








Over time projects tend to become hard to maintain. Alan Griffiths describes how one was improved.
I've been using C++ for a long time, at first because it was the principle language available for developing desktop applications on OS/2 and Windows. More recently it has been chosen either for non-technical reasons or because it provides better control over resources than other popular languages. As a result of this and the efforts of others like me the world is now full of functionally rich, slow to build, hard to maintain, C++ systems. Some of these have been developed over long periods of time by many and varied hands.
These C++ systems continue to exist because they provide valuable functionality to the organisations that own them. To maximise this value it is necessary to provide interfaces to today's popular application development languages, and make it possible to continue to develop them in a responsive and effective manner.
The need to work with other languages comes from the forces that change our industry: as computers and development tools have got more powerful we have tackled bigger and more complex problems. To facilitate tackling each part of the problem in the most effective way, it is common for different parts of the system to be built using different programming languages. In recent years the projects I've worked on have included C++ with combinations of Java, C#, Python and Javascript.
The project
The project that I'm going to describe used C++ for a mixture of reasons - the non-technical reason was that the codebase has been developed over a couple of decades, originally in 'C With Objects' but more recently, after a port, in C++. The technical reasons for choosing C++ were the usual 'control over resources' ones - principally CPU and memory. There are man-centuries invested in the codebase so a rewrite in a fashionable language would be hard to justify.
The code in question is a 'Quantitative Analytics Library' - it does the numeric analysis that underlies the trades done by an investment bank. This isn't the place to explain these trades and valuation methods in any detail (even if I could). Briefly, investment banks trade in a range of 'assets': futures of commodities, derivatives of stocks, currencies, bonds and indexes, and base their valuation on the available information (mostly historical pricing information).
An analytics library takes this data to assess the price needed to assure a likely profit from each trade. Among other things it builds multi-dimensional data structures of largely floating point numbers and processes these on a number of threads - small changes to layout and processing order can have big effects on performance. (And the resulting numbers!) Using C++ does indeed give some control over this - hence, while there are other plausible languages for this work, C++ remains a popular choice for such code.
There are a lot of applications in different areas of the bank that make use of this library to value the trades they are making. Most of the Linux based user applications are using Java, and most of the Windows ones are using C#. (It also exists as an Excel plugin - that's written entirely in C++.)
The codebase is monolithic - highly coupled, incohesive and with no agreed 'public interface', but it does have a suite of end-end tests that covers all the financial models supported in production and, at least in principle, any bug fixes do come with a corresponding test case.
The developers of these financial models are known as 'quants' (from 'quantitative analytics') and specialise in their domain knowledge rather than software engineering. I and a couple of other developers worked with them to redress this balance. (In this case the quants worked principally on Windows - of which more later.)
The library is supported on a range of platforms: primarily 32 bit Windows and 32 bit Linux, but 64 bit Linux is supported in development and planned for roll out later this year, and Win64 is under development - to be supported next year.
The legacy interface for users
Historically the users have been given a set of libraries (.sos or .dlls) and all the header files extracted from the codebase. Unsurprisingly the Java and C# users are not happy with this as the supported interface. Nor would any hypothetical C++ users be happy as things are forever changing (because there is no agreed public interface). It is also far from clear how a particular type of trade should be valued. Each application team therefore has to do work to map from its own representation of trades to the mechanics of configuring the corresponding analytic model for valuing it. (For example, it was the application team that constructed the correct choice of asset price and price volatility models for the trade.)
At some time in the past one such client group wrote a series of scripts to generate and build a Java interface to the library using SWIG [ SWIG ]. Other groups started using this interface and it is now shipped with the analytics library. This isn't ideal as, while there are multiple groups using this interface, there are no tests at all. Provided it compiles and links it will be shipped. When we started work the code wasn't even part of the main repository: it was a svn 'extern' to a repository owned by the group who once employed the original author - we didn't have commit access. (There was also a C# derivative of this work, but this will not be discussed separately.)
