








Sometimes you really do have to optimize your code. Björn Fahller looks at a string lookup data structure.
Ah, summer vacation. Time to toy with ideas that have grown over the year. This summer's project was performance tuning a Trie [ TRIE ]. Tries are fascinating, while special. They can be used as sets, or by storing values in data nodes, as maps. In a Trie, data is stored in a tree-like structure, where each node holds a part of the key.
Tries are primarily useful if the key is a string, although variants have been successfully used for other purposes, such as storing routing information. While a string is a special case for a key type, it's a frequently used special case, so its utility value should not be underestimated.
The original Trie data structure uses one node for each key character, whereas this variant stores common sub-strings and thus reminds a lot of a HAT-trie [ HAT ].
So what is a Trie?
Figure 1 shows a Trie with the strings "category" and "catastrophe". Here rectangular nodes denote stored keys and oval nodes are internal 'stepping stones' on the way to key nodes. This means that all leaf nodes are keys, and non-leaf nodes may be keys or internal. Adding more strings can change the structure in three ways.
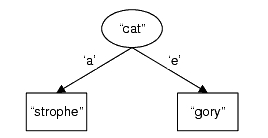
|
| Figure 1 |
Adding the string "cat" is trivial - it merely changes the mode of a node from internal to key, as figure 2 shows.
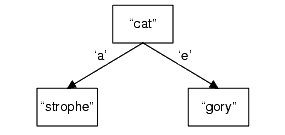
|
| Figure 2 |
When the word "cathedral" is added, another child is added to "cat", with 'h' as a new distinguishing character, which figure 3 shows.
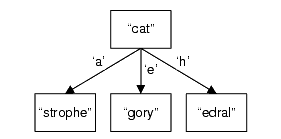
|
| Figure 3 |
Inserting the word "catatonic" requires more work. The "catastrophe" node must be split into two nodes, one with an empty internal prefix on 'a' as distinguishing character and, as its child, a node with the suffix "trophe" after 's' as distinguishing character. Then a new node can be created, using 't' as the distinguishing character, and "onic" as suffix. Figure 4 shows the result.
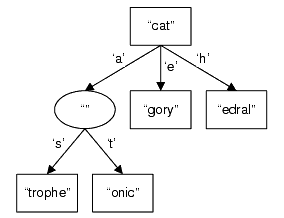
|
| Figure 4 |
This brief introduction already hints at a number of characteristics of the data structure.
- It can be lean on memory if the keys often share common prefixes (e.g. URLs and fully qualified file names)
- It probably does not work very well for short keys with great variability (e.g. random 32-bit integers)
- It has the potential for being fast for long keys, since it only needs to read the key once per lookup operation (compared to at least twice for a hash-table).
- The performance of all operations are limited by search performance.
- Longest matching prefix searches are very efficient.
The general idea is that string retrieval time is linear with the key length. This, however, is only true if all accesses have equal cost, but comparing strings requires less computation than jumping between nodes, and the latter is also more likely to suffer from cache misses. So, in the real world, the performance of lookups is limited by the height of the structure, which is typically a logarithm of the number of strings stored.
Tuning in general
Measuring performance on a modern computer can be frustrating. Several levels of caches and a multi-core CPU governed by a preemptive operating system that flushes said caches provide very chaotic timing. It has even been suggested that it is truly random [ random ]. Even runs with many million searches taking more than 10 minutes will differ by several percent with identical data on a seemingly otherwise idle system.
On Linux for x86/32 and x86/64 there's an invaluable aid in 'valgrind' [valgrind] and its tools 'cachegrind' and 'callgrind'. Most Linux developers know 'valgrind' as a tool for hunting down memory related bugs. The tools 'cachegrind' and 'callgrind' both run your code in a virtual machine which can model your cache. With 'cachegrind' you can see the exact number of instructions used, the number of read and write accesses and number of misses for all cache levels. It often helps to see if your change was an improvement or not, even for reasonably short runs. There are situations when it's difficult to judge, though. Such an example is when the number of instructions increased slightly, but the number of level-1 cache misses decreased slightly. The tool 'callgrind' can be used to visualize details of execution. For example it can show, per code line, or even per CPU instruction, an estimate of cycles consumed, the number of read/write accesses and number of read/write cache misses per level. Unfortunately it is not cycle-accurate, so timing information must be taken with a grain of salt. The result from 'callgrind' is difficult to make sense of when aggressive optimizations are used by the compiler, since it can be difficult to map an instruction to a statement in your code. Fortunately, using less aggressive optimizations rarely change the data access pattern so 'callgrind' can help a lot in pinpointing not only where you have a performance bottleneck, but also why.
