








Dealing with multi-threading is notoriously hard. Sergey Ignatchenko learns lessons from the past.
So the 'multi-core revolution' is finally here [ Merritt07 , Suess07 , Martin10 ] (some might argue that it has already been here for several years, but that's beyond the point now). Without arguing whether it is good or bad, we should agree that it is a reality which we cannot possibly change. The age of CPU frequency doubling every two years is long gone and we shouldn't expect any substantial frequency increases in the near future, and while there are still improvements in single-core performance unrelated to raw frequency increases, from now on we should count mostly on multiple cores to improve performance. Will it make development easier? Certainly not. Does it mean that everybody will need to deal with mutexes, atomics, in-memory transactions (both with optimistic and pessimistic locking), memory barriers, deadlocks, and the rest of the really scary multi-threading stuff, or switch to functional languages merely to deal with multi-threading? Not exactly, and we'll try to show it below. Please note that in this article we do not try to present anything substantially new, it is merely an analysis of existing (but unfortunately way too often overlooked) mechanisms and techniques.
How long is 'as long as possible'?
It is more or less commonly accepted that multi-threading is a thing which should be avoided for as long as it is possible. While writing multi-threaded code might not look too bad on the first glance, debugging it is a very different story. Because of the very nature of multi-threaded code, it is non-deterministic (i.e. its behavior can easily differ for every run), and as a result finding all the bugs in testing becomes unfeasible even if you know where to look and what exactly you want to test; in addition, code coverage metrics aren't too useful for evaluating coverage of possible race scenarios in multi-threaded code. To make things worse, even if the multi-threaded bug is reproducible, every time it will happen on a different iteration, so there is no way to restart the program and stop it a few steps before the bug; usually, step-by-step debugging offsets fragile race conditions, so it is rarely helpful for finding multi-threaded bugs. With post-mortem analysis of multi-threaded races using log files usually being impossible too, it leaves developer almost without any reliable means to debug multi-threaded code, making it more of a trial-and-error exercise based on 'gut feeling' without a real understanding what is really going on (until the bug is identified). Maintaining multi-threaded code is even worse: heavily multi-threaded code tends to be very rigid and fragile, and making any changes requires careful analysis and lots and lots of debugging, making any mix of frequently changed business logic with heavy multi-threading virtually suicidal (unless multi-threading and business logic are clearly separated into different levels of abstraction).
With all these (and many other) problems associated with multi-threaded code, it is easy to agree that multi-threading should be avoided. On the other hand, there is some disagreement on how long we can avoid it. In this article we will try to discuss how performance issues (if there are any) can be handled without going into too much detail of multi-threading. While not always possible, the number of cases when multi-threading can be avoided is extensive. And as discussed above whenever you can avoid it - you should avoid it, despite the potential fear that programs without multi-threading aren't 'cool' anymore. After all, the end-user (the guy who we all are working for) couldn't care less how many threads the program has or whether it utilizes all the available cores, as long as the program works correctly and is fast enough. In fact, using fewer cores is often beneficial for the end-user, so he's able to do something else at the same time; we also need to keep in mind that overhead incurred by multi-threading/multi-coring can be huge, and that Amdahl's Law provides only the theoretical maximum speedup from parallelization, with realized gains often being not even close to that. If a single-threaded program does something in a minute on one core, and multi-threaded one does the same thing in 55 seconds on 8 cores (which can easily happen if the granularity of context switching is suboptimal for any reason), it looks quite likely that user would prefer single-threaded program.
'No Multi-Threaded Bugs' Bunny & 'Multithreaded Gorrillazz'
Let us consider a developer who really hates dealing with those elusive multi-threading bugs. As he is our positive hero, we need to make him somewhat cute, so let's make him a bunny rabbit, with our hero becoming 'No Multi-Threaded Bugs' Bunny. And in opposition to him there is a whole bunch of reasons, which try to push him into heavy multi-threading with all the associated problems. Let's picture them as 'Multithreaded Gorrillazz' defending team. To win, our 'No MT Bugs' Bunny needs to rush through the whole field full of Gorrillazz, and score a touchdown. While it might seem hopeless, he has one advantage on his side: while extremely powerful and heavy, Gorrillazz are usually very slow, so in many cases he can escape them before they can reach him.
