








We often find ways to hide complexity. Sergey Ignatchenko looks at how this can be sub-optimal.
Disclaimer: as usual, the opinions within this article are those of ‘No Bugs’ Bunny, and do not necessarily coincide with opinions of the translator and Overload editors; please also keep in mind that translation difficulties from Lapine (like those described in [ LoganBerry ]) might prevent us from providing an exact translation. In addition, both the translator and Overload expressly disclaim all responsibility from any action or inaction resulting from reading this article.
A story to freeze the blood
Tharn (Lapine) – stupefied by terror
Here is the horror story told to me on a Christmas night by one of my fellow rabbits (later he agreed to me publishing it on condition that I will never reveal his name):
I will never forget the night it happened. It was a quiet night and I was downloading a 2G ZIP file with Internet Explorer. Suddenly there was a loud beep. I sprang out of sleep and looked at the monitor. Nothing looked out of the ordinary except there was a message box saying that it needs 2G of free space on the drive. ‘Whaaaaaat?’ I thought, ‘Last time I saw the progress bar it was at 90% downloaded, what does it need another 2G for?’ Summoning my courage I copied 2G of files to an external drive and clicked the button to tell IE about it. All of a sudden IE started to copy the file (which had already been downloaded) from its cache to the location that I originally asked for. Positively tharn, I waited while this blood-curdling process has been completed. When it was over I thought that the worst was behind me. I couldn’t have been more wrong. When I clicked ‘Open’ my computer froze: even the mouse cursor didn’t move. After several long horrifying minutes, when my trembling hand was already reaching for the power button, I suddenly noticed a constantly lit HDD light. ‘It is not a virus, the damn thing is just swapping!’ flashed through my mind. Oh, it was a great relief. From that point it didn’t take more than ten minutes (swapping the 1G of RAM I have is a rather long process) and half a dozen of clicks to unpack the whole ZIP file and reach what I needed. Interestingly enough, I didn’t need to free any more space for the unpacked files.
Cold-blooded analysis
After listening to such a chilling story, we’ll have to warm our blood a bit before we start analyzing this horrifying sequence of events in cold blood (suitable methods of heating are beyond the scope of this article). Putting on a deerstalker and using Holmesian deduction [ Holmes ], we can establish the following points rather quickly:
- IE always downloads a file to a cache rather than to the final destination, even though it removes it from the cache right after the copying.
- IE always copies the file from the cache to the final destination and then deletes the cached one, even if they are on the same partition so moving the file instead would be equivalent and orders of magnitude faster.
- When IE copies file from the cache to the final destination it doesn’t block Windows from caching in memory the file being copied even if the file is 2G in size and the total amount of RAM is 1G, which makes it nothing but cache poisoning. Windows, on the other hand, went to great lengths to perform this caching in the best possible way (from its own point of view), swapping out active programs to cache perfectly useless portions of the file.
None of the things above makes any sense in our case. But now we need to understand the motives behind this horrible crime against the end-user (who’s the one we’re all working for [ NoBugs11 ]) and CO2 emissions. Going further in our deduction exercise, we can easily notice that all three cases are related to using an abstraction (or abstractions) which is useful in many cases but fails in our specific case. For item 1, we can safely assume that it was a concept ‘download everything to the cache’ which has misfired. For item 2, it was the combination of two separate abstractions ‘after downloading, copy files from the cache to the destination’ and ‘remove file from the cache when it is no longer needed’, which became deadly inefficient when used together because of the lack of interaction between them. For item 3, it was an abstraction of ‘cache files in RAM’, which makes sense in general, but when used for huge files such an oversimplified approach has caused cache poisoning, and severely hit the overall process.
The combination of these misused abstractions has caused about 6G of data to be copied between RAM and the HDD without any real reason behind it: first, IE has copied the 2G file from its cache to the final destination (requiring 2G of data to be moved into memory, and then back to file for a total of 4G); second, Windows swapped out (roughly) 1G of RAM while the file was copied, and third, it swapped 1G of RAM back in. Still, even if all this outright unnecessary operations are eliminated, the process will still lack from end-user point of view: the user would still need to move 2G of data to another HDD to free the space, which is used only temporarily.
And one more point
- If we think how the end-user would ideally like to see it, we notice that (given what is usually done with ZIP files) it is clearly possible and feasible for IE to ask the user (even before downloading) if they wants to extract the ZIP file ‘on the fly’; and if user knows that s/he really only needs the extracted files then no extra copying will be necessary, saving another 8G of HDD operations (4G for freeing space, and 4G for unzipping).
We should note that the lack of implementation of item 4 can be attributed to a ‘download file, then call application which handles it’ abstraction which is very useful in general, but fails to address specific cases (for us, downloading large ZIP files).
