








Do you have a proper methodology when fixing bugs? Rafael Jay puts on his lab coat.
Bugs are a perennial part of the software development process. Despite our careful coding, our test-driven development, our peer reviews and our rigorous QA procedures, every release of more than a few lines of software seems inevitably to bring a swarm of bugs scuttling angrily behind it.
Much of the time it's reasonably easy to track down a bug. If you know which bit of code implements the troublesome behaviour you just take a look, prod a bit, and see what the problem is. I recall many years ago receiving a bug report that a particular script operation didn't seem to work. When I opened the offending source file it simply consisted of a comment, " TODO: implement ". However not all bugs are this easy to diagnose. At the other end of the scale there are those that keep you scratching your head for days or weeks, feeling increasingly stupid at your inability to make the software - on which you are allegedly an expert - confess its misdemeanours. Or those which cause a live customer incident, where the chances of going home rapidly recede and you barely get time to think between managers importuning you for status updates. It's with these kinds of bug that I think the scientific method can be useful.
The scientific method is a process for answering questions about how the universe works. Why do the planets move through the night sky? Why do apples always fall towards the ground? Why can't I go to the pub every night while maintaining my perfect physique? It starts from observable reality and tries to construct a model which answers these questions.
We don't use it much in software development because mostly we already know the answers. Why does my application save to disk when I press Ctrl+S? Because that's what I told it to do. A physicist looking at the night sky cannot directly perceive the laws that govern the universe. But a developer looking at a running application can. In fact they're visible with automatic syntax highlighting in her favourite IDE.
As developers we actually frame the laws that govern how our applications - our universes - work. This means our mental models of how they work, and what we believe they will do in any given situation, are usually pretty accurate. The instances where this is not so are generally what we call bugs: our mental model tells us that our application should behave in one way, but in fact it behaves in another. Instead of saving to disk it wipes the hard drive. To fix the bug we need to find out why, and this is where scientific method can help.
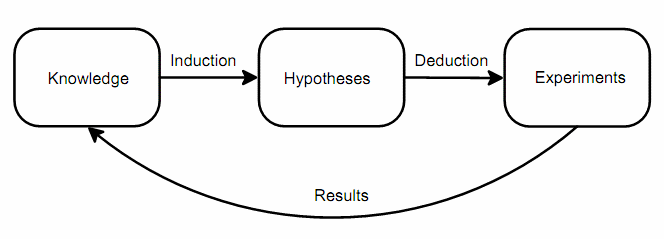
The scientific method starts from what we already know, constructs hypotheses about what might be true based on that knowledge, then conducts experiments to prove or disprove the hypotheses. This yields fresh knowledge and the cycle repeats until we've answered our question.
Figure 1 shows the components of the scientific method. Let's look at each of them in turn.
|
| Figure 1 |
Knowledge
Sherlock Holmes once remarked that from a drop of water, a logician could infer the possibility of an Atlantic or a Niagara without having seen or heard of one or the other [ Doyle ]. But before said logician can do so, he must notice the drop.
I was once stumped for over a year by a bug that had caused CPUs to spin wildly for no apparent reason. Then one day I happened to notice that the system uptime just before the bug was very close to 4294967296, or 2 32 . You can guess the rest - a classic 32-bit integer overflow bug. I hadn't spotted it previously because system uptime is reported in the system log once a day, at midday. The bug had occurred some hours after midday. So I didn't think to look. But like the drop of water, that piece of information was sitting there all along, waiting for someone to notice it and infer the CPU Niagara.
I now keep a checklist of possible information sources to consult when a tricky bug comes in. This helps me avoid missing key pieces of information. Some of these sources are specific to the products I work on, but some apply to the operating system or even just to software engineering in general. For example it's often a good idea to get a direct account of what happened from the people most directly involved, rather than relying on the circuitous word of mouth that can intervene between a live issue and a developer being summoned.
As you gather together what you know about a bug, it's a good idea to collect it in one place and keep it clearly labelled. This is especially so if more than one person is working on the bug, but even if it's just you it can get difficult to remember where each cryptically labelled crash dump file actually came from. I once wasted hours on a customer-critical bug trying to figure out why two of us were seeing different results from the same database dump, only to eventually realize that we were looking at different dumps with similar filenames.