Test data and methodology
In order to measure the performance of the implementation representative data must be used. I have used three sources of strings. A number of e-books were downloaded from Project-Gutenberg [ gutenberg ]. UTF-8 was preferred when available. The majority of books downloaded are written in English, but there's also a fair mix of French, German, Dutch, Italian, Finnish, Swedish and one example of Greek. From those e-books, 2,408,716 unique sentences and 2,063,856 unique words were extracted (very naïvely, just using operator>> for std::string ). Also a snapshot of the file system of a server machine gave 1,907,803 unique fully qualified filenames.
Only search time is measured, since insertion and deletion will be dominated by search when the structure becomes large.
When producing graphs, several runs are made. 5 sets of 1,000,000 unique words, sentences, and file names (obviously with an overlap between the sets) are used. Each set is used for searches when populating from 2 to 1,000,000 unique keys. Every sequence is run 3 times to reduce the randomness introduced by the OS flushing caches when scheduling other processes. The amount of data allocated for the structure is also measured. For the latter it is interesting to know that the average length of words is 9.5 characters, sentences 135 characters, and filenames 105 characters.
The chosen collection for performance measurements is a set. Extending to map, multiset and multimap is trivial. In order to save print real-estate, code samples only include the functions that are necessary to understand lookup and optimizations.
The host used for all performance measurements is an Intel Q6600@2.4GHz Quad Core CPU running 64-bit Linux. All test programs are compiled as 32-bit programs.
The hope is to beat std::unordered_set<std::string> , which is a hash-table, on both lookup performance and memory usage.
First attempt
struct child_node;
struct node
{
virtual child_node* get_child() { return 0; }
virtual ~node() { }
};
struct child_node : node {
virtual child_node *get_child()
{ return this; }
union char_array
{
char chars[sizeof(char*)];
char *charv;
};
char_array select_set;
unsigned short num_chars;
unsigned short prefix_len;
char_array prefix;
std::vector<node*> children;
const char *get_prefix() const {
return prefix_len > sizeof(char_array)
? prefix.charv
: prefix.chars;
}
const char *get_select_set() const {
return num_chars > sizeof(char_array)
? select_set.charv
: select_set.chars;
}
};
struct leaf_node : public node
{
};
const node* get(const child_node *n,
const char *p, size_t len)
{
for (;;)
{
if (len < n->prefix_len)
return 0;
const char *t = n->get_prefix();
if (std::strncmp(p, t, n->prefix_len))
return 0;
p+= n->prefix_len;
len -= n->prefix_len;
if (!len)
return n->children.size()
? n->children[0] : 0;
const char *v = n->get_select_set();
const char *f = std::lower_bound(
v, v + n->num_chars, *p);
if (f == v + n->num_chars || *f != *p)
return 0;
++p;
--len;
node *next = n->children[f - v + 1];
n = next->get_child();
}
}
|
| Listing 1 |
The ideas behind this less than obvious implementation (see Listing 1) are:
- To save memory, and thus increase locality, nodes are made small. Leaves must be special, hence the inheritance.
- Nodes with children allocate each child node on the heap, and store the pointer in the vector children, sorted on the distinguishing character to allow a binary search. The theory is that the number of children will typically be very small.
- A node that has a key stores a leaf_node in children[0] , hence n->children[f-v+1] in get() . When implementing a map, the leaf_node instance will hold the data.
- To avoid having to lookup the children when searching, the distinguishing character is stored in a separate char_array , and is excluded from the child's prefix, as was shown in the introductory example. This avoids holes in the vector, saving memory, but makes lookup logic more complex.
- char_array stores short strings locally, and uses a pointer causing indirection only when they are long. This has proven to be a useful optimization in other experiments, so it is used right away.
- num_chars refers to the number of chars in select_set
- prefix_len refers to the length of prefix
Figure 5 mercilessly shows that the result was less than impressive. It's faster than a hash-table for long strings, providing there aren't too many of them. Short string performance is terrible. Not only was insertion very difficult to get right when having to keep the select_set and children vectors in sync, 'callgrind' also pinpointed the binary search as a major lookup performance killer. It wasn't even lean on memory, only barely beating the hash table for large amounts of filenames.