Generalization about being overly generic
The analysis we’ve done has shown that while there were multiple reasons for such a deadly inefficient process, all the reasons which we were able to deduce were related to the single root cause – abstractions and/or concepts which are useful in general but lead to substantial inefficiencies in a certain specific case. Let’s name this phenomenon an ‘Over-Generic Use of Abstractions’, or OGUA. It is important to note that while the primary responsibility for OGUA lies with developer who uses the abstraction without proper applicability analysis, the way abstractions are represented can themselves stimulate their misuse. One common example is when abstraction is represented with an API which simply lacks the functions necessary to avoid being over-generic. Still, we need to mention that the potential of avoiding being over-generic is not an excuse to include ‘each and every function which might be needed by somebody in the future’ into the API, and that the principle of ‘No Bugs’ Axe’ [ NoBugs10 ] should still be observed. In practice this means that by default such functions to avoid being over-generic should not be included into the API, but that whenever a concrete case is demonstrated which shows real benefits which cannot be achieved otherwise, then such functions should be added. Any of items 1–4 above are a very good example of such a concrete case which calls to be fixed (if necessary – by extending APIs of involved abstractions).
Clues in a heap
For a long time I was wondering: what are all the modern browsers doing with memory? If you work with a browser, keeping a few dozens of open tabs for several days, it tends to consume enormous amounts of RAM (a browser taking 1G for two dozens of tabs open is not uncommon, and while I won’t start the speech ‘in our day you could have a full-scale 3D game within 41K’ again [ NoBugs11a ], even these days 1G is still an enormous amount of memory).
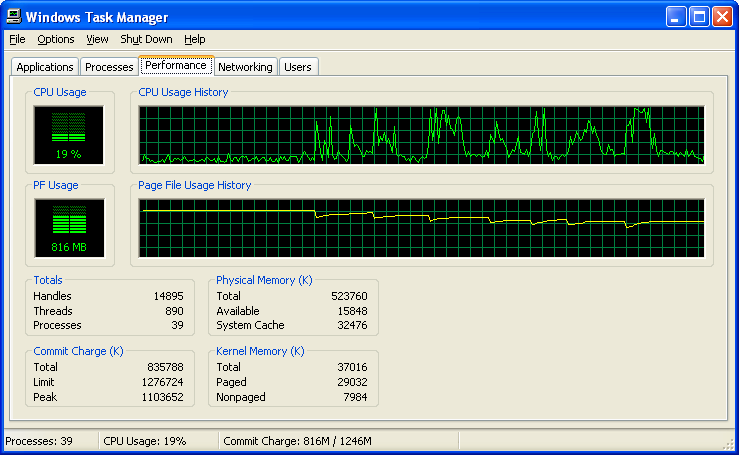
|
| Figure 1 |
Recently I’ve run into an in interesting feature of Internet Explorer (at least IE8) which helps in researching this phenomenon. When you kill the IE process (for example, using Task Manager), Internet Explorer automatically re-launches the process and restores all the tabs you had open to the very same state as they looked before the kill. So, in a few seconds after killing the process we have the very same system, displaying the very same information, as right before killing the process. One should expect that nothing should have changed, right? Wrong – very often the total RAM usage of the system drops and often the difference is pretty large. Let’s take a look at Fig. 1. It shows the total memory usage during the exercise I’ve described above. Originally memory usage was displayed as 1.04G, then we killed the first process, memory usage went down sharply, then was a small rebound (indicating what was really necessary to show this information). Then we killed another IE8 process (by default, IE8 opens one process per several tabs) and so on. As a result we’ve got the system which is showing the very same pages, but using about 200M (!) less RAM. And this isn’t the most impressive case – I’ve seen occurrences when RAM usage has dropped from 1.5G to 800M after such an exercise – still showing the very same pages (note to those who will try to reproduce this effect – for maximum observable results you need to spend a while in IE8, ideally several days, browsing lots of media-rich pages – Yahoo, CNN and similar do just nicely – within the same tabs, leaving the tabs open on the page which interests you).
Our findings indicate an obvious waste of resources, and in the search for a culprit our detective instincts tell us that it should be either memory leaks or a fragmented heap. As the problem of using enormous amounts of RAM is common for all the modern browsers, which use very different engines, it doesn’t look likely that every browser has memory leaks. So, using Holmes’ favorite adage of ‘ Once you eliminated the impossible, whatever remains, however improbable, must be the truth ’, we can point towards heap fragmentation as a most likely suspect.
