it a memory leak? According to definition 1 (and assuming that our Program 2 runs under an OS which performs cleanup correctly) it is not; according to definition 3 , it is. It leads us to the relationship between definition 1 and definition 3 shown in Figure 2.
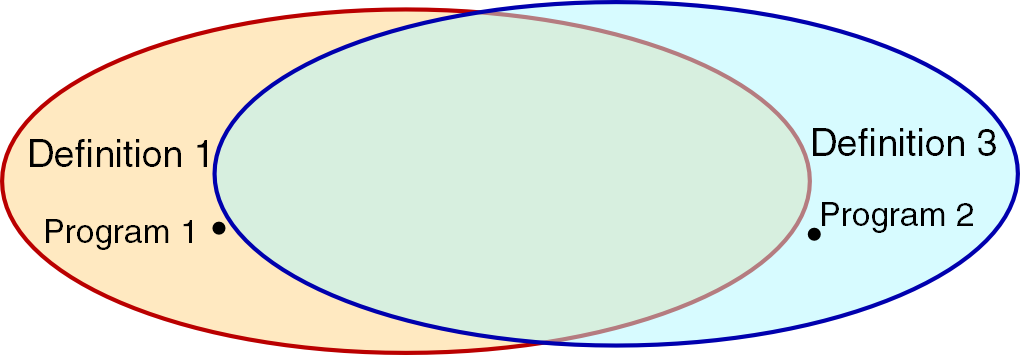
|
| Figure 2 |
Which definition is better?
Up to this point we haven’t asked ourselves which of the definitions is better and under which circumstances. We were merely trying to demonstrate that there are substantial differences between them. Now it is time to make a choice.
Remembering the teachings from an earlier article [ Bunny2011 ], we argue that the only correct definition is the one which comes from the User; this is not to diminish the value of tools like Valgrind, but to help to deal with situations when there is a disagreement over whether a certain behaviour is a leak or not.
Some time ago I was in a rather heated debate about a certain program. That program did indeed allocate about 4K of memory at the start (for a good cause, there was no argument about it) and did not bother to deallocate it at all. Obviously Visual Studio had reported it as a leak, and obviously there were pious developers who took Visual Studio’s leak reporting as gospel and argued that it was a bug which must be fixed. However as a fix would be non-trivial (in a multithreaded environment, dealing with deallocating globals is not trivial at all) it would likely cause real problems for end-users, and so I was arguing against the fix. Now, the answer to this dilemma is indeed rather obvious: in case of any disagreements between the various definitions of memory leaks it is definition 1 , and not any other definition, which should be used to determine if program behaviour qualifies as a leak.
Going a bit further we can ask ourselves – what exactly is the purpose of all those deallocations at the end of the program? Why not simply call
ExitProcess()
or
exit()
after all necessary disk work has been completed and all handles closed? Sure, it is sometimes better to simply call all destructors for the sake of simplicity (and therefore, reliability), but on the other hand, if I’m a user why should I spend my CPU cycles on performing unnecessary clean up work? To make things worse, if the program uses lots of memory then a lot of it is likely to have been swapped out to virtual memory on the disk. So to perform the unnecessary deallocations, it will need to be swapped into main memory causing significant inconveniences to the user (if you have ever wondered why closing a web browser takes minutes – this is your culprit). To summarize our feelings on this issue of deallocation at the end of the program – we do not argue that
ExitProcess()
or equivalent is the only way to handle the issue, but we argue that it is one of the possible ways which at least in some cases has a certain value (especially if full-scale deallocation is still performed during at least some test runs to detect real memory leaks). One reasonable solution, from our point of view, would be to try to have all destructors and deallocations in place, and to run all the tools in debug mode, while resorting to
ExitProcess()
or equivalent in release; while there is a drawback that release mode becomes not quite equivalent to debug mode, in many cases it can still be tested properly (especially if QA tests the release version).
Formalism results in approximation
The whole story of multiple definitions of memory leaks is quite interesting if it’s viewed from a slightly different (and less practical) angle. We can consider definition 2 as a formal approximation of the much less formal definition 1; as we’ve seen above this approximation is apparently not 100% precise.
Further, we can consider definition 3 as a further, even more formal, approximation of definition 2, and once again this is still an approximation, and again it is not 100% precise. This leads us to an interesting question: is it necessary that adding more formalism leads to a loss of original intention?

References
[Bunny2011] ‘The Guy We’re All Working For’, Sergey Ignatchenko, Overload #103
[LoganBerry2004] David ‘Loganberry’, ‘Frithaes! – an Introduction to Colloquial Lapine!’, http://bitsnbobstones.watershipdown.org/lapine/overview.html