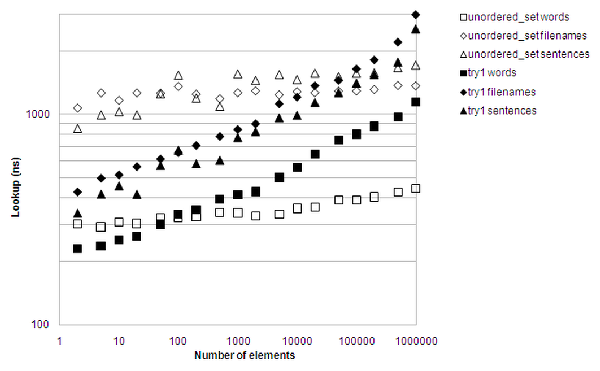
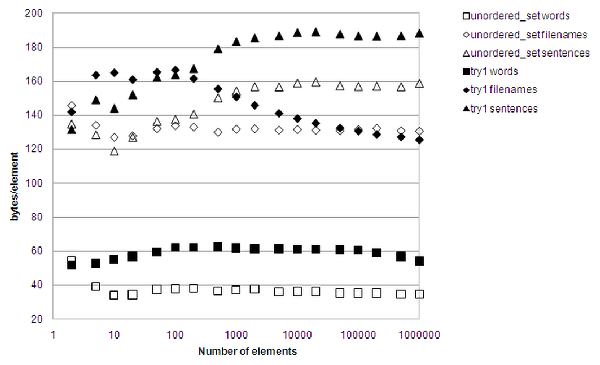
|
| Figure 5 |
Second attempt
Binary searching was a time waster that must be gotten rid of. This time the vector will have indices 0-255, casting the characters to unsigned char to use directly as index. This wastes vector space, since there will be plenty of holes with 0-pointers, but it should be fast. The inheritance structure is also changed such that the dynamic dispatch will only be required when checking if the terminal node reached is indeed a data node holding a stored key, or if it's an internal node. One dynamic dispatch per lookup, instead of one per traversed node, should make a difference. (See Listing 2.)
struct data_node;
struct node
{
virtual const data_node *get_data_node() const
{ return 0; }
union char_array
{
char chars[sizeof(char*)];
char *charv;
};
unsigned short prefix_len;
char_array prefix;
std::vector<node*> children;
const char *get_prefix() const;
};
struct data_node : public node
{
virtual const data_node *get_data_node() const
{ return this; }
};
const data_node *get(const node *n,
const char *p, size_t len)
{
for (;;)
{
if (!n) return 0;
if (len < n->prefix_len) return 0;
const char *t = n->get_prefix();
if (std::strncmp(p, t, n->prefix_len))
return 0;
p += n->prefix_len;
len -= n->prefix_len;
if (len == 0) return n->get_data_node();
unsigned char idx = *p;
if (idx => n->children.size()) return 0;
++p;
--len;
n = n->children[idx];
}
}
|
| Listing 2 |
Insertion logic was much simplified by this change, since there was no longer any need to shuffle nodes around. Lookup logic is also simple. The distinguishing character is not stored, since it is used as the index into children when looking up the next node, hence saving a byte of prefix for each node. Also, getting rid of select_set makes the struct 4 bytes shorter on a 32-bit system, probably increasing locality a bit.
There is a considerable lookup performance increase, as figure 6 shows. The improvement is especially noticeable for short strings. For long strings the improvements are not as huge. Huge, however, is exactly what the memory requirements are. Time to rethink again.
|
| Figure 6 |
Third attempt
Something must absolutely be done about the memory consumption. One obvious way is to use an offset for the vector, so that lookup(i) is vector[i - offset] , provided that i is within the legal range. This should reduce the memory consumption a lot without requiring expensive computations. (See Listing 3.)
struct node;
struct nodev
{
std::vector<node*> vec;
unsigned char offset;
const node* operator[](unsigned char i) const;
};
struct data_node;
struct node
{
virtual const data_node *get_data_node() const
{ return 0; }
union char_array
{
char chars[sizeof(char*)];
char *charv;
};
unsigned short prefix_len;
char_array prefix;
nodev children;
const char *get_prefix() const;
};
const node * nodev::operator[](
unsigned char i) const
{
if (vec.size() == 0) return 0;
if (i < offset) return 0;
if (size_t(i - offset) >= vec.size()) return 0;
return vec[i - offset];
}
const data_node *get(const node *n,
const char *p, size_t len)
{
for (;;)
{
if (!n) return 0;
if (len < n->prefix_len) return 0;
const char *t = n->get_prefix();
if (std::strncmp(p, t, n->prefix_len))
return 0;
p+= n->prefix_len;
len-= n->prefix_len;
if (len == 0) return n->get_data_node();
unsigned char *idx = *p++;
--len;
n = n->children[idx];
}
}
|
| Listing 3 |
While the lookup requires extra computation, if ever so little, the reduced memory waste should increase the likelihood of cache hits and thus boost performance.
