








1. SO WHAT'S THE PROBLEM?
Since time zero, Fortran has been the lingua franca of the numerics world. Yet Fortran's shortcomings have become a tired joke amongst programmers. Its limited type checking, lack of extensibility, reliance on global data, etc., make it extremely hard to maintain and debug. So why does it survive?
The reasons are simple: momentum and efficiency. Countless complicated algorithms have been written in Fortran. No one wants to rewrite them. And, for all its warts, Fortran is still an extraordinary efficient language.
It is not good enough to offer a language that's just better than Fortran. If people are to switch, then this language must not only be the equal of Fortran in terms of efficiency and reuse of old code, but it must also be a lot better in terms of productivity, maintenance and power.
A tall order! But C++ can meet these criteria, making it (in my mind) the first serious contender to challenge Fortran's supremacy. With care, C++ can meet Fortran's efficiency (although not exceed it, except in the sense that it can make previously too complicated algorithms feasible). It is also easy to call existing, known correct, Fortran code from C++ (at least under Unix and some dialects on the PC ). The kicker is that with C++, it can be much easier to build and maintain the really big, gnarly code that is being contemplated now:
- Encapsulation allows the grisly details of memory allocations, I/O parsing, " DO " loops, etc., to be hidden from the user.
- Operator overloading allows the basic arithmetic operations (+,-,etc.) to be extended to new, more abstract, atomics such as vectors and matrices, allowing error prone " DO loops" over vector and matrix elements to be eliminated. There are dialects of C and Fortran that allow this, but at the moment, they are non-standard. Operator overloading can also make it trivial to change the precision of a calculation from float to double.
- Inheritance , in combination with encapsulation and operator overloading allows new user defined types to be created with little extra work. If you find you need some special kind of vector, say one that support null values, then you need only add the functionality that is missing. The rest can be inherited.
- It is easy to base these vectors and matrices on the Linpack[ 1 ] Basic Linear Algebra ( BLA ) package for which highly optimised, machine language versions have been written.
- Complex numbers can be added to the language, correcting a major deficiency of C .
-
Dynamic binding
can allow
large parts of the problem to be
defined at
run-time
with
little increase in code complexity.
The goal here is to allow the programmer to concentrate on the high-level architectural issues of his or her code, and not on the implementation details. The aspiration is code that looks something like this:
ComplexVec b; // Declare a complex vector
cin >> b; // Read it in
FFTServer s; // Allocate an FFT server
// Calculate the transform of b:
ComplexVec the Transform = s.fourier (b);
cout << theTransform; // Print it out
It should not be necessary to know the size of the complex vector b at compile time - it should be determined automatically when the vector is read in. Nor should it be necessary to set up the traditional "work arrays" before calculating the FFT .
2. BUT WONT FORTRAN 9X SAVE US?
Fortran 9X offers substantial improvements over the current standard, Fortran 77, giving the language a level of portability and maintainability that is roughly equivalent to C . It is hard to imagine the language being taken seriously at all had the X3J3 standards committee not made such essential inclusions a recursion, dynamic memory allocation, and pointers. In other areas they went further and offer features from which other language designers can learn, such as built in support for vector arithmetic, eliminating " DO " loops in many situations (although the syntax is not pleasing). Structures ( TYPE , in the Fortran vernacular) are also a welcome addition.
But, many other modern concepts are missing. The language is far from supporting such key "object-oriented" concepts as inheritance and encapsulation, let alone polymorphism. Such useful C++ concepts as constructors and destructors and parameterized types are also missing. It is these key features, plus a host of other, smaller, features (const variables come to mind) that give C++ its unique blend of efficiency and maintainability.
It is my job now to show how these features can be put together to make a language that is suitable for writing clean, pleasing numerical code.
3. NUMERICS "IN THE SMALL"
The ability of C++ to define whole new types and an algebra to go along with them gives the language a chameleon-like quality. A Class designer can make the language look remarkably different, depending on what goals s/he is trying to achieve. Now it's a database language, now it's a graphical language. Let's look at some new types that are particularly well suited for numerics and how to implement them.