Differentiate between what you actually know and what you merely presuppose. I recall one bug where a script ran fine on its own but got stuck when it ran as part of a batch file. After much investigation I realized that the script was in fact running fine as part of the batch file as well. It was actually the next script in the batch that got stuck. However the log wasn't flushed regularly enough and this made it look like the problem was in the original script. I had presupposed that the problem was in the original script but all I actually knew was that the last log message from the batch run came from that script.
Over my career I have seen more bug-hunting time wasted by false presuppositions than any other cause. It is very easy to start out with what seems like a reasonable presupposition, such as that a bug must be in a particular module, and forget to re-evaluate the presupposition as you dive deeper and deeper into technical investigations. Every time you find yourself back at the Knowledge stage of the scientific method, you should check your presuppositions and ask whether they still make sense in the light of whatever experiments you've conducted and the fresh knowledge thereby acquired.
The presuppositions on which physical science is based actually shade off into some very philosophical regions. For example, scientists presuppose that a physical universe exists at all, and that we are not merely butterflies dreaming of being humans. Such considerations don't generally impinge on software engineers. Even if I'm a butterfly dreaming of coding C++, I still have to fix that bug or I'll be a butterfly dreaming of a P45. But there are some points worth bearing in mind. A trap I've sometimes fallen into is where the code I'm working on is not the code I'm running. For example I'm building a debug version but running the release version. This can be mystifying when your code changes seem to have no effect. The problem is essentially that you're observing the wrong universe. Similarly it's worth considering whether the tools you use to perceive your universe, such as debuggers or profilers, are actually giving you an accurate view. Although it's relatively rare, those tools can have bugs in them. More commonly, your own brain - your most essential tool - can deceive you. Many of us will have experienced the [ CardboardProgrammer ] phenomenon from time to time, where simply talking through a bug will reveal an 'obvious' discrepancy between what we perceived the code to be doing and the reality. This can be a particular problem with code you wrote yourself, where it's all too easy to see what you meant to write rather than what you actually wrote.
Induction
Induction is the process of building hypotheses from knowledge. It moves from the particular to the general, starting from the particular facts we know to be true and building more general theories about why those things might be happening. For example, the stars all seem to whiz around the Earth: perhaps the Earth is at the centre of the stars? The application only crashes when I've been using feature X : perhaps feature X is corrupting the heap?
Induction in physical science is often a long and arduous process, requiring years of painstaking observation before a flash of creative genius draws out the pattern in the data. It was a long time before anyone put together enough knowledge to show that the Earth went around the Sun rather than vice versa. Things are simpler in software because we can peek behind the physical reality (a running application) to see the laws (source code) that govern it. This means it is relatively easy to look at the symptoms of a bug and enumerate the possible things that could be causing it. Nevertheless, it's often worth having as many people as possible involved in the process, because overlooking one of those possible things can result in a lot of wasted time.
Hypotheses
A hypothesis is a theory about what could be causing the things you know to be happening. For example, you hypothesize that the hard disk is wiped when you press Ctrl+S because you've called the wrong function in your code. The goal of the induction process is to put together a set of hypotheses which is as complete as possible within your presupposed bounds; and then to assign probabilities to those hypotheses.
A complete hypothesis set is one which covers the entire range of possibilities, such that one of the hypotheses must be correct. For example, "either the Earth goes round the Sun or it doesn't" is a complete hypotheses set; whereas "either the Earth goes round the Sun or the Sun goes round the Earth" isn't. The latter ignores the possibility that neither Earth nor Sun goes round the other.
A hypotheses set can be too complete. For example: the hard disk is wiped because I've called the wrong function; or because I've written the function incorrectly; or because the operating system is broken; or because the compiler is broken; or because ninjas 1 sneak in and wipe the drive when I'm not looking; or in fact I am actually a butterfly dreaming of being a programmer and none of this is real. You can imagine an infinite number of outlandish hypotheses and the correspondingly infinite time that would be required to investigate them all (even assuming it were possible to do so). To avoid this, we make presuppositions, such as ruling out ninjas, to eliminate outlandish hypotheses.
