








I consider myself something of a connoisseur of technical books. I pride myself on my small but expanding collection. Of course, an important part of maintaining a useful book collection is knowing what information your books contain, so you can find it when you need it. Though I often forget the details of a solution I read about, I remember where I saw it, and what the original problem was. My purpose in writing this piece is two-fold: to show you how I solved a particular problem, and to point you at the books I used along the way.
When I was given this task, some of the solution was already defined. There was an existing architecture with a client and server sending messages over TCP/IP. A requirement had arisen for an additional client interface for CGI processes. Since each CGI process is short-lived, creating a new socket connection in each process would be too expensive. So the idea was to route messages through a daemon that maintains a persistent connection to the server. Because the daemon can be located on the same Unix box as the CGI processes, the two can use an Interprocess Communication (IPC) mechanism with less overhead than sockets. This is where I started working from.
The first decision was to choose the exact IPC mechanism to use. Unix has several, including pipes, fifos, sockets, message queues, and shared memory. I ruled out pipes because they require a parent-child relationship between processes, which I did not have. Fifos, like pipes, are best suited for one-to-one communication, whereas I needed manyto- one. I had heard that message queues were unnecessarily complex and grandiose, so I was hesitant to use them. Shared memory, on the other hand, is basically a free-form medium, and I was pretty confident that it would be fast enough, so I started the implementation based on shared memory. [ 1 ] I'll walk you through the basics of my solution below.
Shared memory is what the name implies; it is a portion of address space that is shared between processes. Normally each process has its own address space, which is entirely separate from those of other processes. The operating system uses hardware to map a process's virtual address space onto physical memory. This ensures that no process can access memory in another process's address space; so no process can disturb the integrity of another. Shared memory is an exception to this system. When two processes attach the same shared memory segment, they are telling the operating system to relax the normal restrictions by mapping a portion of their address space onto the same memory.
The definitive book on Unix IPC is "UNIX Network Programming" by the late Richard Stevens [ Stevens ]. Anyone doing heavy Unix should be familiar with it. After consulting this authority, we see that getting access to shared memory is a two-step process. First, a shared memory identifier is obtained, using the shmget() system call. The segment is identified by an integer key, and has a set of permissions controlling which processes may read, write, or execute it, much like a Unix file. The IPC_CREAT and IPC_EXCL flags control creation of the segment if it doesn't exist. Once a segment is created, it is available for use by any process with appropriate permissions. After obtaining a segment identifier, a process must attach the segment into its address space using the shmat() call. The return from shmat() is the base address where the segment was attached, i.e., the address of the first byte located in the segment. The memory is now available for use just like any other memory in the process's address space. Here's an example:
#include <sys/shm.h>
int main() {
int id = shmget(0x1000 /*key*/,
sizeof(int) /*size*/,
0600 | IPC_CREAT /*creation flags*/);
void* base = shmat(id /*identifier*/,
0 /*base address*/, 0 /*flags*/);
*reinterpret_cast<int*>(base) = 42;
}
After the call to shmat() above, the process's address space might look as shown in Figure 1 below.