The results are mixed, as figure 7 shows. With respect to performance, there is actually a slight regression, but memory consumption is way down.
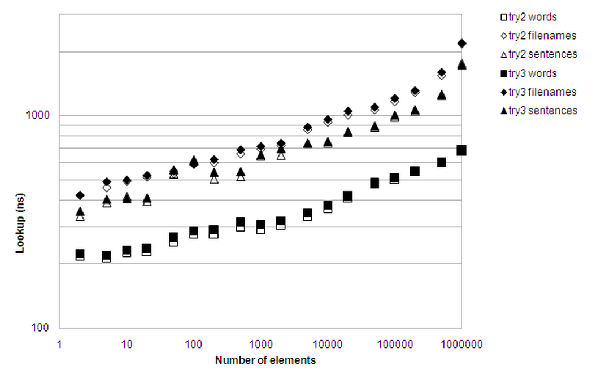
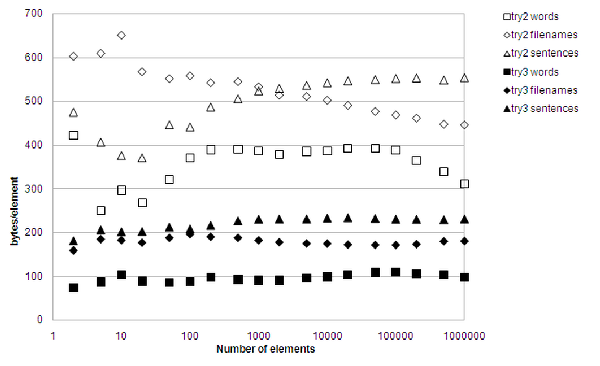
|
| Figure 7 |
According to 'callgrind', the obvious time waster for lookups is nodev::operator[]() const , which spends 42% of its time for the vector indexing, and the rest checking the conditions. Time for thoughts...
Fourth attempt
Using a std::vector<> for the child nodes wastes space. Both the length and offset for the child vector can be stored as unsigned char , which reduces the node size a bit. This leaves an empty hole in the memory layout for the node, which is a waste. Better use it for the inlined prefix by packing the union. The special case that a node has only one child can be taken care of by a direct pointer to it, saving an indirection and thus increasing the chance of a cache hit. The range check for indexing children can be made more efficient by using wrap-around on unsigned integer arithmetics. (See Listing 4.)
struct data_node;
struct node
{
virtual const data_node *get_data_node() const
{ return 0; }
const node* at(unsigned char i) const;
union __attribute__((packed)) char_array
{
char chars[sizeof(char*)+2];
char *charv;
};
char_array prefix;
unsigned char offset;
unsigned char size;
unsigned prefix_len;
union {
node* nodep;
node** nodepv;
};
const char *get_prefix() const;
};
const node *node::at(unsigned char i) const
{
unsigned char idx = i - offset;
if (idx < size) return size == 1
? nodep : nodepv[idx];
return 0;
}
data_node *get(const node *n, const char *p,
size_t len)
{
size_t pl;
while (n != 0 && (pl = n->prefix_len) <= len)
{
const char *t = n->get_prefix();
const char *end = t + pl;
for (const char *it = t; it != end;
++it, ++p)
{
if (*p != *it) return 0;
}
len-= pl;
if (len == 0) return n->get_data_node();
--len;
n = n->at(*p++);
}
return 0;
}
|
| Listing 4 |
Finally some real progress. Figure 8 shows the difference compared to the third attempt. The memory consumption is substantially lower, and lookup times have been reduced by around 15% across the board. The 'valgrind' tools aren't of much help in pinpointing current time consumers, but there is no doubt that there are a lot of cache misses. Hmmm...
