








Most code bases could have their complexity improved. Alex Yakyma presents a model that suggests how to do this.
The inherent complexity of software design is one of the key bottlenecks affecting speed of development. The time required to implement a new feature, fix defects, or improve system qualities like performance or scalability dramatically depends on how complex the system design is. In this paper we will build a probabilistic model for design complexity and analyze its fundamental properties. In particular we will show the asymmetry of design complexity which implies its high variability. We will explain why this variability is important, and why it can, and must, be efficiently exploited by refactoring techniques to considerably reduce design complexity.
Introduction
There are different views on refactoring in the software industry. Because refactoring is relatively neutral in respect to the choice of software development methodology, teams that practise Scrum or even Waterfall may apply refactoring techniques to their code. There are opinions on refactoring as a form of necessary waste (some authors elaborate on the concept of pure waste vs. necessary waste [ Elsammadisy ] attributing refactoring to necessary waste). This analogy often becomes ironic since many executives and software managers think that refactoring is in fact a pure waste and thus should not be undertaken by teams. At the same time there is the very valid standpoint regarding refactoring as a method of reducing the technical debt [ Cunningham ]. Some consider refactoring as a way of entropy reduction [ Hohmann08 ]. The importance of this team skill on the corporate scale is explained in [ Leffingwell10 ].
In all cases it is obvious that refactoring has to deal with something we call software design complexity – an overall measure of how difficult it is to comprehend and work with a given software system (add new functionality, maintain, fix defects etc.).
Let us start by analyzing complexity more deeply in order to understand how to cope with it.
The hypothesis of multiplicativity
We base our model of software design complexity on its multiplicative nature. Let’s consider a list of factors that influence the complexity. It is not at all a full list and not necessarily in order of importance (applicable to OOP-based technology stack):
|
(1) |
Obviously, some of the factors above are combinations of more specific independent factors. For example, factor #1 is a combination of naming clarity of methods, fields, classes, interfaces, packages, local variables. Factor #2 is also a list of specific factors: whether complicated conditional statements are reasonably decomposed, whether duplicate conditional fragments are reasonably consolidated, whether unnecessary control flags removed etc. It is easy to see that there is fairly large amount of such specific independent factors that determine the complexity.
Let’s see what happens if we have a combination of any two factors. E. g. if we do not follow the single responsibility principle [ WikiSRP ] the code is harder to understand, debug, or maintain because objects of the same class can play considerably divergent roles in different contexts. At the same time not giving meaningful names to classes and their members makes code very hard to comprehend. A combination of these two has a multiplicative effect. To articulate this better let’s use an example.
Assume we have class A with a vague class name and member names. Then the person that debugs the code and encounters objects of this class will have to cope with some complexity C of the class caused by naming problem of this class and its members (for simplicity sake think of C as the effort required to understand what A means in the context of our debugging episode). Let’s now also assume that A fulfils 3 different responsibilities depending on the context. Then in order to understand the behaviour of A in this specific context of debugging you need to analyze what each of the names (class, field or method) would mean in each of the three possible contexts spawned by roles for class A . In other words, the complexity is C ×3.
So we may consider overall complexity C as a product of a large number of individual factors: 1
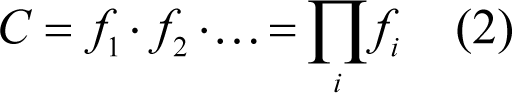
The important characteristic of the factors above is that they are all independent . Taking into consideration the random nature 2 of these factors and assuming their fairly typical properties (more details below) we conclude that:
Assertion 1 : Software design complexity is approximately 3 a lognormaly distributed random variable.
