








Futurology has a dismal track record. Ric Parkin looks at the history of technology predictions.
Prediction is very difficult, especially about the future.
This such a great quote, and yet its providence is uncertain – possible coiners include Mark Twain, Yogi Berra, or Niels Bohr. Whoever actually said it, I do think it it holds a deep truth – we just don’t know what’s going to happen. It also captures a healthy humility that even if we use our knowledge and expertise to make as good a prediction as we can, reality has an almost perverse delight in proving us wrong, just to keep our hubris in check.
Examples abound in several fields: politics is a fine example – partly because at its core, people are interviewed at short notice on fast moving situations they have limited information on, and yet they feel they have to sound authoritative. A great recipe for putting your foot in it and getting things completely wrong.
And technology has an equally rich seam of such faux pas. I’d like to present a few, give their historical background (or lack of), and consider their deeper truth.
Everything that can be invented has been invented.
~ Charles H. Duell,Commissioner US Patent Office
This is trotted out to mock the idea that people think science and society have reached a pinnacle, and there’s nothing new to know. Unfortunately this quote appears to be a complete fabrication. There’s a similar example from the late 1800s about all of physics being within their grasp, just as Quantum Mechanics and Relativity burst upon the scene. This too is most likely an exaggeration, as the problems that led to those breakthroughs were well known.
The goose that laid the golden eggs, but never cackled
~ Churchill
This one is true, although is more of a description than a prediction. This is how Churchill described the Bletchley Park codebreakers, and sums up both of their great achievements – how they achieved the amazing and broke the codes, and yet despite the industrial scale of the work there, the secret was kept until the 70s – probably much longer than even Churchill could have imagined. An example of how useful it was turned up this week, involving the decrypted cables that showed that the Germans had fallen for the D-day bluffs [ Fooled ]. Just knowing the deception was working allowed the invasion to go ahead with greater confidence and far less loss of life. Golden eggs indeed.
I think there is a world market for maybe five computers
~ Thomas John Watson, President of IBM
Again there is no evidence that he actually said it, although interestingly, if he had he’d have been right for around a decade! Recall that until the 70s, computers were huge, expensive machines that relatively few companies could afford, let alone individuals, generally used for quite specialised tasks – calculations for nuclear weapons research, some scientific modelling, and eventually business tasks [ LEO ] so it was not actually that ludicrous a prediction, until the cost dropped to the point where computers could become ubiquitous, and started to be used for things that couldn’t even be imagined back then – think of the advent of computer graphics, and wireless networking. This illustrates that our predictions are shaped by what we know at the time, and that our ideas about what is possible are going to be limited by that.
640K ought to be enough for anybody
~ Bill Gates
Again this doesn’t appear to have been uttered. But I think the reason we’d like it to be true is because that 640K limit caused so much pain over the years, and people want somebody to blame (and feeling superior to the wildly successful Gates is a bonus). While the jump from 64K or so of memory to 640K in the IBM PC must have seemed like a big leap, an increase of x10 would not last long in the face of ever more inventive tasks for computers to do, and even the first PCs shipped with a large fraction of this limit, so Moore’s Law would allow the limit to be reached within a year or two. Getting around this limit did support a small industry of companies inventing various tricks to increase the usable memory though. One clever ruse I remember was the use of extended memory, where blocks of memory could be mapped in and out of that usable 640K – known as conventional memory [
Conventional
] – via sophisticated ‘pointers’. One interesting consequence of this was that a
segment:offset
‘pointer’ might not be valid and cause a hardware fault if you tried to load it into the appropriate registers. Note that you didn’t even have to dereference the pointer, just load an invalid segment value into the segment register. See for example [
MIT
]. This is one example of why in C and C++ even looking at an invalid pointer value is Undefined Behaviour. Many people still think that you have to dereference it to trigger UB, but this example shows you don’t even need to go that far. One consequence was that you had to be careful with pointer arithmetic so that intermediate values were valid, and avoid falling off the end of an array.