A few minor notes before the game starts: first of all, in this article we will address only programs which concentrate on interacting with the user one way or another (it can be a web, desktop, or mobile phone program, but interaction should be a substantial part of it). Scientific calculations/HPC/video rendering farms/etc. is a completely different game which is played on a very different field, so we will not discuss it here. Second important note is that we're making a distinction between 'a bit of multi-threaded code in a very limited number of isolated places' and 'massive multi-threading all over the code'. While the former can usually be managed with a limited effort and (given that there are no better options) we'll consider it as acceptable, the latter is exactly the thing we're aiming to avoid.
Houston, have we got a problem?
So, our 'No MT Bugs' Bunny is standing all alone against the whole field of fierce Gorrillazz. What is the first move he shall make? First of all, we need to see if he's writing client-side code or server-side code. In the first two quarters of the game, we will concentrate on client-side code, with server-side considered in the quarters 3&4 (coming in the next issue). And if the application is client-side, then the very first question for our hero is the following: does his application really experience any performance problems (in other words, would users actually care if the application runs faster)? If not, he can simply ignore all the Gorrillazz at least at the moment and stay single-threaded. And while Moore's law doesn't work any more for frequencies, and modern CPUs got stuck at measly 3-4GHz, it is still about 1000 times more than the frequency of the first PCs, which (despite a 1000-times-less-than-measly-3-4-GHz-modern-CPUs speed) were indeed able to do a thing or three. It is especially true if Bunny's application is a business-like one, with logic like 'if user clicks button 'ok', close this dialog and open dialog 'ZZZ' with field 'XXX' set to the appropriate value from previous dialog'; in cases like the last one, it is virtually impossible to imagine how such logic (taken alone, without something such as associated MP4 playing in one of the dialogs - we'll deal with such a scenario a bit later), can possibly require more than one modern core regardless of code size of this logic.
To block or not to block - there is no question
 If our 'No MT Bugs' Bunny does indeed have performance problems with his client application, then there is a big chance that it is related to I/O (if there are doubts, a profiler should be able to help clarify, although it's not always 100% obvious from the results of the profiling). If a user experiences delays while the CPU isn't loaded, the cause often has nothing to do with using more cores, or with CPU in general, but is all about I/O. While hard disk capacities went up tremendously in recent years, typical access time experienced much more modest improvements, and is still in the order of 10ms, or more than
ten to the seventh power
CPU clock cycles. No wonder, that if Bunny's program accesses the disk heavily the user can experience delays. Network access can incur even larger delays: while in a LAN typical round-trip time is normally within 1ms, typical transatlantic round-trip time is around 100-200ms, and that is only if everything on the way works perfectly; if something goes wrong, one can easily run into delays on the order of
seconds
(such as DNS timeout or a TCP retransmit), or even
minutes
(for example, the typical BGP convergence time [
Maennel02
]); the last number is about
eleven orders of magnitude
larger than the CPU clock time. As Garfield the Cat would have put it: 'Programmers who're blocking UI while waiting for network I/O, should be dragged out into the street and shot'.
If our 'No MT Bugs' Bunny does indeed have performance problems with his client application, then there is a big chance that it is related to I/O (if there are doubts, a profiler should be able to help clarify, although it's not always 100% obvious from the results of the profiling). If a user experiences delays while the CPU isn't loaded, the cause often has nothing to do with using more cores, or with CPU in general, but is all about I/O. While hard disk capacities went up tremendously in recent years, typical access time experienced much more modest improvements, and is still in the order of 10ms, or more than
ten to the seventh power
CPU clock cycles. No wonder, that if Bunny's program accesses the disk heavily the user can experience delays. Network access can incur even larger delays: while in a LAN typical round-trip time is normally within 1ms, typical transatlantic round-trip time is around 100-200ms, and that is only if everything on the way works perfectly; if something goes wrong, one can easily run into delays on the order of
seconds
(such as DNS timeout or a TCP retransmit), or even
minutes
(for example, the typical BGP convergence time [
Maennel02
]); the last number is about
eleven orders of magnitude
larger than the CPU clock time. As Garfield the Cat would have put it: 'Programmers who're blocking UI while waiting for network I/O, should be dragged out into the street and shot'.