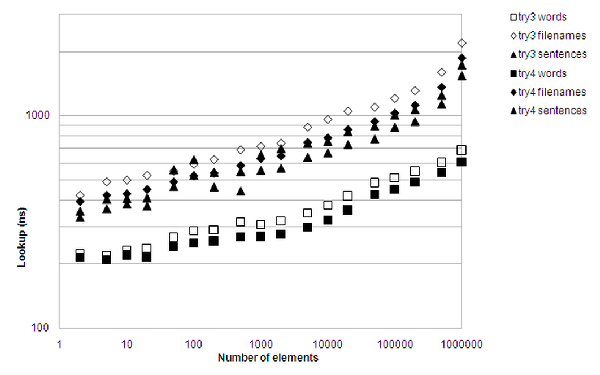
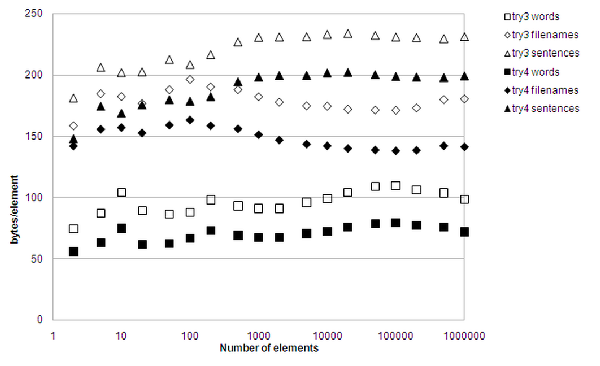
|
| Figure 8 |
Fifth attempt
Perhaps memory consumption can be reduced by using a simple hash table for the children, instead of direct indexing. It should be possible to reduce the number of unused entries a lot. Since using a hash table may cause several distinguishing characters to reach the same entry, the distinguishing character needs to be stored in the prefix. Fortunately there is no longer any need for the offset member, so the inlined prefix member can grow by one char without growing the node size. To make lookup simple, the hash implementation chosen is just a remainder-operation on the size, and only collision free sizes are allowed. This trivially reaches a maximum size of 256 entries, where it becomes direct indexing. By getting rid of inheritance, and just steal a bit from the prefix_len member to tell if the node holds data or not, the struct can be further reduced in size, which should increase locality. Limiting the prefix length to 231 characters is unlikely to be a real problem (Listing 5).
struct node
{
const node *get_data_node() const {
return data ? this : 0; }
node* at(unsigned char i) const;
union __attribute__((packed)) char_array
{
unsigned char chars[sizeof(char*)+3];
unsigned char *charv;
};
char_array prefix;
unsigned char size;
unsigned prefix_len:31;
unsigned data:1;
union {
node* nodep;
node** nodepv;
};
const unsigned char *get_prefix() const;
};
const node *node::at(unsigned char i) const
{
if (size <= 1) return nodep;
unsigned char idx = i % (size + 1U);
return nodepv[idx];
}
const node *get(const node *n, const char *p,
size_t len)
{
unsigned pl;
while (n != 0 && (pl = n->prefix_len) <= len)
{
const unsigned char *t = n->get_prefix();
const unsigned char *end = t + pl;
for (const unsigned char *it = t;
it != end; ++it,++p)
{
if ((unsigned char)*p != *it) return 0;
}
len-= pl;
if (len == 0) return n->get_data_node();
n = n->at(*p);
}
return 0;
}
|
| Listing 5 |
Performance regression, bummer. Figure 9 shows that lookup times are slightly longer again.
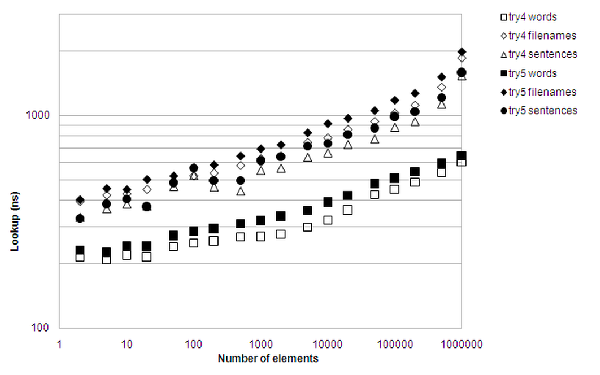
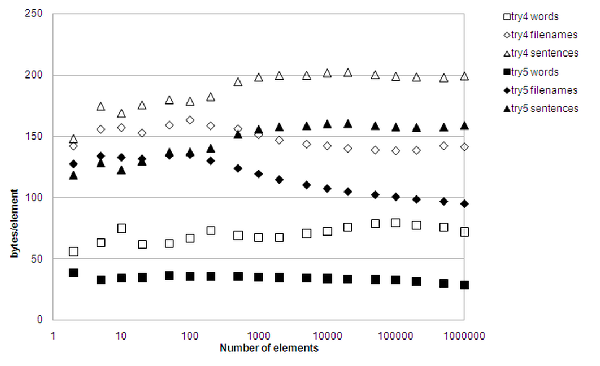
|
| Figure 9 |
Look at the memory consumption, though, especially for file names. The average file name is 109 bytes long, yet the average amount of memory consumed per stored file name is only 94.8 bytes for 1,000,000 file names. The size of the entire searchable data structure is, in other words, smaller than the size of its contained data. That's quite impressive.