After faithful Watson takes a look at Holmes’ extensive library of bugs, we find that heap fragmentation is a nasty and way-too-often overlooked effect: when you repeatedly allocate and deallocate memory from the common heap it becomes fragmented with interlaced used and unused blocks, and often a new allocation cannot be satisfied by the heap even if the total free memory is enough: some space is available, but it is just allocated within chunks each of which are not big enough to allocate what we need. Another related, but separate, effect is that, as allocation of memory from the OS for the heap is typically based on CPU pages, it means that to release a page back to OS, all objects on the page must be freed. A typical page size these days is 4K and a typical object size is around 100 bytes, so if, for example, we have allocated 10000 objects and therefore got 256 pages from OS for them, and then we randomly deallocate 9900 of the objects – statistically we’ll get only 173 pages back leaving us with 100 100-byte objects taking 83 pages (332K) – a 3220 % waste!
Now as we’ve identified our suspect, let’s find how he could have do his scary job right under the very noses of Scotland Yard. Once again, it was inspired by an over-generalized abstraction: while the concept of a ‘default heap’ with functions like
malloc()
and
free()
conveniently free the developer from thinking ‘where should this memory go’, it turns out to be a curse in disguise for long-lasting applications which tend to suffer from heap fragmentation. In most cases, to mitigate the effects of heap fragmentation it is necessary to have separate heaps; some modern browsers (notably Chrome and IE) are achieving this by putting different pages into separate processes. This has other positive effects but what is obvious is that whenever a process is killed its heap will be freed with all the accumulated fragmentation. Still, separating processes merely to address heap fragmentation looks like a huge overkill (and a waste of other resources too). A much better way would be to take over control of memory allocation, for example using Boost pool allocators [
Boost
], but applications which do this are very few and far between.
Yet another case against OGUA
Another case which looks bad for the OGUA is the ubiquitous TCP protocol. It provides a nice and neat abstraction of a reliable network stream, and it works. Problems start when one needs to implement an interactive service over TCP, which needs to provide different priorities for different requests. TCP maintains rather large buffers on both sides of connection, and doesn’t support priority itself (in theory, there is such thing as TCP Out-of-band data, but it is well-known to be unreliable in practice, see, for example, [ TCPOOB ]). It means that even if you implement your system with priorities in mind, your users will still be affected by delays introduced by TCP. These delays (unlike, for example, delays in transit) exist not because some law of physics or informatics says that delay is inevitable: this kind of delays is there for only one reason: TCP suffers from OGUA (and this time it is not the fault of developers who’re using it – these days there is simply no way around TCP if you need to transfer data over the Internet, as even if you take big pains to implement your own protocol over UDP it will be blocked in many practically important cases).
Of course, there are ways to bypass these delays (quite a few people have managed to write interactive programs over TCP), but each of these techniques will cause a waste of some other resource. For example, the flag
TCP_NODELAY
is commonly use to mitigate this problem in real-world interactive systems, but will cause excessive network traffic; reducing send/receive windows will reduce throughput; and creating a second TCP connection with smaller send/receive windows will also cause excessive network traffic, not to mention the complexity of dual connections.
Full-scale discussion of TCP and interactivity is very complicated and can easily take the whole article, or even a whole book, but what is already clear is that this is also a case when a nice and neat abstraction (which works in many practical scenarios) causes a waste of resources when it faces certain tasks with specific requirements.
Elementary, my dear Watson!
We have analyzed several significant cases of criminal waste of resources, and have found that despite the resources being very different in each case – from HDD accesses to memory to network traffic – in all of them our main suspect was the over-generalized use of abstractions, the fiendish OGUA. We will see during an upcoming trial if the evidence we have gathered is enough to get a guilty verdict from a jury based on ‘beyond reasonable doubt’, and put this ‘Napolean of Waste’ behind bars for good.

References
[ Adams] http://en.wikipedia.org/wiki/Lapine_language
[Boost] http://www.boost.org/doc/libs/1_46_1/libs/pool/doc/index.html
[Loganberry] David ‘Loganberry’, Frithaes! - an Introduction to Colloquial Lapine!, http://bitsnbobstones.watershipdown.org/lapine/overview.html
[Holmes] http://en.wikipedia.org/wiki/Sherlock_Holmes#Holmesian_deduction
[NoBugs10] ‘From Occam’s Razor to No Bugs’ Axe’, Sergey Ignatchenko, Overload 100, December 2010
[NoBugs11] ‘The Guy We’re All Working For’, Sergey Ignatchenko, Overload 103, June 2011
[NoBugs11a] ‘Overused Code Reuse’, Sergey Ignatchenko, Overload 101, February 2011
[TCPOOB] http://en.wikipedia.org/wiki/Transmission_Control_Protocol#Out_of_band_data