The way to avoid I/O delays for the user without going into multi-threading has been well-known since at least 1970s, but unfortunately is rarely used in practice; it is non-blocking I/O. The concept itself is very simple: instead of telling the system 'get me this piece of information and wait until it's here', say 'start getting this piece of information, return control to me right away and let me know when you're done'. These days non-blocking I/O is almost universally supported (even the originally 100%-thread-oriented Java eventually gave up and started to support it), and even if it is not supported for some specific and usually rather exotic API function (such as FlushFileBuffers() on Windows), it is usually not that big problem for our Bunny to implement it himself via threads created specially for this purpose. While implementing non-blocking I/O himself via threads will involve some multithreaded coding, it is normally not too complicated, and most importantly it is still confined to one single place, without the need to spread it over all the rest of the code.
Non-blocking I/O vs heavy multi-threading
Unfortunately, doing things in parallel (using non-blocking I/O or via any other means) inherently has a few not-so-pleasant implications. In particular, it means that after the main thread has started I/O, an essentially new program state is created. It also means that program runs are not 100% deterministic anymore, and opens the potential for races (there can be differences in program behavior depending on at which point I/O has ended). Despite all of this, doing things in parallel within non-blocking I/O is still much more manageable than a generic heavily multi-threaded program with shared variables, mutexes etc. Compared to heavily multi-threaded approach, a program which is based on non-blocking I/O usually has fewer chances for races to occur, and step-by-step debugging has more chances to work. This happens because while there is some non-determinism in non-blocking I/O program, in this case a number of significantly different scenarios ('I/O has been completed earlier or later than certain other event') is usually orders of magnitude smaller than the potential number of different scenarios in a heavily multi-threaded program (where a context switch after every instruction can potentially cause substantially different scenarios and lead to a race). It can even be possible to perform a formal analysis of all substantially different scenarios due to different I/O timing, providing a theoretical proof of correctness (a similar proof is definitely not feasible for any heavily multi-threaded program which is more complicated than 'Hello, World!'). But the most important advantage of non-blocking I/O approach is that, with proper level of logging, it is possible to reconstruct the exact sequence of events which has led to the problem, and to identify the bug based on this information. This means we still have some regular way to identify bugs, not relying on trial-and-error (which can easily take years if we're trying to identify a problem which manifests itself only in production, and only once in a while); in addition, it also means that we can also perform post-mortem analysis in production environments.
 These improvements in code quality and debugging/testing efficiency don't come for free. While adding a single non-blocking I/O is usually simple, handling lots of them can require quite a substantial effort. There are two common ways of handling this complexity. One approach is event-driven programming, ubiquitous in the GUI programming world for user events; for non-blocking I/O it needs to be extended to include 'I/O has been completed' events. Another approach is to use finite state machines (which can vary in many aspects, including for example hierarchical state machines). We will not address the differences of these approaches here, instead mentioning that any such implementations will have all the debugging benefits described above.
These improvements in code quality and debugging/testing efficiency don't come for free. While adding a single non-blocking I/O is usually simple, handling lots of them can require quite a substantial effort. There are two common ways of handling this complexity. One approach is event-driven programming, ubiquitous in the GUI programming world for user events; for non-blocking I/O it needs to be extended to include 'I/O has been completed' events. Another approach is to use finite state machines (which can vary in many aspects, including for example hierarchical state machines). We will not address the differences of these approaches here, instead mentioning that any such implementations will have all the debugging benefits described above.
One common problem for both approaches above is that if our Bunny has lots of small pieces of I/O, making all of them non-blocking can be quite tedious. For example, if his program makes a long search in a file then, while the whole operation can be very long, it will consist of many smaller pieces of I/O and handling all associated states will be quite a piece of work. It is often very tempting to separate a whole bunch of micro-I/Os into a single macro-operation to simplify coding. This approach often works pretty well, but only as long as two conditions are met: (a) the whole such operation is treated as similar to a kind of large custom non-blocking I/O; (b) until the macro-operation is completed, there is absolutely no interaction between this macro-operation and the main thread, except for the ability to cancel this macro-operation from the main thread. Fortunately, usually these two conditions can be met, but as soon as there is at least some interaction added, this approach won't work anymore and will need to be reconsidered (for example, by splitting this big macro-operation into two non-blocking I/O operations at the place of interaction, or by introducing some kind of message-based interaction between I/O operation and main thread; normally it is not too difficult, though if the interaction is extensive it can become rather tedious).