The sidebar contains the proof and is optional for a reader who wants to skip to the conclusions of this assertion.
| Proof of Assertion 1 |
|
Let’s make two assumptions:
With this all said, we may apply Central Limit Theorem (in its version by Lindeberg and Feller [ CLT-L-F ]) to the sequence of random variables ln( f 1 ),ln( f 2 ),… . This gives us:
meaning that the expression on the left of (3) converges to a normally distributed random variable (rv) in distribution (see [ CNVRG ] for more detail). Here
, and
– mean and variance respectively. But this means that the expression on the left in (3) is extremely close to normal distribution for big n . Let’s fix some large integer n . Then remembering that for any positive real numbers a and b ln( a )+ln( b )=ln( ab ) we have:
where α and β are constants (their meaning can be easily derived from (3)) and thus on the right side of (4) we have also a normally distributed variable (≈ d means that distribution functions of rv’s are approximately equal, not the rv’s themselves). This by definition means that C is approximately lognormal for big n . |
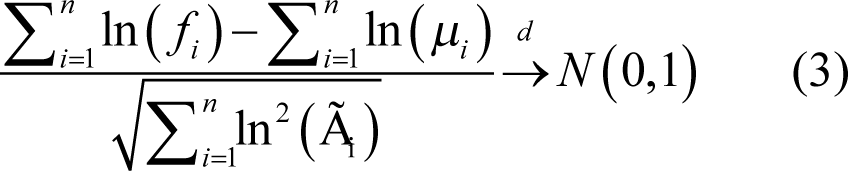
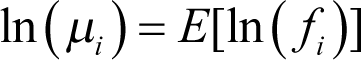
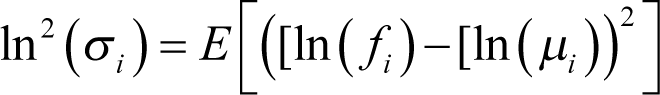
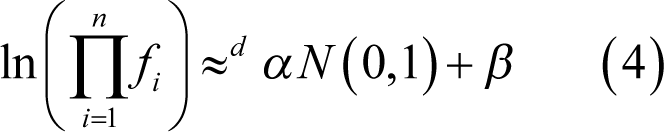
The analytical expression for the probability density function (PDF) 4 of a lognormally distributed random variable can be found in [ Lognorm ] and is not of our current interest. Instead we will be more interested in its generic behaviour.
Finally, the only reason why we needed as set of independent factors in our factorization was to apply the Central Limit Theorem and thus prove that the complexity is a lognormal random variable. In their daily life teams deal with factors which influence each other. That way a team may have a good chance of controlling complexity with a reasonably small effort. The next section includes some examples.
Analyzing the model
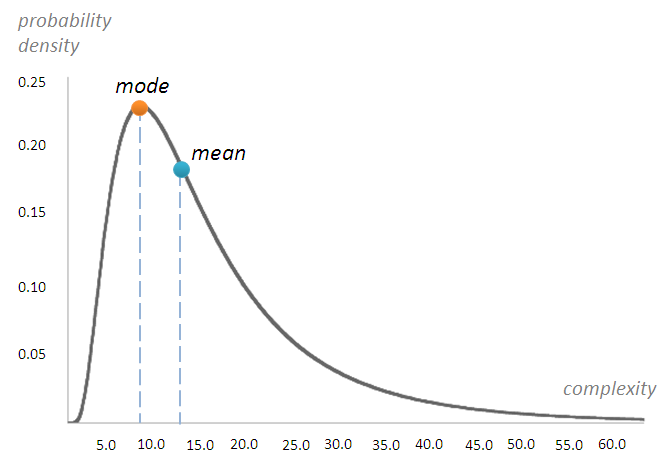
For a given moment of time t 1 the graph of design complexity PDF looks like Figure 1. 5
|
| Figure 1 |
The mode is the most common observation, in other words it will be the most common outcome of a single given development project. The mean would be ‘average’ value if you repeat the ‘experiment’ multiple times (e.g. N teams work on N independent but identical projects). As follows from Figure 1, a lognormal distribution is ‘skewed’. Unlike a normal distribution where mean = mode and the PDF would be symmetrical about the mean value (the well-known bell curve), in case of a lognormal random variable, ‘smaller’ complexities are ‘compressed’ on the left of the mode value while ‘higher’ complexities are scattered wide to the right. Actually we have a ‘long tail’ on the right side of the plot. These considerations imply that the result of a single observation will most likely be misleading. In other words:
Asymmetry of design complexity You are more likely to have a design complexity that is higher than the mode, and less likely to have one that is less than the mode. Occasionally design complexity will have extremely high values.