3.1 Vectors
Encapsulating arrays inside a vector class to give them a natural, predictable arithmetic is an obvious place to start. How might such a class look? We will have to decide such things as how the vectors would be constructed, what their arithmetic would look like, etc. For the sake of concreteness, let's look at how a vector of doubles (call it class DoubleVec ) might look. Let's start with a convenient set of constructors to allow us to create new vectors in a predictable way:
// Null vector - no elements at
// all, but can be resized
DoubleVec a:
// 8 elements long,uninitialized
DoubleVec b(8);
// 8 elements, initialised to 1.0
DoubleVec c(8,l);
// 8 elements, initialised to 1,3,5, ...
DoubleVec d(8,l,2);
We will want to add some basic arithmetic and assignment operations:
b = 2.0; //Set all elements of b to 2
b = c + d; //Set b to the sum of c and d
b *= 2; //Multiply each element in b by 2.
Such arithmetic operations are natural and predictable. Their concepts can be grasped in a glance.
We will also want to address individual elements of the vector:
// Set the 3'rd element of b to 4.0
b[2] = 4.0;
// Set the 2'nd element of c to the
// 4'th element of b
c[l] = b[3];
But, now suppose that we want to set every other element of a vector to some value. It defeats the purpose of abstraction if we have to write something like this:
DoubleVec a(10, 0); // 10 element vector
for(int i = 0; i<10; i+=2)
a[i] = 1;
Having taken the trouble to encapsulate the array elements into a vector, alarm bells should go off in our head if we start to take the vector back apart and address individual elements. The results are likely to be slow and hard for the compiler to optimise. Instead, we want to tell the program, in some abstract sense, to "set every other element to one".
The key to maintaining a high-level of abstraction is the slice . This allows elements separated by a constant stride, say every 2'nd element, to be addressed:
// Starting with element 0;
// set every other element to 1
a.slice (0, 2) = 1;
The slice is an extremely powerful abstraction that can be used to implement a vast variety of algorithms. As an added bonus, the BLA routines (see above) have been programmed in terms of slices, so we can take advantage of existing, highly optimised versions of this package to implement our slice arithmetic.
There are two architectural approaches to implementing slices: with a helper class or building them right into the vector class. Each has its own advantages, although it turns out that the role of slices in algorithms is so fundamental that the second approach (builtin slices) tends to lead to cleaner, more efficient code. Nevertheless, it is useful to take a look at the first approach.
What do we mean by a "helper class"? Let's look at an example (the actual vector data has not been shown in the interest of clarity):
class DoubleVec {
...
public:
...
// For type conversion
operator DoubleSlice();
DoubleSlice slice (int start,
int step,
unsigned N) const;
};
// The "helper class":
class DoubleSlice {
DoubleVec* the Vector;
int startElement;
unsigned sliceLength;
int step;
public:
...
friend DoubleVec operator+
(const DoubleSlice&,
const DoubleSlice&);
...
};
In addition to the basic vector class DoubleVec , we have a second, helper, class named DoubleSlice which contains the data necessary to address the "sliced" elements. The member function slice() returns an instance of this class. All of the arithmetic operators (+,-,setc.) must be implemented using DoubleSlice s as an argument (as per the + operator in the code strip above) to allow expressions such as:
DoubleVec b(10, 0), c(10, 1);
DoubleVec d = b.slice (0, 2)
+ c.slice (1, 2);
This leads to slow code because a simple vector must continuously undergo a type conversion to the helper class:
// DoubleVec to DoubleSlice
// type conversion occurs
DoubleVec g = b + c;
Alternatively, one could implement two versions of the arithmetic operators, one taking the vector as an argument, the other the helper class, but then this leads to type conversion ambiguities. This is why, in practice, building slices right into the vector class leads to much simpler code: type conversion becomes much simpler.