Figure 1. Address space after call to shmat()
The low-level C interface of shmget() [ 2 ] and shmat() , with their untyped integer handles and bit flags are just what you get with Unix system calls. Now I have great respect for Unix and C, but sometimes I want an interface with a little more structure...err...I mean class. So we'll wrap up some of the error-prone details in a C++ interface. Our first step in building a set of C++ classes to handle shared memory will be to encapsulate a shared memory segment:
class shm_segment {
public:
enum CreationMode { NoCreate, CreateOk, MustCreate, CreateOwned };
shm_segment(int key, CreationMode mode, int size=0, int perm=0600);
~shm_segment();
void* get_base() const;
unsigned long get_size() const;
void destroy();
private:
int key_;
int id_;
void* base_;
unsigned long size_;
bool owner_;
};
class shm_create_exception: public std::exception {
public:
const char* what() const throw() {
return "error creating shared memory segment";
}
};
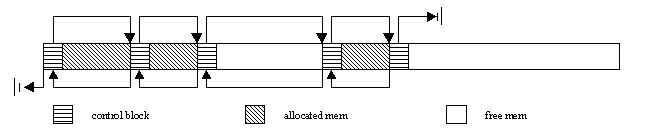
Figure 2. Allocating memory
This class simply wraps creation and destruction of a shared memory segment. The CreationMode argument determines whether the segment will be created if it doesn't exist. This corresponds to the meaningful combinations of the IPC_CREAT and IPC_EXCL flags. The CreateOwned option sets our owner_flag , which we'll use to determine if the shared memory segment should be removed when the shm_segment object is destroyed. It might be possible to store a reference count and remove the segment only after all processes are finished with it, but it's probably best to have a clear ownership policy instead. The implementation of shm_segment is straight forward.
The shm_segment class makes it a little easier to get a segment, but once it is created, there is still no internal structure to the segment; it's just a raw chunk of memory. In order to add more structure, we will need a way to store pointers inside the segment. But this poses a problem. Since each process may attach the segment at a different base address, a pointer into the segment created by one process may not be valid in another process; it may point somewhere else entirely. To solve this problem, we will store offsets from the base instead of raw pointers. We'll create a simple pointer class for this purpose:
template<typename T>
class shm_ptr {
public:
shm_ptr();
shm_ptr(T* rawptr, const shm_segment& seg);
// compiler generated copy constructor and
// assignment are ok
T* get(const shm_segment& seg) const;
void reset(T* rawptr, const shm_segment& seg);
private:
long offset_;
};
class shm_ptr_out_of_bounds: public std::exception {
public:
const char* what() const throw() {
return "shm_ptr cannot be created with address outside of segment";
}
};
Notice that the only data member is an integer representing the offset in bytes from the base address. This offset will have the same meaning for all the processes using our shared memory segment, so it can safely be stored in shared memory. Notice also that our interface requires the user to pass the shm_segment when accessing the pointer. This is somewhat cumbersome, but it yields a general design where each process may attach multiple shared memory segments. Alternatively, shm_segment could be a singleton, which would make it easier for shm_ptr to provide the usual indirection operators, but I found this unnecessary.
Our shm_ptr gives us a safe way to store a pointer in shared memory, but we don't yet have a way to create that pointer. It would be possible to choose arbitrary locations for data and manually place it there with some pointer arithmetic, e.g.,
shm_ptr<char> buffer(reinterpret_cast<char*>(mysegment.getBase()), mysegment); shm_ptr<char> buffer2(reinterpret_cast<char*>(mysegment.getBase())+1000, mysegment);
but I think we can all agree that this is too ugly and inflexible. What we really need is a way to allocate objects in shared memory with the ease of ordinary operators new and delete. To accomplish this, we'll write a shared memory allocator class:
struct shm_allocator_header;
class shm_allocator {
public:
explicit shm_allocator(const shm_segment& seg);
void* alloc(size_t nbytes);
void free(void* addr);
void* get_root_object() const;
void set_root_object(void* obj);
const shm_segment& get_segment() const;
private:
const shm_segment& seg_;
shm_allocator_header* header_;
};
The interface provides alloc() and free() methods, as well as methods to get and set a "root object." The root object gives us a fixed access point for processes to share objects. There is also a get_segment() method to find out what shared memory segment an allocator is using.
When I was writing my first implementation, and I knew I needed an allocator, I remembered seeing one somewhere, and after flipping through a few pages, I found Chapter 4 in "Modern C++ Design," which describes small object allocations [ Alexandrescu ]. [ 3 ] An example there gave me enough information to sketch out my initial implementation. The basic idea of an allocator is to store a control block in the memory preceding the address returned to the user. This example used:
struct MemControlBlock {
bool available_;
MemControlBlock* prev;
MemControlBlock* next;
}
Starting from a root block, you just walk down the list of blocks looking for one that's free and big enough for the requested allocation. The layout of memory looks as shown in Figure 2 above.