The lack of ownership of this SWIG interface generating code was particularly problematic as the same code was pulled in by all the active branches. (There are typically a couple of branches in production and another in development - but this can increase occasionally.) The main problems occur if changes on one of the branches necessitate changes to the generating code - which, as it has lots of special case handling for particular methods and constructors, happens. (In particular SWIG isn't able to expose the C++ distinctions between const, references, pointers and smart pointers - this can, and does, lead to unintended duplication of method signatures. There are some sed scripts to hide these problematic functions from SWIG.)
One of the first changes we made was to 'adopt' this code into our repository so that we could fix problems for each of the active branches independently. This wasn't entirely satisfactory as we still had no tests or access to the client code to check it compiled against the generated interface - the best we achieved was to ensure that the SWIG library compiled and linked then wait for users to 'shout'. (We could have done more to ensure the quality of these releases, but as we wanted people to move off this 'legacy interface', we felt we'd get better returns on time invested elsewhere.)
The new interface for users
As mentioned earlier, the legacy interface caused problems for our users. The interface didn't reflect normal Java (or C#) conventions, wasn't stable and reflected the need of the implementer, not the user. Each client application's developers needed to understand not only the trades they were valuing but also the correct way to value them. In addition, they needed to get 'sign-off' of the valuation models being produced for each trade type they implemented.
With these issues to contend with it could take over three months to get a new type of trade and valuation model into production. For competitive reasons the business wanted to move faster than this.
To address this we built a new, more stable, public interface that directly supports Java and C# and incorporates the mapping between a trade definition and the valuation models. Thus the client would supply the price and volatility data and our API would know the appropriate way to model these based on the information supplied about the trade. This would be much easier for client applications as the developers need only to present the trade (and market data) in an agreed format and don't need to be concerned with the method of valuation. This comprised a number of components (see figure 1):
- one that supports a uniform data representation (this can be thought of as a subset of JSON - as that is its serialised form);
- another that maps a trade representation to a model representation (by passing it to a library of Javascript functions that implement the mappings);
- a third that uses the modelling library to value the model (actually we introduced support for a second modelling library - so there were two of these);
- a fourth that manages all of this; and
- native C# and Java APIs that provide access to all of this.
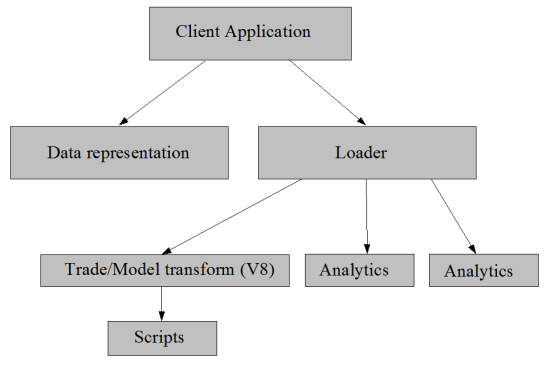
|
| Figure 1 |
Much of this is implemented in C++, but there are obviously bits of C# and Java and the mappings between trades and models is implemented in Javascript.
We address the lack of an idiomatic API by creating a C# API using properties for the data representation and IDisposable for resource management (so that 'using' blocks correctly managed C++ resources). The corresponding Java API was designed using setters and getters and a dispose() method. In both languages errors were represented by exceptions (one to say 'your input doesn't make sense' another to say 'that valuation failed').
Initially we implemented the C# API using 'Platform Invoke' and the Java API using 'JNA'. These are roughly equivalent technologies based on reflection that, given an interface coded in the corresponding language implements the calls to the native code at runtime. (There is a runtime cost to this, but it does provide a quick way to implement access to native code.) Given the large amounts of processing by the analytics library we didn't expect the performance to be an issue.
We later found that one of our client application teams using Java had two problems with this implementation. Firstly, they were doing a lot of fast running valuations and that for them performance was an issue and secondly, they were doing some fancy custom ClassLoader tricks and these clashed with similar practices in the JNA implementation - switching to a JNI implementation of our interface removed these difficulties.