| Listing 1a |
// This class holds a reference count and a }; |
| Listing 1b |
class DoubleVec {
|
The constructor specifies the number of elements in the vector and the size (in bytes) of each individual element. Note the destructor. The reference count insures that the vector data is not prematurely released if more than one vector is using it. Every reference increases the count by one, every deletion decrements it by one. The count must be zero before the data pointed to by array is deleted. But what about the DataBlock itself? Won't it be deallocated, taking the reference count along with it, when the destructor is done? This is the job of the overloaded delete operator - it will only release the storage of the DataBlock itself when the references count is zero.[ 2 ]
Now here's an outline of the actual vector. It includes a pointer to the DataBlock , outlined above.
Contained within the
DoubleVec
is not only a pointer to the
DataBlock
containing the
reference count, but also a pointer to the
start of data (and the slice) called
begin
.
This is also where the
actual data type occurs. This approach allows multiple types to share
the same
DataBlock
and
eliminates one level of indirection at the
expense of some extra storage space. As we shall see, it also allows
some highly expressive statements.
There's one other wrinkle. Note the variable step . This the stride length - the step size between contiguous elements of the vector. A conventional vector is a slice that starts with the zero's element and has a stride of one.
A slice of an existing vector is created by calling the member
function
slice()
which, in
turn, uses a special constructor. Here's
what it looks like:
|
Listing 2
|
// Construct a vector that is a slice of an
|
The combination of a generalised starting element and stride allows for some very powerful, and intuitive expressions. For example, it's trivial to return all of the real parts of a complex vector as a DoubleVec : it's just a slice of every other element in the complex vector[ 3 ]. The result is that the function
DoubleVec real(const ComplexVec&);
can be used as a lvalue:
ComplexVec a(10, 0); //(0,0), (0,0), (0,0), ...
real(a) = 1.0; //(1.0), (1,0), (1,0), ...
3.2 Matrices
Matrices are an extremely important part of numerics. They can easily be created by inheriting from a vector:
There is a lesson in here some place. Helper classes are fine, but
when the code will depend on them fundamentally, then the results will
be slow and type conversions will always be ambiguous. You should
re-examine your approach to see if your problem depends on what they
are trying to accomplish in some fundamental way. If so, you might be
better off finding a way to eliminate them, even if that makes the
remaining classes slightly more complex.
|
Listing 3
|
class DoubleMatrix : private DoubleVec {
|
Now it's time to see how our emerging vector class might be implemented. Here's a schematic outline of an alternative vector class that builds slices right into it (some things, such as error checking, efficiency optimisation, and code dealing with a few special cases, have been omitted in the interest of clarity). First comes the vector data, which can be shared by more than one type of vector. It contains a reference count and a pointer to an array of raw untyped data:
Note the member functions col(unsigned) and row(unsigned) . They return a column or row, respectively, as a vector slice, allowing expressions such as:
// 10 by 10 matrix, initialised to zero
DoubleMatrix a(10, 10, 0);
a.row(3) = 1; // Set row 3 to 1
// Copy column 4 to column 2
a.col(2) = a.col(4);
With a little thought, it is even possible to return the diagonal as a slice!
// 10x10 initialized to 0
DoubleMatrix I(110, 10, 0);
// Create an identity matrix
I.diagonal() = 1;
(How to do this is left as an exercise to the reader!)
3.3 Linear Algebra
Matrix decomposition's, such as LU Decomposition and Singular Value Decomposition (SVD) , occupy a central role in linear algebra. But they are messy things: exotica like pivot indices, conditioning numbers, nullspace and range vectors abound. Gathering all this stuff into one place as a C++ class makes them much easier to work with. In this section, we will see how to do this with LU decomposition's.