Incidentally, Alexandrescu mentions the many tradeoffs associated with memory allocators, and points us to Knuth's masterpiece for more details [ Knuth ]. For some variety, I decided to base our implementation on a section in "The C Programming Language" on implementing malloc() and free(); it is a little simpler to explain, and it gives me an opportunity to recognize a classic (and still relevant) book [ KandR ]. The idea for the allocator is the same, but the details have changed. Each block now stores its size and a pointer to the next block.
struct shm_allocator_block {
shm_ptr<shm_allocator_block> next;
size_t size;
};
A header block stores a pointer to the beginning of a linked list of free blocks:
struct shm_allocator_header {
shm_ptr<void> rootobj;
pthread_mutex_t lock;
shm_ptr<shm_allocator_block> freelist;
};
The free list is a singly-linked circular list of blocks not currently in use. The list is linked in order of ascending addresses to make it easy to combine adjacent free blocks. Here is the implementation of alloc().
void* shm_allocator::alloc(size_t nbytes) {
scoped_lock guard(&header_->lock);
size_t nunits = (nbytes + sizeof(shm_allocator_block) - 1) /
sizeof(shm_allocator_block) + 1;
shm_allocator_block* prev = header_->freelist.get(seg_);
shm_allocator_block* block = prev->next.get(seg_);
do {
if (block->size >= nunits) {
if (block->size == nunits)
prev->next = block->next;
else {
block->size -= nunits;
block += block->size;
block->size = nunits;
}
header_->freelist.reset(prev, seg_);
return (void*)(block+1);
}
prev = block;
block = block->next.get(seg_);
} while(block != header_->freelist.get(seg_));
return NULL;
}
The code above walks the free list looking for a block big enough to hold the requested number of bytes. If the block it finds is larger than needed, it splits it in two. Otherwise it returns it as is. If no block is found, it returns null. Size calculations are made in units equal to the size of one shm_allocator_block . This makes the pointer arithmetic a little simpler, and ensures that all memory allocated will have the same alignment as shm_allocator_block.
The implementation of free() is shown below:
void shm_allocator::free(void* addr) {
scoped_lock guard(&header_->lock);
shm_allocator_block* block = static_cast<shm_allocator_block*>(addr) - 1;
shm_allocator_block* pos = header_->freelist.get(seg_);
while (block > pos && block < pos->next.get(seg_)) {
if (pos >= pos->next.get(seg_) && (block > pos || block < pos->next.get(seg_)))
break;
pos = pos->next.get(seg_);
}
//try to combine with upper block
if (block + block->size == pos->next.get(seg_)) {
block->size += pos->next.get(seg_)->size;
block->next = pos->next.get(seg_)->next;
}
else
block->next = pos->next;
//try to combine with lower block
if (pos + pos->size == block) {
pos->size += block->size;
pos->next = block->next;
}
else
pos->next.reset(block, seg_);
header_->freelist.reset(pos, seg_);
}
The block is inserted into its correct spot in the free list (remember the list is sorted by address). Then we check for adjacent free blocks. If any are found, we combine them with the current block by just forgetting that the upper block exists and increasing the size of the lower block. So, after a few allocations and deallocations, memory might look as shown in Figure 3 below.