It appears like the reduction in memory consumption went according to plan, without buying anything back in terms of fewer cache misses. This calls for a more detailed study of where the cache misses are.
Surprisingly, Table 1 (a comparison of cache misses in attempts 4 and 5 with 10,000,000 lookups in 100,000 words) shows that the cache miss pattern has changed, but the sum is almost identical. It appears that whenever there is a cache miss in n->at() , i.e. in obtaining nodepv[idx] , there is also a cache miss in dereferencing the returned pointer. The reduction in cache misses for n->at() in attempt 5 is likely to be due to increased locality, but accessing *nodepv[idx] is seemingly no more likely to be a cache hit than in attempt 4. The considerable rise in cache misses for prefix comparison is a mystery, though.
|
|||||||||||||||||||||||||||||||||||
| Table 1 | |||||||||||||||||||||||||||||||||||
Most probably the difference in performance is mainly because calculating the remainder of an integer division is a slightly expensive operation. This is not shown in 'callgrind', though, but remember that its idea of time per instruction is not cycle-accurate.
Sixth attempt
When nodepv[idx] is a cache miss, a lot of data is read that isn't needed, since a pointer is much shorter than a cache line. The cache lines on the Q6600 CPU are 64 bytes wide. Whenever nodepv[idx] is a cache miss, 64 bytes are read from the level-2 cache (or worse, from physical memory.) Of those 64 bytes, only 4 are used in 32-bit mode, since a pointer is 4-bytes long. With luck, another lookup will soon refer to a pointer within those 64-bytes, but chances are the line will be evicted for another read before that happens.
Using an array of nodes, instead of an array of pointers to nodes, may waste a lot of memory, but it should save on cache misses. Also, when there is a cache miss, a large part of what is read into the cache line is more likely to be the data in the node struct, which will be used very soon indeed.
It is not obvious that an array of nodes wastes space, though. A counter example is a completely filled array, where the indirection leads to the whole array itself being wasted space, in addition to requiring an unnecessary indirection.
With the above in mind, it is worth staying with the same hash function and see if the expected reduction in cache misses are there and what performance boost it gives. The mystery with increased cache misses for prefix comparison is ignored for the moment. (See Listing 6.)
struct node
{
const node *get_data_node() const {
return data ? this : 0; }
const node* at(unsigned char i) const;
const unsigned char *get_prefix() const;
union __attribute__((packed)) char_array
{
unsigned char chars[2*sizeof(char*)-
sizeof(uint32_t)];
unsigned char *charv;
};
char_array prefix;
uint32_t prefix_len:23;
uint32_t data:1;
uint32_t size:8;
node *nodep;
};
const node *node::at(unsigned char i) const
{
unsigned char idx = i % (size + 1U);
return nodep + idx;
}
const node *get(const node *n, const char *p,
size_t len)
{
// same as in fifth attempt
}
|
| Listing 6 |
The lookup hash function remains the same as before. The trick with the char_array union is just to better use the memory when compiling in 64-bit mode. Having further reduced prefix_len to 23 bits is getting to the territory where it, at least in theory, may become a problem. However, the problem is not difficult to overcome - just split the prefix into separate nodes every 8,388,607 characters. I doubt the split will be noticeable in performance.
Figure 10 says it all. Good. Very good. The curve is flatter. The performance increase is impressive, especially for large collections, and surprisingly the memory consumption is actually down a little bit.