This fact sounds like a pretty sinister beginning of our journey, but the following two points mitigate the impact:
- High variability of design complexity basically affects those teams that do not purposefully reduce complexity, and…
- There is a reliable method of reducing complexity.
The method used is refactoring . It is easy to see that using our factorization above or similar, it is obvious what needs to be refactored to counter the effect of multiplicativity of design complexity and thus keeping complexity under control.
Note that in the factorization (1) we required that factors were independent. Although it was absolutely necessary for analysis purposes and proving that the complexity follows lognormal distribution, it is not at all required for your own strategy of refactoring. We may securely use ‘overlapping’ refactoring approaches if the team finds that convenient. The example of such dependent factors (and respectively the refactoring techniques) can be: 1) Complex flag-based conditions in loops – the factor, ‘Remove Control Flag’ – the refactoring method (see [ Fowler99 ], p.245) and 2) Unnecessary nested conditional blocks – the factor, ‘Replace Nested Conditional with Guard Clauses’ as a refactoring approach (ib., p.250). Obviously when you reasonably replace nested conditionals with ‘guards’, it will also affect some flag-based loops replacing their complex conditions with return statements where it is appropriate. So 1) and 2) affect each other to a certain extent but it is ok to use both as part of your strategy.
Another example shows that a team may choose additional factor that is not even on the list but which may influence other factors. This, for example, could be ‘keeping methods reasonably compact’. In order to achieve this, the team will optimize flow control structures, data structures, reasonably use inheritance, single responsibility principle, use of framework/lib capabilities instead of own implementations and so on.
In fact refactoring is no less important than the creation of code in the first place. As Martin Fowler points out [ Fowler99, p. 56-57 ]: ‘ Programming is in many ways a conversation with a computer… When I’m studying code I find refactoring leads me to higher levels of understanding that I would otherwise miss. ’
Note that while we are aiming at reducing the complexity we still accept the fact that there is no way to avoid the variability of ‘higher values’ for it is an objective statistical law for this type of rv. In other words there is no way the team could turn a lognormal distribution into a symmetrical one, even though they are the best of developers.
Another important consequence of the design asymmetry for the economy of software engineering is that (because mean ≠ mode ) in the long run there is considerable hidden extra effort in maintaining the product . Indeed the most probable outcome for complexity after one episode of development is by definition equal to the mode . But after being repeated multiple times it gravitates to the mean and we remember mean > mode in the case of lognormal rv. Thus N such episodes yield the additional (and much worse – hidden) maintenance cost proportional to N ×( mean - mode ). This hidden extra effort can never be totally eliminated but can be reduced.
A team that purposefully refactors, either partially or totally, reduces the impact of certain individual complexity factors. The high variability means that you refactoring can dramatically succeed in reducing design complexity.
Refactoring means changes in design. These changes (sometimes dramatically) modify the information flows within the system, re-organizing and re-distributing information in different ways which leads to uncertainty and introduces variability to the outcome. Reinertsen [ Reinertsen09 ] points out the exceptional importance of variability in the economics of product development. In our case the outcome of refactoring is also quantifiable – it is a team’s velocity in delivering user value. While refactoring utilizes the variability, unit testing keeps refactoring within the limits. Unit tests bring considerable certainty to the scene: when you change few lines of code and then make sure your tests still run – this means that system functionality is not or almost not broken at all and changes in design did not lead to a wrong design.
Unit testing and refactoring used in conjunction sustain the balance of variability and help utilize this variability for implementing effective design.