Figure 3. Memory after allocations and deallocations
We'll also overload operators new and delete to work with shm_allocator . The basic details for doing this, and some pitfalls can be found in Item 36 of "Exceptional C++" [ Sutter ].
void* operator new(size_t s, shm_allocator& a) {
return a.alloc(s);
}
void operator delete(void* p, shm_allocator& a) {
a.free(p);
}
We can overload new[] and delete[] similarly. The proper syntax for calling overloaded operator new or delete may be mysterious to you. Assuming we have already defined a class Message, we can create a new Message object in shared memory using:
Message* m = new (a) Message;
// a is a shm_allocator
The above is a new expression which calls our overloaded operator new , followed by the Message constructor. Destroying the Message object is not quite as simple:
m->~Message(); operator delete(m, a);
We must first make an explicit call to the destructor and then deallocate the memory. Two steps are required because there is no way to form a delete expression which calls an overloaded operator delete. You'll notice that the lines above are equivalent to these:
m->~Message(); a.free(m);
So, one might be tempted to overload only operator new; however, it is very important that we overload operator delete as well, because if the Message constructor throws an exception our overloaded operator delete will be automatically called. If there was no operator delete to match the operator new used to allocate the memory, bad things would happen.
We now have a general purpose allocator that we can use to help us build arbitrary structures in shared memory. To demonstrate its use, we'll write our final class, a producer-consumer queue in shared memory:
template<typename T> struct shm_queue_header;
template<typename T>
class shm_queue {
public:
shm_queue(shm_allocator& a, size_t maxsize);
~shm_queue();
void push(shm_ptr<T> obj);
shm_ptr<T> pop();
size_t size() const;
private:
const size_t MaxQueueSize;
shm_queue_header<T>* header_;
shm_allocator& a_;
const shm_segment& seg_;
// disallowed (not implemented)
shm_queue(const shm_queue& copy);
shm_queue& operator=(constshm_queue& rhs);
};
This is a basic queue, with simple push() and pop() methods. [ 4 ] The queue is created with a shm_allocator , which it then uses to allocate nodes. A maximum size is also specified to ensure that the producer(s) don't get too far ahead of the consumer(s). The implementation is a singly-linked list.
template<typename T>
struct shm_queue_node {
shm_ptr<T> data;
shm_ptr<shm_queue_node> next;
};
template<typename T>
struct shm_queue_header {
size_t size;
shm_ptr<shm_queue_node<T> > head;
shm_ptr<shm_queue_node<T> > tail;
pthread_mutex_t lock;
pthread_cond_t ready_for_push;
pthread_cond_t ready_for_pop;
};
Now, those pthread_xxx members give me a chance to make my final recommendation: "Programming with POSIX Threads" by David Butenhof [ Butenhof ]. This is an excellent introduction to threaded programming, and specifically, Pthreads. "But wait a minute!" you say, "When did we introduce threads into the picture?" Well, the primitives needed to synchronize two threads (which inherently share memory) are very similar to those needed to synchronize processes using Unix shared memory. They are so similar, in fact, that Pthreads provides a way to use mutexes and condition variables in this scenario. If your system defines the _POSIX_THREAD_PROCESS_SHARED macro, you can place Pthread objects in shared memory if you set the pthread_process_shared attribute. This works on the Solaris system I tested on, but is not supported on my Linux system. [ 5 ]
For a little more demonstration of Pthreads, here's the implementation of our scoped_lock class:
#include <pthread.h>
class scoped_lock {
public:
scoped_lock(pthread_mutex_t* mutex) {
mutex_ = mutex;
pthread_mutex_lock(mutex_);
}
~scoped_lock() {
pthread_mutex_unlock(mutex_);
}
void wait(pthread_cond_t* cond) {
pthread_cond_wait(cond, mutex_);
}
private:
pthread_mutex_t* mutex_;