The client interfaces have remained relatively stable over time. During the first six months there were binary interface changes, and through the first year there were tweaks to the trade definitions to approach a more uniform naming style (and to co-ordinate with a global initiative to represent trade elements in the same way throughout the business). All of that is settling down and work now focusses on reflecting changes and enhancements to the valuation engine and providing mappings for additional trade types.
Naturally, we introduced some 'acceptance tests' for the supported trade types that ensured that they were validated correctly. This greatly simplified the task of application developers who now only need to sign off that they were presenting us with correct trade representations (our tests established the correctness of the results for all the application teams).
As a measure of success a new type of trade was implemented by a client application in three weeks instead of the three months that would have previously been required. They were also able to ditch several hundred thousand lines of code when migrating code to the new interface. (Although, as they were also removing a massive tangle of Spring, that work must share some of the credit.)
Building integration and release
When I joined the project much of the effort was expended 'firefighting' the build and release process. There were a number of problems:
'Clever' use of CruiseControl
CruiseControl [ CruiseControl ] was used to manage continuous integration for the supported release branches and integration on the trunk. Something unusual was clearly going on as it was managing builds for both Windows and Linux. Instead of the more common email based reporting on builds summary results were being published to a 'chat' channel the developers subscribed to. Definitely not a 'vanilla' CruiseControl setup. It took a while to figure out what was going on!
With understanding, things were not as good as first appearances had suggested: it turned out that despite appearances and natural assumptions, CruiseControl didn't actually control either the checkouts or build processes directly. What CruiseControl treated as a build was actually a shell script that wrote a token file to a shared directory - another shell script on the corresponding target platform polled for these tokens and checked out the current source and built it. This then wrote the build results back to the share for the first script to pick up. The results were confusing as HEAD often changed between CC scanning the repository and the build script checking things out. The result of this inventiveness was:
- No reporting on regression tests
- Incorrect change reporting
- Poor error reporting
Something had to be done. But there were more issues to deal with than that.
The Linux build
Even with good code the Linux build failed about half the time - this turned out to be a parallelism issue, one make rule created a directory, another wrote to it and there was no dependency between them. Some very fragmented makefiles (lots of included fragments) made this hard to spot.
A less frequent cause of build failures was that the quants worked on Windows and the code checked in was not always good for Linux. Two problems we saw after any significant commit were that the case was wrong on #includes and that it was often necessary to add standard headers (for content that was implicitly supplied by others on Windows).
The Windows build
The Windows build was also in a mess. No-one quite knew why but the Windows 'Release' build configuration would fail if the Windows 'Debug' build configuration wasn't built first. However, apart from being needed to create the 'Release' build the 'Debug' build 'wasn't used'!
The quant developers worked with a more useful 'Debug(DLL)' build configuration that allowed components to be worked on independently - the 'Release' and 'Debug' builds produced a single DLL which took an age to link. The upshot of this was that the build server built three build configurations in succession 'Debug', 'Release' and finally 'Debug(DLL)'. There was also a 'Quantify' build configuration but no-one maintained it.
Building all these configurations took a few hours.
The release build process
The above describes the integration build. You might be forgiven for assuming that the release process was based on the same mechanism. You'd be wrong.
In order that the code released could be built from a label (yes, I know that Subversion allows you to label what you built afterwards) there was a pre-release build (with the same steps as the integration build) that would label the sourcecode for release if it succeeded. Again, HEAD would often change after the pre-release build was requested. (And, as the build failed randomly half the time, it often took several attempts to build before a label was applied - with the codebase evolving all the time.) Once a build had succeeded and a label applied another script would be started to build the software from the label. (As before the build failed half the time, but at least the code wasn't changing).
Once the release binaries had been created it was time to push the binaries out to the development and production environments. (You weren't thinking 'testing' were you? 'Fortunately' this system was a library for other teams applications to use, and they did need testing before releasing a version of their application to production using our release.)