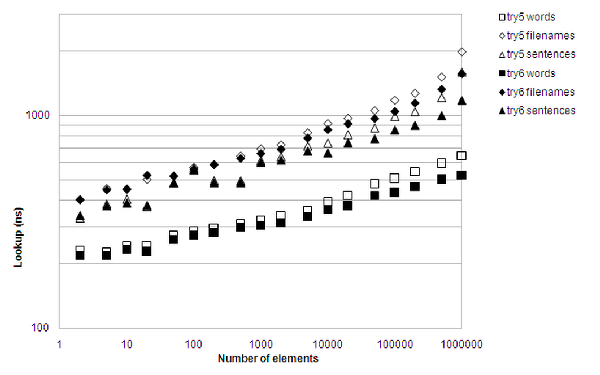
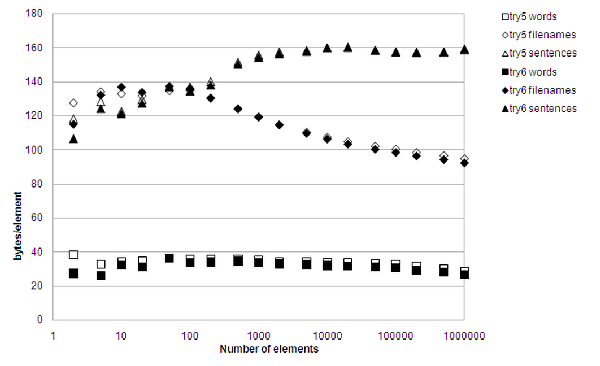
|
| Figure 10 |
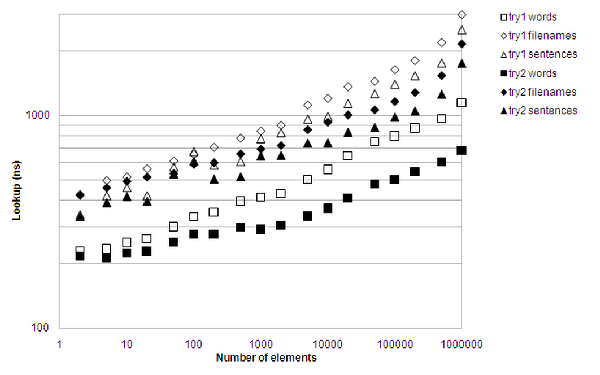
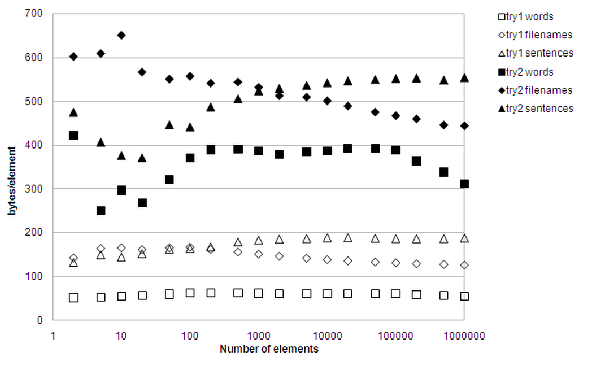
It now comes out favorably both on lookup performance and memory consumption for most situations when compared with std::unordered_set<std::string> , as figure 11 shows.
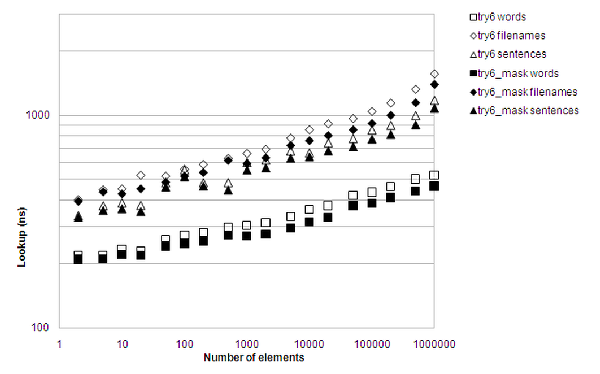
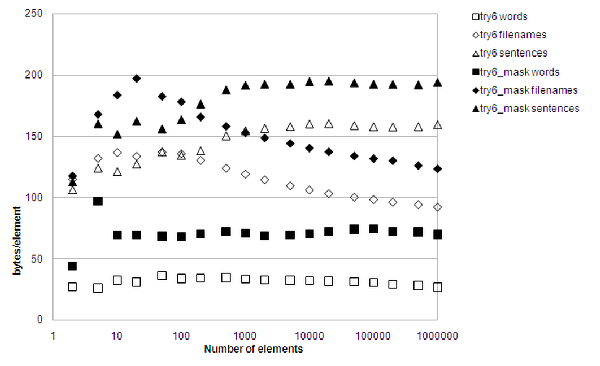
|
| Figure 11 |
Table 2 (a comparison of cache misses in attempts 5 and 6 with 10,000,000 lookups in 100,000 words) shows a comparison of the cache-miss pattern between attempts 5 and 6. As can be seen, the theory of wasted reads seems to have been correct, since the total number of cache misses are down by 40%, since the misses in the at() function nearly vanished.
|
|||||||||||||||||||||||||||||||||||
| Table 2 | |||||||||||||||||||||||||||||||||||
Now 'callgrind' pinpoints the calculation of i % (size + 1U) in at() as the single most expensive operation in the lookup path. Just out of curiosity, a bit-mask operation must be tried instead. The only code change visible in the lookup path is changing the at() function to calculate idx = i & size , where size is always 2 x -1. Obviously memory consumption will increase severely, but a bit mask operation is much faster than a remainder operation, so lookup times may be considerably reduced.