scoped_lock(const scoped_lock& copy);
scoped_lock& operator=(const scoped_lock& rhs);
};
And, using scoped_lock , the implementation of shm_queue::push() :
template<typename T>
void shm_queue<T>::push(shm_ptr<T> obj) {
scoped_lock guard(&header_->lock);
while (header_->size > MaxQueueSize) {
guard.wait(&header_->ready_for_push);
}
shm_queue_node<T>* node = new (a_) shm_queue_node<T>;
node->data = obj;
node->next.reset(0, seg_);
if (header_->head.get(seg_) != 0) {
header_->head.get(seg_)->next.reset(node, seg_);
}
else {
header_->tail.reset(node, seg_);
}
header_->head.reset(node, seg_);
++header_->size;
pthread_cond_signal(&header_->ready_for_pop);
}
Finally, we'll write a simple producer and consumer which use shm_queue :
struct Message {
int sequence_num;
shm_ptr<char> message;
};
// main routine for producer
int main(int argc, char*argv[]) {
shm_segment seg(30000, shm_segment::CreateOwned, 1000000);
shm_allocator a(seg);
shm_queue<Message> q(a);
int message_count = 0;
while (true) {
std::cout << "enter a message: "
<< std::flush;
std::string line;
std::getline(std::cin, line);
Message* m = new (a) Message;
m->sequence_num = message_count++;
m->message.reset(static_cast<char*>(a.alloc(line.size()+1)), seg);
strcpy(m->message.get(seg), line.c_str());
q.push(shm_ptr<Message>(m, seg));
}
}
// main routine for consumer
int main(int argc, char*argv[]) {
shm_segment seg(30000, shm_segment::NoCreate);
shm_allocator a(seg);
shm_queue<Message> q(a);
while (true) {
shm_ptr<Message> p = q.pop();
Message* m = p.get(seg);
std::cout << "Message "
<< m->sequence_num
<< " "
<< m->message.get(seg)
<< "\n";
a.free(m->message.get(seg));
m->~Message();
operator delete(m, a);
}
}
There you have it: a way to access shared memory, allocate objects in it, and pass them on a queue. So keep up with your reading, and pay attention to the ACCU book reviews [ BookRev ]!
Acknowledgements
Special thanks to Satish Kalipatnapu and Thad Frogley for the valuable comments they provided on drafts of this article. Any errors that remain are mine alone.
References
[Stevens] W. Richard Stevens: UNIX Network Programming, Volume 2: Interprocess Communications , Prentice Hall, 1998, ISBN 0-130-81081-9.
[Alexandrescu] Andrei Alexandrescu: Modern C++ Design: Generic Programming and Design Patterns Applied , Addison-Wesley, 2000, ISBN 0-201-70431-5.
[Knuth] Donald E. Knuth: The Art of Computer Programming , Addison-Wesley, 1998, ISBN 0-201-48541-9
[KandR] Brian W. Kernighan and Dennis M. Ritchie: The C Programming Language , Prentice Hall, 1988, ISBN 0-131-10362-8.
[Sutter] Herb Sutter: Exceptional C++: 47 Engineering Puzzles, Programming Problems, and Solutions , Addison-Wesley, 2000, ISBN 0-201-61562-2.
[Butenhof] David R. Butenhof: Programming with POSIX Threads , Addison-Wesley, 1997, ISBN 0-201-63392-2.
[BookRev] http://www.accu.org/bookreviews/public/index.htm
[ 1 ] Actually, I also had some prior experience using shared memory, so this may just be a case of everything looking like a nail when all you have is a hammer.
[ 2 ] Some people insist that all Unix system calls can be pronounced as they are written, no matter how vowel-deficient they may be.
[ 3 ] Unfortunately, the small object allocator in Loki (the C++ library developed in [ Alexandrescu ]) appears to have a few unresolved implementation issues. If you choose to use it, you may learn more than you ever wanted about allocators. However, this does not detract from the value of "Modern C++ Design" itself.
[ 4 ] Item 10 in [ Sutter ] warns against returning objects in pop() methods. However, in this case, it is not necessary to provide separate top() and pop() methods; since we only store pointers the pop() operation cannot throw an exception while copying the return value.
[ 5 ] An alternative synchronization method is to use Unix semaphores instead of mutexes and condition variables (semaphores can simulate either). I presented Pthreads here because it is cleaner both conceptually and for implementation.