The LU decomposition of a matrix consists of finding two matrices such that A = LU where L is lower triangular and U is an upper triangular matrix. This decomposition can then be used to do things like solve sets of linear equations. Here's how such an LU decomposition class might be structured:|
Listing 5
|
class LUDecomp : private DoubleMatrix |
Note the constructor: an LU decomposition is "constructed" from a matrix. For computational reasons what is actually calculated is the LU decomposition of a rowwise permutation of the original matrix. The vector of inst "permute" is used to keep track of the original index of each row. The rest of the construction process consists of calculating the lower and upper diagonal matrices L and U which are then packed into a private matrix base class of the same dimensions as the original matrix.
Note that several of the more ugly details of LU decomposition can be hidden behind the veil of encapsulation. For example, it is of no interest (or concern) to the user that the L and U matrices are being stuffed within a single matrix - hence the private declaration of the base class. It is also of no concern that it is a rowwise permutation of the original matrix that is being decomposed.
Here's how to use such a class:
DoubleMatrix a(10, 10);
// ... (initialise a somehow)
// Construct the LU decomposition of a:
LUDecomp aLU(a);
// Now use it:
double det = determinant (aLU);
DoubleMatrix aInverse = inverse (aLU);
We can also use the LU decomposition to solve a set of linear equations a x = b using the friend function solve() . Notice that once we have gone to the trouble of calculating the LU decomposition of a matrix, we can use it to solve as many equations as we like in a fraction of the time it takes to work with the original matrix:
// 5 difference sets of linear equations
// to be solved:
DoubleVec b[5], x[5] ;
// ... (set up the 5 vectors b and the 5
// vectors x, each with 10 elements
// as per the matrix as above)
for(int i = 0; i < 5; i++)
x[l] = solve(aLU, b[i]);
Here, we are using the LU decomposition to solve 5 different sets of equations, each with 10 unknowns:
a xi=bi; i = 0,..., 4.
For the user that doesn't even want to worry about LU decomposition's (let alone their private secrets), type conversion can play an attractive and convenient role. In the examples above we have chosen to create the LU decomposition first and then use it to calculate, say, the inverse of the matrix, but we could have just requested the inverse of the original matrix and let type conversion do the work for us!
DoubleMatrix a(10, 10);
// ... (initialise a)
// Calculate the inverse directly from a.
// A DoubleMatrix to LUDecomp type conversion
// takes place automatically:
DoubleMatrix aInverse = inverse(a);
Seeing no prototype inverse(const DoubleMatrix&) the compiler will look around for a way to convert the DoubleMatrix a into something for which it has a prototype. Discovering the constructor LUDecomp (const DoubleMatrix&) the compiler will invoke it in order to call inverse(const LUDecomp&) . There are, of course, limitations to this approach: if there is more than one decomposition possible (SVD, for example) then the user must specify the conversion explicitly lest the compiler issue an error about ambiguous type conversions:
DoubleMatrix alnverse = inverse(LUDecomp(a));
3.4 Transforms (FFTs and all that stuff)
|
Listing 4
|
class FFTServer {
|
Any algorithm that requires an expensive precalculation before use is a good candidate to become a class. An example is the Fast Fourier Transform. To transform a vector of length N, the M'th order complex roots of 1 must be calculated, where M is the set of prime factors of N. For example, if N is 30, then the 2'nd, 3'rd, and 5'th order complex roots (2x3x5=30) of one must be calculated. This is an expensive calculation: if you are going to transform many vectors of that length, you don't want to throw the results away. The solution is to design a server class which holds these roots: at any given moment, it is configured to transform a vector of a certain length. Here's an outline of such a class:
The "roots of one" of all the prime factors of a vector of length npts are packed into the complex vector theRoots. They are calculated at three possible times: when the server is constructed, when the user calls setOrder(unsigned) or dynamically, when the server transforms a vector. Because of this last capability, using such a server is a pleasure because you don't have to worry about whether it is configured correctly to transform a given vector. If it's not, it will automatically reconfigure:
ComplexVec timeVector(30);
FFTServer aSvr; // Allocate a server
// Will automatically reconfigure for a
// vector of length 30:
ComplexVec spectrum =
aSvr.fourier(timeVector);
Of course, each reconfiguration is an expensive proposition, so if you plan to transform a bunch of vectors of varying length, you will probably want to keep many servers on hand. The bookkeeping to do this is far easier with self-contained servers than it is with the equivalent Fortran approach (you could even use a hashed-table lookup to find the correct server, making a super-server!).