Woohoo! Illustration 12 gives the proof. Now this is fast, but undoubtedly the memory requirement is rather on the obese side.
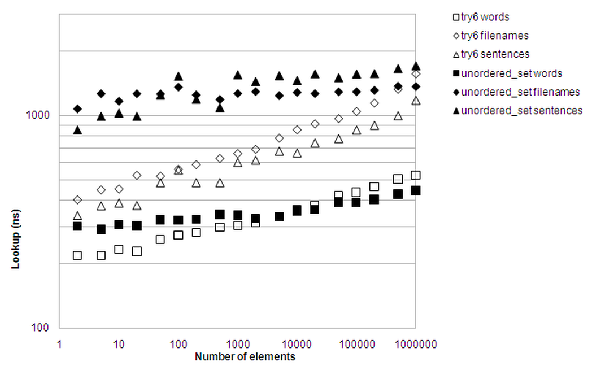
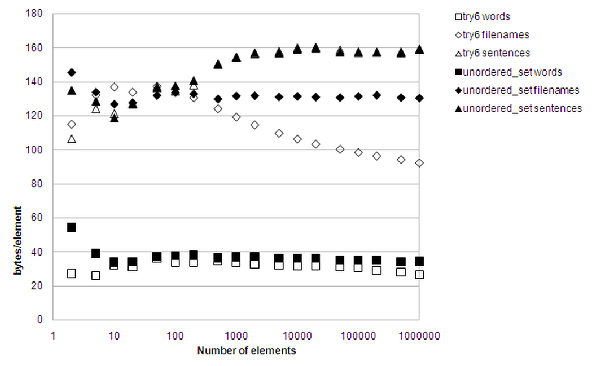
|
| Figure 12 |
Inconclusion
I would have liked to end this with a final conclusion about how to squeeze the last cycle out of the Trie, but alas summer vacation ended, and with it the available tinkering time.
Some observations, though, with thoughts for further studies:
- Can a different struct layout improve cache hits further?
- The remainder hash function causes an allocation of roughly 3 times as many nodes as needed. The mask hash function results in nearly 6 times as many nodes as needed. Is it possible to find a hash function that has the speed of the mask operation while providing better memory efficiency than the remainder operation?
- Can a hash-table implementation that allows collisions improve lookup performance? The collisions will cost, but if they are rare enough the improved locality of reference may generate a total performance gain.
- Can a global hash table for all nodes, instead of a local hash table for the children of each node, be more memory efficient without sacrificing lookup performance?
- The stored prefix strings are always perfectly aligned for the CPU. Can it be beneficial to compare the prefix and the searched for strings using the largest integer data type possible for the alignment, instead of always using char by char? Good built-in memcmp() implementations do this, but they cannot assume anything about the alignment for any of the strings, whereas an implementation that knows one of the strings is always perfectly aligned could be made a slight bit faster. For very short prefixes it would probably be a waste, but for long prefixes (e.g. filenames and URLs) it might speed up the processing. (Actually calling memcmp in attempt 6 with bit mask, causes a 16% slowdown for filenames, and 22% slowdown for words.)
- Can a custom allocator reduce heap fragmentation/overhead and thus improve the chances of cache hits and/or lessen the memory footprint?
- An attempt was made to store all long prefixes in a reference counted structure, to both save memory and increase the chance of cache-hits. It was a resounding failure except for very large collections of file names, where memory usage improved a bit while performance remained unchanged.
- Compiling the same program in 64-bit mode increases its memory consumption, since the larger pointers makes the node struct larger. The lookup performance is generally slightly worse than in 32-bit mode, probably because cache lines are evicted earlier.
One conclusion can be made, however - a Trie has indeed proven to be a very attractive data structure for string keys. It has been shown to beat hash tables in both lookup performance and memory consumption for a number of very real use cases.
References
[gutenberg] http://www.gutenberg.org
[HAT] http://crpit.com/confpapers/CRPITV62Askitis.pdf
[random] http://www.osadl.org/fileadmin/dam/presentations/RTLWS11/okech-inherent-randomness.pdf
[TRIE] http://en.wikipedia.org/wiki/Trie
[valgrind] http://www.valgrind.org