Back to pushing out the binaries to the development and production environments. This was also problematic. Apart from the inevitable organisational change control forms that needed to be completed, there was a sequence of scripts to be run in sequence. The various shell and perl scripts involved were fragile. They had hidden hardcoded interdependencies, poor error checking, needed to be run as specific accounts, and no documentation.
Oh, and no version control. Not only did this mean that one had to track changes manually, it also meant that the same script was used for building a 'patch release' for a year old release branch as for the current version. This meant, for example, that adding components for the new interface wasn't just a matter of adding them to the scripts, but also surrounding these changes with tests for the versions in which they existed.
Slow and steady
Although these issues were a constant drain, fixing them was a background task - getting releases out consumed about one developer's productivity. On top of which there was the new library interface to be built. With a small team (two for a lot of the time) progress was slow.
Changing the build system was also time consuming - even with pairing to review changes, and trying to separate out bits that so that they could be tested independently, changes tended to break things in ways that were not detected until the next release was attempted.
But every time we fixed one of these problems life got easier. The race condition in the Makefile was the first fixed and made things a lot more predictable. Killing the dependency on 'Debug' and eliminating the 'Debug' and 'Quantify' build configurations also sped up integration and release builds. (In later days the 'Debug(DLL)' build was renamed 'Debug' to keep things simple.)
To fix the poor error reporting from integration we needed to build the version of the code that the CI tool was looking at. This could have been fixed with CruiseControl but, in practice, waited until we gained a team member with experience of TeamCity [ TeamCity ]. He replaced CruiseControl with TeamCity which has direct support for having 'build agents' on a variety of platforms and eliminated the scripting complexity used to achieve this with CruiseControl. (There are other continuous integration servers that might have served instead of TeamCity - Hudson [ Hudson ] is often suggested. Support for 'build agents' was one motivation for changing, another was the web interface for managing configuration which was a lot easier to learn than the XML files driving CruiseControl.)
TeamCity also integrates an artefact repository (in the past I've combined Ivy with CruiseControl to the same effect, but having it 'out of the box' was nice). This allowed us to eliminate the pre-release and release builds - our new release process (automated as Ant scripts run by TeamCity) took the binaries directly from the integration build, tagged the corresponding source revision in the repository, and then distributed the binaries to the development and production environments around the world.
It took around six months to address all the problems we'd seen initially and life was a lot easier - we could focus on the new library interface.
The benefits we saw
If integration was 'green' then a release could be requested of that code (and even if integration were broken, if a recent successful build contained the needed changes then that version could be released).
The build process was easy to change and enhance. We split out builds of separate components to give faster feedback.
We also added automated regression and validation tests as TeamCity 'build configurations' within the project. This was helpful to the application developers that were using our library through the 'new' interface - we had already generated much of the test evidence for the supported models.
Compared to the fragile collection of scripts we had been using copying build configurations in TeamCity is easy. This enabled us to set up parallel builds to test changes to compiler and library versions and extend support to 64bit Linux.
Copying projects in TeamCity is also easy - so when a stable release build was branched for maintenance it was easy to set up the integration build for it.
The ability to run multiple build agents meant that we could have a lot of building happening in parallel - which improved responsiveness to checkins.
Things were a lot more productive. Where a release once took a week and most of a developer's time it was now a few minutes of form filling (irreducible bureaucracy - although we did talk of scripting this) and a couple of button clicks. A couple of hours later the code was in production.
Conclusions
We managed to get buy-in from the management, clients and quants by being responsive to the current issues and regularly delivering incremental improvements (every week brought something visible). As releases became faster and more reliable, interfaces became cleaner and builds more reliable and faster, it became accepted that we could be trusted to fix the things brought to our attention.
What started as a slow to update component with a hard to use and unstable interface changed into a much more responsive and user friendly tool. The team and the client are happy with what we achieved and so are the client applications.
It is possible to make legacy C++ systems into projects fit for the third millennium!
References
[CruiseControl] http://cruisecontrol.sourceforge.net/
[Hudson] http://hudson-ci.org/
[SWIG] http://www.swig.org/
[TeamCity] http://www.jetbrains.com/teamcity/