4. WHAT ABOUT EFFICIENCY?
All of these features would be of little interest to the Fortran programmer if the price came as reduced efficiency. This section discusses two benchmarks designed to show that it need not be so.
Nearly all numerical algorithms come down to performing binary operations on large numbers of elements - that's why pipelined architecture's on such vectorizing machines as the CRAYS have been so effective and popular. Hence, it is important to get this right.
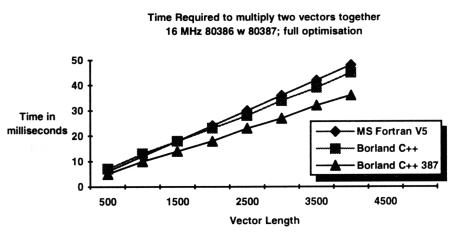
Figure 1 shows the time required to multiply two vectors together as a function of the vector length, for both C++ (using Rogue Wave's Math.h++) and Fortran. The code required to do this is on the accompanying disk.
The figure demonstrates that there is a small start-up time penalty for C++ and, thereafter, the cost per multiply is the same. Most of this start-up time is spent doing dynamic memory allocations (for Math.h++'s dynamically allocated arrays, as opposed to Fortran's statically allocated arrays). Should even this start-up time be unacceptable, it is easy enough (through inheritance) to create a customised vector class that uses statically allocated data. But then, of course, you would be limited (as in Fortran) to vectors whose length was set at compile time.
Figure 2 (on the accompanying disk) shows a different measure of
efficiency; the venerable Linpack benchmark. This benchmark sets up a
matrix, factors it (using
LU
Factorisation),
then solves a set of
linear equations using that factorisation. Only the factorisation and
solution time is actually used in the benchmark (the matrix set-up time
is not measured). Two versions are shown: one in C++ (using Math.h++)
and the standard Fortran version, the code listings have been set
up such that comparable statements line-up side-by-side. Some comments
are in order.
|
|
|
Figure 1
|
The time required to multiply two vectors together as a function of vector length, using Microsoft Fortran and two different versions of Math.h++ (both compiled with Borland C++). The first version used 8087 specific code, the second, 387 specific code. |
First, note the use of inheritance to guarantee that the test matrix and the "right hand side" of the sets of linear equations (called DTestMatrix and DTestRHS , respectively) are set up correctly. While this uses a few extra lines of code, it recognises these two objects for what they are: unique and "special", requiring a certain (and, in this case, intricate) initialisation matrix to be passed onto a special function to be initialized, in a large project we might neglect to do this, risking an improper initialisation. Yet, because of inheritance, these "special" objects inherit all of the abilities of their underlying base classes.
Second, note how simple and more intuitive the calculation of a tolerance, residual, and norm becomes.
Finally, note that despite the extra abilities of the C++ code in terms of type checking, dynamic memory allocations, and safe construction of objects, the code still requires fewer lines of code. It also executes (slightly, but probably not significantly) faster.
5. NUMERICS "IN THE LARGE"
We have seen how the encapsulation and operator-overloading properties of C++ can give rise to an impressive, and pleasing, economy of expression for such "in the small" objects as vectors, matrices, FFT servers, etc. This is useful, but not enough for working with those really big gnarly projects where problems expand faster than they can be contained.
Let's look at an example of how we might structure a relatively simple problem[ 4 ]. Suppose one wanted to model the motions of a vibrating string under the influence of a spatially and temporally varying force of (as yet) unknown origin. Here is the governing equation:
δ2u δ2u ——— - c2——— = F(x,t) δt2 δx2
where u is the string displacement x is space, t is time, c 2 is the string tension over the string density, and F(x,t) is the external force applied to the string.