Even when 32-bit flat addressing relieved us from that particular problem, it wasn’t to last – fairly recently memory has got cheap enough that you can install more than a 32-bit pointer can address (in practice, operating system limitations have made the limit even lower, so for example 32-bit Windows can only use a maximum of 3GB). Are we in for another round of painful segmented pointer pain? Thankfully not – chips and operating systems have been developed for years to be able to use 64-bit pointers which can use much more memory with emulators to run legacy 32-bit programs, so the transition should be much smoother. Still, 64bit pointers are twice as large so there are potential data size and storage issues too. Even in this day and age, it’s worth being mindful of storage and communication size – a reason that the complex UTF-8 character encoding is commonly used even though the UTF-32 format is much simpler to program with.
One lesson to be learned from these examples is that decisions on the representation of things can have long term consequences, and can cause a lot of pain and effort to fix or transition to the next stage. Even good choices at the time can eventually become a problem. Consider for example, the Y2K problem – a space saving representation of two digit years was a good choice back in the 60s and 70s, but the code and data persisted for longer than anyone really expected, and a lot of time and effort was expended to fix the problem – rather successfully I might add, although that did lead to wild accusations that it was never really a problem. The unix 2038 problem is similar but has been spotted a long way in advance, so solutions are already in progress to avoid many of the problems [ 2038 ].