To guide your bug investigation, you need to assign probabilities to each hypothesis. Is it more likely that you've called the wrong function or that the compiler is broken? The answer dictates which hypotheses you should investigate first, or in most depth. Experience is valuable here - both of programming in general and of your specific product. Sometimes you know that a particular module is flaky and more likely to be the source of issues than another. And one thing I've learned over the years is that the compiler is rarely broken. Third party software that is widely used in a variety of settings is much more likely to be working correctly than your own software. It's more probable that you haven't understood how to use it correctly. I've only ever encountered or heard tell of a handful of compiler bugs over the years, for example the Microsoft auto_ptr bug, which was widely documented online. If the compiler is broken, then chances are that someone else already knows about it. The same applies to widely-used third party libraries.
Deduction
Hypotheses need to be tested. It's no good hypothesising that the Earth goes around the Sun unless there's something you can do to prove it. Such proof comes from experiments. Deduction, or deductive logic, is the tool we use to devise experiments to prove or disprove particular hypotheses.
Deduction is the opposite of induction. It moves from the general to the particular. If the Earth is at the centre of the stars, then we ought to see Arcturus moving in a particular pattern. If feature X is causing a crash, we should see evidence of feature X being run before each crash. We deduce a specific prediction from the general principle; then we devise an experiment to see if the prediction is true.
Deductive logic is a substantial subject in its own right and I won't attempt to cover it at all thoroughly here. Indeed, we generally don't need anything more than a common-sense grasp of the rules of logic to get by in the world of software engineering. However I think it might be useful, by way of an example, to look at one of the more commonly applied rules of logic and consider the potential pitfalls when applied to bug hunting. It also gives an excuse for some Latin, which is always nice.
Modus ponendo ponens translates as 'the way that affirms by affirming' and is a simple argument form in logic. It is generally abbreviated to just modus ponens . It works as follows:
- If P is true, then Q is also true
- P is true
- Therefore Q is true
For example: if feature X is run, then message M is written to the log file; feature X is run; therefore message M is written to the log file.
You can see how this might be useful in devising an experiment to prove the hypothesis that feature X is causing a crash. We can apply modus ponens to deduce a testable proposition which will be true if feature X did indeed cause the crash - specifically that message M will appear in the log file before the point where the application crashes. If this is true then the hypothesis becomes more likely; if false, the hypothesis is false.
At this point it is important to beware of logical fallacies. These are where you incorrectly construct a logical argument such that its conclusions are not valid. For example, a common fallacy afflicting modus ponens is that of 'affirming the consequent', which essentially means confusing cause and effect:
- If P is true, then Q is also true
- Q is true
- Therefore P is true
This is obviously wrong when written as a bare logical argument. But in the real world it can be harder to catch. For example: if feature X is run, message M is written to the log file; message M is written to the log file; therefore feature X was run. This takes the evidence of a log file message as proof that feature X was run. But what if feature Y happens to write an identical message when it's run? In that case the evidence of the log file message does not prove that feature X was run. You could waste a lot of time investigating feature X under the delusion that it was actually run before the program crashed. It's worth taking a bit of time to check your deductive logic and confirm that your experiments actually prove or disprove what you think they do.
Experiments
Experiments are the things you actually do to learn more about what might be causing the bug. They prove or disprove your predictions; which in turn strengthens or weakens the hypotheses from which you deduced those predictions. An experiment can be something as quick as looking in a log file or as involved as writing a scaled down version of a complex system to see if you can reproduce a bug with less surrounding clutter.
This last point is important: experiments cost. When a critical or difficult-to-diagnose bug comes in, you don't have infinite resources. There are only so many people you can take away from their regular duties, and there is only so much time they can spend on a bug before it becomes too costly for your company, or you lose a customer because you couldn't fix the problem quickly enough. It's also much more satisfying to be the guy who turned that critical bug around in 24 hours than the guy who went mad through working late nights for three solid weeks and had to be talked out of the cupboard.
I find it can be worth thinking like a laboratory administrator in these situations. You have a research problem - diagnosing the bug. You have a laboratory equipped with various computing hardware and software engineering tools. You have staff. What's the cheapest and quickest way of diagnosing the bug?