Still, despite all the associated complexities, one of those approaches, namely event-driven approach, has an excellent record of success, at least in GUI programming (it will be quite difficult to find a GUI framework which isn't event-driven at least to a certain extent).
If it walks like a duck, swims like a duck, and quacks like a duck...
If after escaping 'Long I/O' Gorrilla, Bunny's client-side program is still not working as fast as the user would like, then there are chances that it is indeed related to the lack of CPU power of a single core. Let's come back to our earlier example with business-like dialogs, but now let's assume that somewhere in one of the dialogs there is an MP4 playing (we won't ask why it's necessary, maybe because a manager has said it's cute, or maybe marketing has found it increases sales; our Bunny just needs to implement it). If Bunny would call a synchronous function play_mp4() at the point of creating the dialog, it would stop the program from going any further before the MP4 ends. To deal with the problem, he clearly needs some kind of asynchronous solution.
Let's think about it a bit. What we need is a way to start rendering, wait for it to end, and to be able to cancel it when necessary... Wait, but this is exactly what non-blocking I/O is all about! If so, what prevents our Bunny from representing this MP4 playback as a yet another kind of non-blocking I/O (and in fact, it is a non-blocking output, just using the screen instead of a file as an output device)? As soon as we can call start_playing_mp4_and_notify_us_when_you_re_done() , we can safely consider MP4 playback as a custom non-blocking I/O operation, just as our custom file-search operation we've discussed above. There might be a multi-threaded wrapper needed to wrap play_mp4() into a non-blocking API, but as it needs to be done only once: multi-threading still stays restricted to a very limited number of places. The very same approach will also cover lots of situations where heavy calculations are necessary within the client. How to optimize calculations (or MP4 playback) to split themselves over multiple cores is another story, and if our Bunny is writing yet another video codec, he still has more Gorrillazz to deal with (with chances remaining that one of them will get him).
Single-thread: back to the future
 If our 'No MT Bugs' Bunny has managed to write a client-side program which relies on its main GUI thread as a main loop, and treats everything else as non-blocking I/O, he can afford to know absolutely nothing about threads, mutexes and other scary stuff, making the program from his point of view essentially a single-threaded program (while there might be threads in the background, our Bunny doesn't actually need to know about them to do his job). Some may argue that in 2010 going single-threaded might sound 'way too 1990-ish' (or even 'way too 1970-ish'). On the other hand, our single-thread with non-blocking I/O is not exactly the single-thread of linear programs of K&R times. Instead, we can consider it a result of taking into account the strengths and weaknesses of both previous approaches (classical single-threaded and classical heavily multi-threaded) and taking a small step further, trying to address the issues specific to both of them. In some very wide sense, we can even consider single-thread
→
multi-thread
→
single-thread-with-nonblocking-I/O transition, similar to Hegelian bud
→
blossom
→
fruit [
Hegel1807
]. In practice, architectures based on non-blocking I/O are usually more straightforward, can be understood more easily, and most importantly, are by orders of magnitude easier to test and debug than their heavily multi-threaded counterparts.
If our 'No MT Bugs' Bunny has managed to write a client-side program which relies on its main GUI thread as a main loop, and treats everything else as non-blocking I/O, he can afford to know absolutely nothing about threads, mutexes and other scary stuff, making the program from his point of view essentially a single-threaded program (while there might be threads in the background, our Bunny doesn't actually need to know about them to do his job). Some may argue that in 2010 going single-threaded might sound 'way too 1990-ish' (or even 'way too 1970-ish'). On the other hand, our single-thread with non-blocking I/O is not exactly the single-thread of linear programs of K&R times. Instead, we can consider it a result of taking into account the strengths and weaknesses of both previous approaches (classical single-threaded and classical heavily multi-threaded) and taking a small step further, trying to address the issues specific to both of them. In some very wide sense, we can even consider single-thread
→
multi-thread
→
single-thread-with-nonblocking-I/O transition, similar to Hegelian bud
→
blossom
→
fruit [
Hegel1807
]. In practice, architectures based on non-blocking I/O are usually more straightforward, can be understood more easily, and most importantly, are by orders of magnitude easier to test and debug than their heavily multi-threaded counterparts.