A current problem is just hitting now though – the central internet address system is about to hand out the last blocks of IP numbers to the regional authorities [ APNIC ]. They in turn will continue to issue addresses until they run out, with estimates of when this will happen being as close as September of this year. See figure 1 for a graph showing the unassigned addresses and figure 2 for assignment rates (note how the number being assigned have shot up recently – looking carefully this looks likely to be due to a combination of the surge in popularity of internet enabled smartphones in North America and Europe, and growth in demand in the Asia-Pacific region).
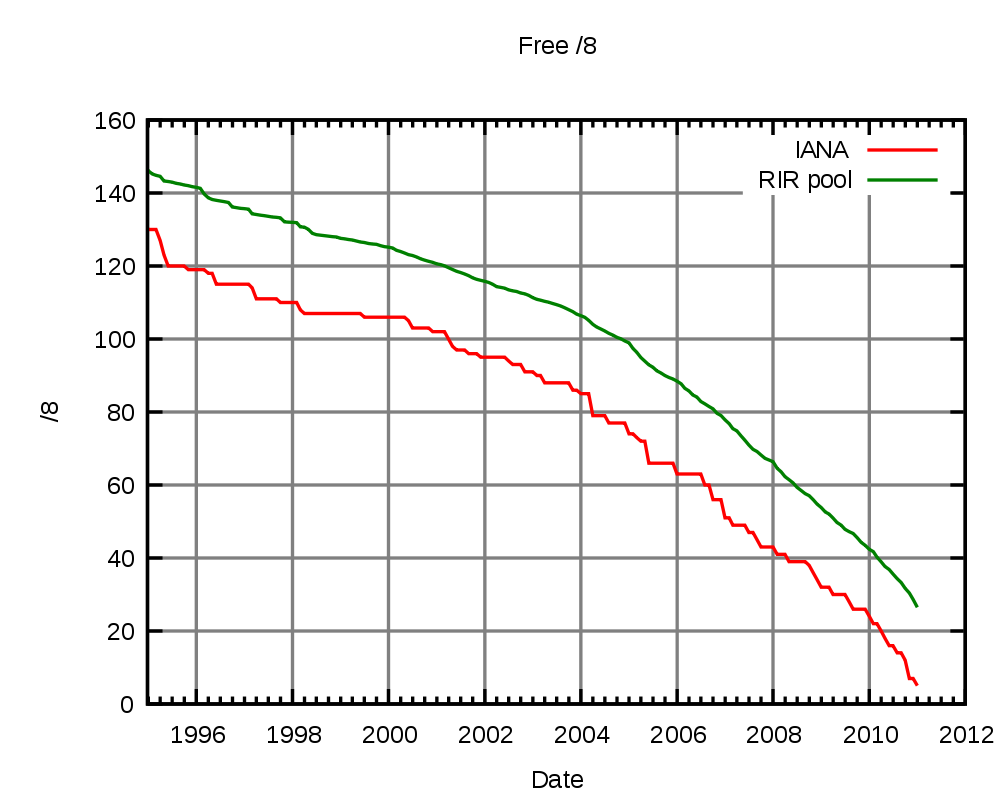
Reproduced under the Creative Commons Licence, originally created by http://commons.wikimedia.org/wiki/User:Mro |
| Figure 1 |
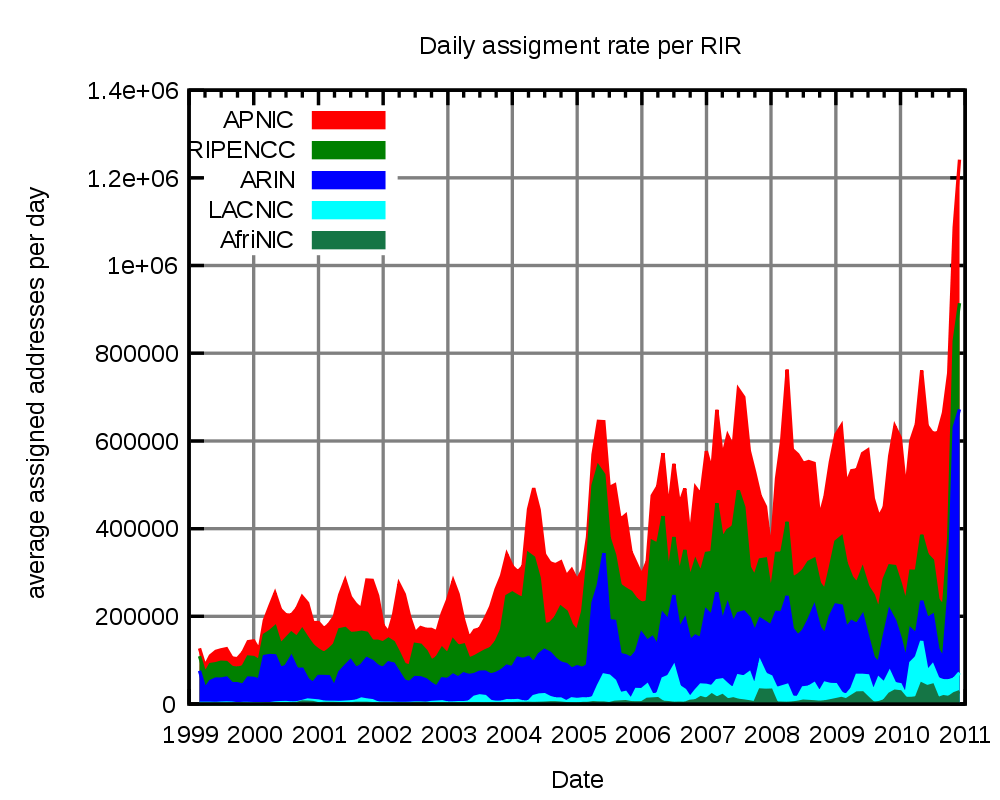
Reproduced under the Creative Commons Licence, originally created by http://commons.wikimedia.org/wiki/User:Mro |
| Figure 2 |
However, this problem has been anticipated and some systems are already starting to use the next version [ IPv6 ] which will have room for vastly more addresses (2128 as opposed to IPv4’s 232). There are concerns that this is not happening fast enough, with many people not even realising they may need to do something. It’s not totally clear to me what sort of problems could be expected – there are several proposed strategies that could be used as the final numbers are allocated, perhaps by reallocating no longer used blocks – but it might become more difficult to get addresses for new businesses from providers that are not IPv6 ready. But I doubt that the internet will break – there are much easier ways of doing that [ ITCrowd ].
References
[2038] http://en.wikipedia.org/wiki/Year_2038_problem
[APNIC] https://www.apnic.net/publications/news/2011/delegation
[Conventional] http://en.wikipedia.org/wiki/Conventional_memory
[Fooled] http://www.bbc.co.uk/news/magazine-12266109
[IPv6 ] http://en.wikipedia.org/wiki/IPv6
[ITCrowd] http://www.youtube.com/watch?v=wrQUWUfmR_I
[LEO] http://en.wikipedia.org/wiki/LEO_%28computer%29
[MIT] http://pdos.csail.mit.edu/6.828/2006/readings/i386/s06_03.htm