Even though unit testing is an engineering practice that represents huge independent value, it has many important nuances in context of system refactoring applied to reducing the complexity:
- Unit testing should be a continuous effort and go hand-in-hand with refactoring. Changes in code often infer change of method interfaces and logic. So when tests don’t run it may mean two things: 1) that the logic/interface is wrong or 2) code has changed and requires modification to the unit tests as well.
- Unit testing does not constrain all areas of system refactoring. It is impossible to unit-test such things as clarity of naming or whether or not open/close principle is being followed. But even when renaming a method or local variable, tests guard us from breaking the logic.
- Unit testing allows for refactoring at any point in time. We can return to a specific fragment of code after a while and safely refactor it.
- Unit testing and refactoring mutually enable each other. It is very hard to unit-test a jsp page that performs direct calls to a database, handles business logic and prepares results for output. Instead, separation of concerns allows for better testability.
It is important to know that because of the high variability of complexity and the ability of refactoring to dramatically reduce one, refactoring becomes an extremely important competitive advantage of software teams.
Summary
Software design is usually more complex than we may think and factors like long methods or ambiguous names are just a few examples of a long list of forces that dramatically increase the complexity. Although the asymmetry of design complexity means that high complexity is more probable, it also gives teams a clue of how to exploit this asymmetry to reduce it. Continuous purposeful refactoring reduces the complexity at the same dramatic 'rate' and is necessary to sustain software maintainability in the long haul.
References
[CLT-L-F] Central Limit Theorem. http://mathworld.wolfram.com/CentralLimitTheorem.html
[CNVRG] Convergence of random variables. http://en.wikipedia.org/wiki/Convergence_of_random_variables
[Cunningham] Ward Cunningham. Ward Explains Debt Metaphor. http://c2.com/cgi/wiki?WardExplainsDebtMetaphor
[Elsammadisy] Amr Elsammadisy. Opinion: Refactoring is a Necessary Waste. http://www.infoq.com/news/2007/12/refactoring-is-waste
[Fowler99] Fowler, Martin. Refactoring: Improving the Design of Existing Code , Addison-Wesley 1999
[Hohmann08] Luke Hohmann. Beyond software architecture: creating and sustaining winning solutions , p. 14, Addison-Wesley 2008.
[L-Cond] Lindeberg’s condition. http://en.wikipedia.org/wiki/Lindeberg%27s_condition
[Leffingwell10] Dean Leffingwell. Agile Software Requirements: Lean Requirements Practices for Teams, Programs, and the Enterprise , ch. 20 Addison-Wesley 2010.
[Lognorm] Lognormal distribution http://en.wikipedia.org/wiki/Log-normal_distribution
[Reinertsen09] Reinertsen, Donald. The Principles of Product Development Flow: Second Generation Lean Product Development , Celeritas Publishing 2009
[WikiSRP] Single responsibility principle. http://en.wikipedia.org/wiki/Single_responsibility_principle
- It is important to note that our model describes random behaviour of complexity at any arbitrary ( but fixed ) moment in time. In other words our model answers the following type of questions: what could be the design complexity of a product after the team works on it for, say, 2 months.
- When we say that the complexity (or one of its components) is random, we mean that if we work on project X within a certain timeframe, the resulting codebase (as an ‘evolving system’) may end up in any one of a number of different possible states, each with a different level of design complexity.
- ‘Approximately’ means that if for a second we assume that there is not just ‘large’ but an infinite number of factors in (1) then expression (2) can be ‘reduced’ to C n – a product of the first n factors. Our assertion basically states that the distribution of C n tends towards lognormal as n → ∞.
- PDF – Probability Density Function of a continuous random variable is a function that describes the relative likelihood for this random variable to occur at a given point.
- To better understand how the PDF changes with time: if t 1 < t 2 then obviously the complexity at the moment t 2 is also lognormal but its graph is more ‘stretched’ lengthwise along the horizontal axis so that in particular its ‘peak’ is further to the right. This is more exact statement that the complexity tends to grow over time as development progresses. Though note that the dynamic analysis of design complexity is beyond the scope of this paper.