How might we model such a problem? Let's start by specifying two objects: the string, and some abstract force:
class Force; //1
class String { //2
public:
String(double length,
double tension,
double density); //3
void setPoints(int nx); //4
void timeStep(double dt,
const Force& force); //5
DoubleVec displacement() const; //6
private:
DoubleVec u; //7
double cSquared;
double length;
};
Let's look at what we've done, line by line, and see how it enforces the abstraction of the problem.
- This line alerts the compiler that the keyword " Force ", which we will define later, is actually a user-defined class.
- This is where the declaration for the class " String " starts. In it, we will define all the external properties that are needed to create, manipulate, and observe a string.
- This is how to construct a string. We need its length, its tension, and its density.
- Here's how we specify the resolution of the numerical representation of the string, i.e., the number of points that will be used to represent it.
- This is how we will time step the problem. To calculate the new position of the string over a time step we need to know how long the time step is ( dt ), and the forcing function ( force ).
- Here's how we ask the string for its current displacement. This is returned as a vector of doubles.
-
This is the private section of the declaration where the actual
implementation details are hidden. Variables that will be obviously
useful are the string displacement, tension, and length. We
may have to introduce other variables that are used as
intermediates in the calculations.
Of course, the actual solution procedure will not be trivial and this is only the barest of outlines. For examples, we are starting with a single equation second order in time -we will probably want to change that to two equations first order in time.
Now let's look at the abstract class FORCE . A fundamental assumption is that we do not know much about the nature of FORCE . Indeed, it may even depend on the string displacement (for example, the force of the wind on a bridge depends on the displacement of the bridge).
class Force {
public:
virtual DoubleVec value() =0; // 1
};
That's it! We will use inheritance to define the actual details of the force. For example, a wind type force acting on the string might look like:
class WindForceString : public Force {
public:
WindForceString(String& string,
double dragCoeff );
void setVelocity(double windspeed);
virtual DoubleVec value(); // 1
private:
String& myString;// The string we are
// tracking
double wind; // Present wind speed.
double drag;
};
We are explicitly recognising that the force of the wind will depend on the displacement of the string by requiring that a specific string be used in the constructor (as well as on a drag coefficient). This WindForceString object will then track the string, asking it for its present displacement, before calculating the resultant force of the wind on the string and returning it. This is done by calling the virtual function value() , an example of polymorphism , a fancy word for runtime binding. Here's how value() might be implemented:
DoubleVec WindForceString::value()
{
// Get present string displacement:
DoubleVec d = string.displacement();
// Some (bogus) calculation
return -drag*wind*wind*d;
}
It then becomes trivial to replace the forcing function, even at run time, with another type of force. Note how this is something more than just passing a generic vector of doubles to the String that represents the forcing function. We can have an actual object, complete with feedback loops to the string act as the forcing function.
6. CONCLUSIONS
As we have seen, C++ has tremendous potential in numerics, one that has gone largely unnoticed by fans of object-oriented programming, perhaps because previous OOP languages lacked the efficiency required to do numerics. C++ has this efficiency, plus a lot more!
Notes
- Dongarra, JJ., Bunch, J.R., Moler, C.B., Stewart, G.W.,LINPACK Users' Guide, Society for Industrial and Applied Mathematics, 1979
- In ancient times (pre-summer 1989) the same effect could be accomplished by setting "this" to zero if the reference count was non-zero, disabling the automatic deallocator. The present method is a bit less efficient locally, but allows more 'aggressive optimisations globally.
- Perhaps this isn't the safest approach: it assumes a known structure for type complex. It would fail if someone implemented complex using, say, polar notation. Nevertheless, the functionality could be retained by using a helper class.
- This is the problem of "object-oriented design". A highly recommended book on the subject is Grady Booch's "Object-Oriented Design with Applications", published by Benjamin Cummings, 1991, ISBN 0-8053-0091-0.