The starting point is to focus on the most likely hypotheses. What experiments can you deduce to strengthen or refute them? How much will those experiments cost? If one is expensive, is there something cheaper you can do to get the same result? Just as when coming up with hypotheses, it's worth having as many people involved as possible when you come up with experiments.
A further consideration is whether you have the right equipment, the right staff, and the right materials on which to run your experiments. Some thought and even research in this area can pay dividends. On one bug I was investigating we had ruled out using a performance profiler because we felt it would take too long to set up and execute on the large application we were dealing with. But once we actually talked to an expert from another team it turned out we could get some results in less than half an hour. On another occasion I wasted a lot of time messing about with system clocks trying to diagnose a time-triggered bug before I realised there were third party utilities that could achieve the same effect much more easily.
It's also worth considering whether you can modify the data you're looking at to make experiments more efficient. When a customer reports a bug, one of the first things it's common to ask for is a complete dump of their database so you can try to reproduce the problem in-house. A perennial problem I've faced is that this can be a lot of data - gigabytes in some cases. Running experiments on gigabyte data sets can be very time consuming as your developer machine struggles under the heavy resource load. It's worth considering whether some time invested up-front in eliminating irrelevant data to get a smaller data set will be a good investment in terms of making subsequent experiments more efficient. It's also worth considering whether modifying the application you're experimenting on might be useful, for example adding some extra logging or inserting a sleep to flush out suspected threading problems. You need to exercise discretion here as changing the data or the code you're experimenting on can invalidate the experiments; but it can mean the difference between running an experiment every two minutes or every two hours.
Experiments yield new knowledge, and the scientific method cycles back to the beginning. If you're lucky your knowledge now includes the cause of the bug, at least with sufficient certainty to start putting together a fix. If not, you can go through the cycle again, using your new knowledge to focus more tightly on the most likely hypotheses. Repeat until solved. Or until you decide it's all too costly, brush the bug under the carpet, and keep your fingers crossed that it doesn't happen again. Sometimes, though rarely, that actually is the right business decision.
Conclusion
Most of the time in software engineering we don't need the full rigour of scientific method. Our privileged insight into the source code - the laws of our particular universes - actually makes an ad hoc 'prod it and see' approach more efficient. But for intractable or customer critical bugs I think it can be well worth applying scientific method more formally. Following a clearly defined process reduces the risk of forgetting or overlooking key pieces of information, and it provides a solid framework for deciding the best way to use the resources at your disposal. This can save a significant amount of time that might otherwise be wasted on blind alleys and missed opportunities, especially on those pressured occasions when customers are shouting down the phone and managers gesticulating behind your chair.
As a final thought, I think it is worth taking a step back and considering why the scientific method has proved so useful to humanity over the centuries. An important reason is the nature of the universe we live in. Our universe appears to be one in which a vast array of physical phenomena can be explained by a very small set of laws. This is sometimes referred to as the property of parsimony - the universe gets a lot done with a little. It means that when science uncovers some new underlying principle, that principle is generally pretty useful - it explains or predicts many observed phenomena, with many consequent practical applications. But there is no reason why the universe should be parsimonious. Every apple could fall towards the Earth for distinct reasons, rather than as the result of a general principle of gravity. Every atom could move according to its own unique rules of quantum electrodynamics. Such a universe would be tremendously more difficult than ours to study and understand and it is likely that humanity, if it came into existence at all, would never have figured out very much about how it all worked.
Does this remind you of code bases you've worked on? As software engineers we create universes - running applications governed by the laws enshrined in source code. How parsimonious are the software universes you create? Can a developer understand a lot about your application with a relatively small set of principles? Or does each module and class have its own unique conventions that have to be understood piecemeal? It is well worth considering these issues as you develop because they determine how tractable your application will be to scientific method, and thus whether you will be the guy who fixed that bug or the guy who locked himself in the cupboard.
References
[CardboardProgrammer] http://www.c2.com/cgi/wiki?CardboardProgrammer
[Doyle] A Study in Scarlet, Arthur Conan Doyle
1 For more information about ninjas, see http://www.realultimatepower.net