Last-second attempt
Our 'No MT Bugs' Bunny has already got far across the client side of the field, but if he hasn't scored his touchdown yet, he now faces the mightiest of remaining Gorrillazz, and unfortunately he has almost no room to maneuver. Still, there is one more chance for him to escape the horrible fate of heavily multi-threaded programming. It is good old algorithm optimization. While a speed up of a few percent might not be enough to keep you single threaded, certain major kinds of optimizations might make all the multi-threading (and multi-coring) unnecessary (unless, of course, you're afraid that a program without multi-core support won't look 'cool' anymore, regardless of its speed). If our Bunny's bottleneck is a bubble sort on a 10M element array, or if he's looking for primes by checking every number N by dividing it by every number in 3..sqrt(N) range [ Pentax Q Review ], there are significant chances that he doesn't really need any multi-coring, but just needs a better algorithm. Of course, your code obviously doesn't have any dreadfully inefficient stuff, but maybe it's still worth another look just to be 100% sure? What about that repeated linear scan of a million-element list? And when was the last time when you ran a profiler over your program?
Being gotcha-ed
Unfortunately, if our Bunny hasn't scored his touchdown yet, he's not too likely to score it anymore. He's been gotcha-ed by one of the Multithreaded Gorrillazz, and multi-threading seems inevitable for him. If such a situation arises, some developers may consider themselves lucky that they will need to write multi-threaded programs, some will hate the very thought of it; it is just a matter of personal preference. What is clear though is that (even if everything is done properly) it will be quite a piece of work, and more than a fair share of bugs to deal with.
Tools like OpenMP or TBB won't provide too much help in this regard: while they indeed make thread and mutex creation much easier and hide the details of inter-thread communication, it is not thread creation but thread synchronization which causes most of the problems with multi-threaded code; while OpenMP provides certain tools to help detecting race conditions a bit earlier, the resulting code will still remain very rigid and fragile, and will still be extremely difficult to test and debug, especially in production environments
Quarter 1&2 summary
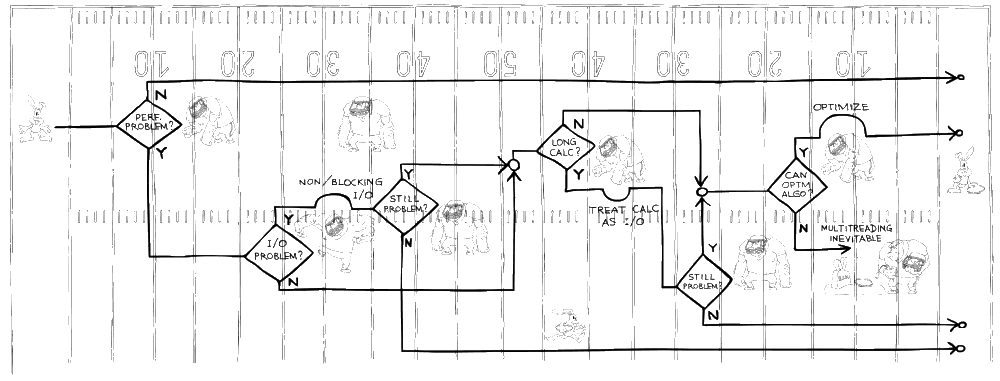
While we have seen that our Bunny didn't score a touchdown every time, he still did pretty well. As we can see, he has scored 4 times, and has been gotcha-ed only once. The first half of the game has ended with a score of 'No Multi-Threaded Bugs' Bunny: 4 to 'Multithreaded Gorrillazz': 1. Stay tuned for remaining two quarters of this exciting match.

References
[Blair-Chappell10] How to become a parallel programming expert in 9 minutes, Stephen Blair-Chappell, ACCU conference, 2010
[Hegel1807] Phenomenology of Spirit, Hegel, 1807, translation by Terry Pinkard, 2008
[Maennel02] Realistic BGP traffic for test labs, Olaf Maennel, Anja Feldmann, ACM SIGCOMM Computer Communication Review, 2002
[Martin10] The Language Stew, Robert Martin, ACCU Conference, 2010
[Merritt07] M'soft: Parallel programming model 10 years off, Rick Merritt, 2007, http://www.eetimes.com/showArticle.jhtml?articleID=201200019
[Suess07] Is the Multi-Core Revolution a Hype?, Michael Suess, 2007, http://www.thinkingparallel.com/2007/08/21/is-the-multi-core-revolution-a-hype/
